Юникод
Юнико́д[1] (чаще всего) или Унико́д[2] (англ. Unicode) — стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира[3]. В настоящее время стандарт является преобладающим в Интернете.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет способы преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
Предпосылки создания и развитие Юникода
Unicode — это уникальный код для любого символа, независимо от платформы, независимо от программы, независимо от языка.Консорциум Юникода[9]
К концу 1980-х годов стандартом стали 8-битные кодировки, их существовало уже большое множество, и постоянно появлялись новые. Это объяснялось как расширением круга поддерживаемых языков, так и стремлением создавать кодировки, частично совместимые между собой (характерный пример — появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437). В результате появилось несколько проблем:
- проблема неправильной раскодировки;
- проблема ограниченности набора символов;
- проблема преобразования одной кодировки в другую;
- проблема дублирования шрифтов.
Проблема неправильной раскодировки вызывала появление в документе символов иностранных языков, не предполагавшихся в документе, или появление не предполагавшихся псевдографических символов, прозванных русскоязычными пользователями «кракозябрами». Проблема во многом была вызвана отсутствием стандартизированной формы указания кодировки для файла или потока. Проблему можно было решить либо последовательным внедрением стандарта указания кодировки, либо внедрением общей для всех языков кодировки.[6]
Проблема ограниченности набора символов[6]. Проблему можно было решить либо переключением шрифтов внутри документа, либо внедрением «широкой» кодировки. Переключение шрифтов издавна практиковалось в текстовых процессорах, причём часто использовались шрифты с нестандартной кодировкой, т. н. «dingbat fonts». В итоге при попытке переноса документа в другую систему все нестандартные символы превращались в «кракозябры».
Проблема преобразования одной кодировки в другую. Проблему можно было решить либо составлением таблиц перекодировки для каждой пары кодировок, либо использованием промежуточного преобразования в третью кодировку, включающую все символы всех кодировок[10].
Проблема дублирования шрифтов. Для каждой кодировки создавался свой шрифт, даже если наборы символов в кодировках совпадали частично или полностью. Проблему можно было решить путём создания «больших» шрифтов, из которых впоследствии выбирались бы нужные для данной кодировки символы. Однако это требовало создания единого реестра символов, чтобы определять, чему что соответствует.
Была признана необходимость создания единой «широкой» кодировки. Кодировки с переменной длиной символа, широко использующиеся в Восточной Азии, были признаны слишком сложными в использовании, поэтому было решено использовать символы фиксированной ширины. Использование 32-битных символов казалось слишком расточительным, поэтому было решено использовать 16-битные.
Первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 216 (65 536). С тех пор символы стали обозначать четырьмя шестнадцатеричными цифрами (например, U+04F0). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе. Редко используемые символы должны были размещаться в «области пользовательских символов» (private use area), которая первоначально занимала коды U+D800…U+F8FF. Чтобы использовать Юникод также и в качестве промежуточного звена при преобразовании разных кодировок друг в друга, в него включили все символы, представленные во всех наиболее известных кодировках.
В дальнейшем, однако, было принято решение кодировать все символы и в связи с этим значительно расширить кодовую область. Одновременно с этим коды символов стали рассматриваться не как 16-битные значения, а как абстрактные числа, которые в компьютере могут представляться множеством разных способов (см. способы представления).
Поскольку в ряде компьютерных систем (например, Windows NT[11]) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая англ. Basic Multilingual Plane, BMP). Остальное пространство используется для «дополнительных символов» (англ. supplementary characters): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16, где первые 65 536 позиций, за исключением позиций из интервала U+D800…U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), отведённого «для частного использования».
Поскольку в UTF-16 можно отобразить только 220+216−2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода (диапазон кодов: 0x000000-0x10FFFF).
Хотя кодовая область Юникода была расширена за пределы 216 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
Роль этой кодировки в веб-секторе постоянно растёт. На начало 2010 доля веб-сайтов, использующих Юникод, составила около 50 %[12].
Версии Юникода
Работа по доработке стандарта продолжается. Новые версии выпускаются по мере изменения и пополнения таблиц символов. Параллельно выпускаются новые документы ISO/IEC 10646.
Первый стандарт выпущен в 1991 году, последний на данный момент — в 2020. Версии стандарта 1.0—5.0 публиковались как книги и имеют ISBN[13][14].
Номер версии стандарта составлен из трёх цифр (например, 3.1.1). Третью цифру меняют при внесении в стандарт небольших изменений, не добавляющих новых символов (исключение — версия 1.0.1, в которой добавлены унифицированные идеограммы китайского, японского и корейского письма)[15].
База данных символов Юникода (Unicode Character Database) доступна для всех версий на официальном сайте как в простом текстовом, так и в XML-формате. Файлы распространяются под BSD-подобной лицензией.

| Номер версии | Дата публикации | ISBN книги | Издание ISO/IEC 10646 | Количество письменностей | Количество символов[A 1] | Изменения |
|---|---|---|---|---|---|---|
| 1.0.0[16] | Октябрь 1991 | ISBN 0-201-56788-1 (Vol.1) | 24 | 7161 | Изначально Юникод содержал символы следующих письменностей: арабское письмо, армянское письмо, бенгальское письмо, чжуиньское письмо, кириллица, деванагари, грузинское письмо, греческое и коптское письмо, гуджарати, гурмукхи, хангыль, еврейское письмо, хирагана, каннада, катакана, лаосское письмо, латиница, малаялам, ория, тамильское письмо, телугу, тайское письмо и тибетское письмо[17] | |
| 1.0.1 | Июнь 1992 | ISBN 0-201-60845-6 (Vol.2) | 25 | 28 359 | Добавлены 20 902 унифицированные идеограммы китайского, японского и корейского письма[18] | |
| 1.1[19] | Июнь 1993 | ISO/IEC 10646-1:1993 | 24 | 34 233 | Добавлено 4306 слогов хангыля, дополнивших уже имеющиеся в кодировке 2350 символов. Удалены символы тибетского письма[20] | |
| 2.0[21] | Июль 1996 | ISBN 0-201-48345-9 | ISO/IEC 10646-1:1993 и Amendments 5, 6, 7 | 25 | 38 950 | Удалены добавленные ранее слоги хангыля, и добавлены 11 172 новых слога хангыля с новыми кодами. Возвращены удалённые ранее символы тибетского письма; символы получили новые коды и были размещены в разных таблицах. Введён механизм суррогатных (англ. surrogate) символов. Выделено место для плоскостей (англ. planes) 15 и 16[22] |
| 2.1[23] | Май 1998 | ISO/IEC 10646-1:1993, Amendments 5, 6, 7, два символа из Amendment 18 | 25 | 38 952 | Добавлены символ евро и заменяющий символ[24] | |
| 3.0[25] | Сентябрь 1999 | ISBN 0-201-61633-5 | ISO/IEC 10646-1:2000 | 38 | 49 259 | Добавлены письмо чероки, эфиопское письмо, кхмерское письмо, монгольские письменности, бирманское письмо, огамическое письмо, руны, сингальское письмо, сирийское письмо, тана, канадское слоговое письмо и письмо и, а также символы шрифта Брайля[26] |
| 3.1[27] | Март 2001 | ISO/IEC 10646-1:2000
ISO/IEC 10646-2:2001 |
41 | 94 205 | Добавлены дезеретское письмо, готское письмо и древнеиталийское письмо, а также символы западной и византийской музыки, 42 711 унифицированных идеограмм китайского, японского и корейского письма. Выделено место для плоскостей 1, 2 и 14[28] | |
| 3.2[29] | Март 2002 | ISO/IEC 10646-1:2000 и Amendment 1
ISO/IEC 10646-2:2001 |
45 | 95 221 | Добавлены письмо бухид, хануноо, байбайин и письмо тагбанва[30] | |
| 4.0[31] | Апрель 2003 | ISBN 0-321-18578-1 | ISO/IEC 10646:2003 | 52 | 96 447 | Добавлены кипрское письмо, письмо лимбу, линейное письмо Б, сомалийское письмо, алфавит шоу, письмо лы и угаритское письмо, а также символы гексаграмм[32] |
| 4.1[33] | Март 2005 | ISO/IEC 10646:2003 и Amendment 1 | 59 | 97 720 | Добавлены письмо лонтара, глаголица, письмо кхароштхи, новое письмо лы, древнеперсидская клинопись, силхетское нагари и древнеливийское письмо. Символы коптского письма были отделены от символов греческого письма. Также добавлены символы старых греческих цифр, музыкальные символы Древней Греции и символ гривны (валюты Украины)[34] | |
| 5.0[35] | Июль 2006 | ISBN 0-321-48091-0 | ISO/IEC 10646:2003, Amendments 1, 2, четыре символа из Amendment 3 | 64 | 99 089 | Добавлены балийское письмо, клинопись, письмо нко, монгольское квадратное письмо и финикийское письмо[36] |
| 5.1[37] | Апрель 2008 | ISO/IEC 10646:2003 и Amendments 1, 2, 3, 4 | 75 | 100 713 | Добавлены карийское письмо, чамская письменность, письмо кая-ли, письмо лепча, ликийское письмо, лидийское письмо, письмо ол-чики, реджангское письмо, письмо саураштра, сунданское письмо, древнетюркское письмо и письмо ваи. Добавлены символы фестского диска, символы костей для маджонга и домино, заглавная буква эсцет (ẞ), а также буквы латиницы, использовавшиеся в средневековых рукописях для аббревиации. Новыми символами дополнен набор символов бирманского письма[38] | |
| 5.2[39] | Октябрь 2009 | ISO/IEC 10646:2003 и Amendments 1, 2, 3, 4, 5, 6 | 90 | 107 361 | Добавлены авестийское письмо, письмо бамум, египетское иероглифическое письмо (по списку Гардинера, содержащему 1071 символ), имперское арамейское письмо, пахлевийское эпиграфическое письмо, парфянское эпиграфическое письмо, яванское письмо, письмо кайтхи, письмо лису, письмо манипури, южноаравийское письмо, древнетюркское письмо, самаритянское письмо, письмо ланна и письмо тай-вьет. Добавлены 4149 новых унифицированных идеограмм китайского, японского и корейского письма (CJK-C), символы ведийского письма, символ тенге (валюты Казахстана), а также расширен набор символов чамо старого хангыля[40] | |
| 6.0[41] | Октябрь 2010 | ISO/IEC 10646:2010 и символ индийской рупии | 93 | 109 449 | Добавлены батакское письмо, письмо брахми, мандейское письмо. Добавлены символы игральных карт, дорожных знаков, географических карт, алхимии, эмотикона и эмодзи, а также 222 унифицированные идеограммы китайского, японского и корейского письма (CJK-D)[42] | |
| 6.1[43] | Январь 2012 | ISO/IEC 10646:2012 | 100 | 110 181 | Добавлены письмо чакма, мероитский курсив и мероитские иероглифы, письмо мяо, письмо шарада, письмо соранг-сомпенг и письмо такри[44] | |
| 6.2[45] | Сентябрь 2012 | ISO/IEC 10646:2012 и символ турецкой лиры | 100 | 110 182 | Добавлен символ турецкой лиры (валюты Турции)[46] | |
| 6.3[47] | Сентябрь 2013 | ISO/IEC 10646:2012 и шесть символов | 100 | 110 187 | Добавлено пять символов для форматирования двунаправленного текста[48] | |
| 7.0[49] | 16 июня 2014 | ISO/IEC 10646:2012, Amendments 1, 2 и символ рубля | 123 | 113 021 | Добавлены письмо басса, агванское письмо, стенография Дюплойе, эльбасанское письмо, письмо грантха, письмо ходжики, письменность худавади, линейное письмо А, письмо махаджани, манихейское письмо, письмо кикакуи, письмо моди, письмо мро, набатейское письмо, северноаравийское письмо, древнепермское письмо, письмо пахау, пальмирское письмо, письмо по чин хо, письмо псалтирь пехлеви, сиддхаматрика, письмо тирхута, варанг-кшити и орнамент дингбат, а также символ российского рубля и символ азербайджанского маната[50] | |
| 8.0[51] | 17 июня 2015 | ISO/IEC 10646:2014, Amendment 1, символ лари, 9 унифицированных идеограмм ККЯ, 41 эмодзи | 129 | 120 737 | Добавлены письмо ахом, анатолийские иероглифы, письмо хатран, письмо мултани, венгерские руны, SignWriting, 5776 Унифицированные идеограммы ККЯ — расширение E, строчные буквы письма чероки, буквы латиницы для немецкой диалектологии, 41 эмодзи, а также пять символов изменения цвета кожи для эмотиконов. Добавлен символ лари (валюты Грузии)[52] | |
| 9.0[53] | 21 июня 2016 | ISO/IEC 10646:2014, Amendments 1, 2, адлам, нева, японские символы для ТВ, 74 эмодзи и символов | 135 | 128 237 | Добавлены письмо адлам, письмо бхайкшуки, письмо марчен, письмо нева, письмо осейдж, тангутское письмо, а также 72 эмодзи и японские символы для телевидения[54] | |
| 10.0[55] | 20 июня 2017 | ISO/IEC 10646:2017, 56 эмодзи, 285 символов хэнтайганы, 3 символа квадратного письма Дзанабадзара | 139 | 136 755 | Добавлены квадратное письмо Дзанабадзара, письмо соёмбо, гонди Масарама, письмо нюй-шу, письмо хэнтайгана, 7494 Унифицированные идеограммы ККЯ — расширение F, а также 56 эмодзи и символ биткойна[56] | |
| 11.0 | Июнь 2018 | ISO/IEC 10646:2017 | 146 | 137 439 | Добавлены догра, грузинское письмо мтаврули, гунджалское гонди, ханифи, индийские цифры сийяк, макасарское письмо, медефайдрин, (древне-)согдийское письмо, цифры майя, 5 идеограмм ККЯ, символы сянци и половин звёздочек для оценки, а также 145 эмодзи, четыре символа изменения причёски для эмотиконов и символ копилефта[57][58][59] | |
| 12.0 | Март 2019 | ISO/IEC 10646:2017, Amendments 1, 2, а также 62 дополнительных символов | 150 | 137 993 | Добавлены элимайское письмо, надинагари, хмонг, ванчо, дополнения для письма Полларда, малая кана для старых японских текстов, исторические дроби и символы тамильского письма, буквы лаосского письма для пали, буквы латиницы для транслитерации угаритского, управляющие символы форматирования египетских иероглифов, а также 61 эмодзи[60][61] | |
| 12.1 | Май 2019 | 150 | 137 994 | Добавлен квадратный символ эпохи рэйва[62][63] | ||
| 13.0 | Март 2020 | 154 | 143 859 | Добавлены хорезмийское письмо, письмо дивес акуру, малое киданьское письмо, езидское письмо, 4969 идеограмм ККЯ (включая 4939 Унифицированные идеограммы ККЯ — расширение G), а также 55 эмодзи, символы Creative Commons и символы для унаследованной вычислительной техники. Выделено место для плоскости 3[64][65]
| ||
| 14.0 | Сентябрь 2021 | 159 | 144 697 | Добавлены письмо тото, кипро-минойское письмо, виткутьское письмо, староуйгурское письмо, тангса, дополнительные буквы латиницы (блоки Расширенная латиница — F, Расширенная латиница — G) для использования в расширениях для МФА, добавление арабского письма для использования в языках Африки, Ирана, Пакистана, Малайзии, Индонезии, Явы и Боснии, а также дополнения для использования в Коране, другие дополнения для поддержки языков Северной Америки, Филиппин, Индии и Монголии, добавление символа сома, нотописи знаменного пения и 37 эмодзи. | ||
| Примечания | ||||||
Кодовое пространство
Хотя форма записи UTF-8 позволяет кодировать до 221 (2 097 152) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого в данный момент более чем достаточно — в версии 14.0 используется всего 144 697 кодовых позиций.
Кодовое пространство разбито на 17 плоскостей (англ. planes) по 216 (65 536) символов. Нулевая плоскость (plane 0) называется базовой (basic) и содержит символы наиболее употребительных письменностей. Остальные плоскости — дополнительные (supplementary). Первая плоскость (plane 1) используется в основном для исторических письменностей, вторая (plane 2) — для редко используемых иероглифов китайского письма (ККЯ), третья (plane 3) зарезервирована для архаичных китайских иероглифов[66]. Плоскость 14 отведена для символов, используемых по особому назначению. Плоскости 15 и 16 выделены для частного употребления[7].
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов 0…FFFF), или «U+xxxxx» (для кодов 10000…FFFFF), или «U+xxxxxx» (для кодов 100000…10FFFF), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F16 = 110310.
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| 0 | Базовая многоязыковая плоскость (Basic Multilingual Plane, BMP) | U+0000…U+FFFF |
| 1 | Дополнительная многоязыковая плоскость (Supplementary Multilingual Plane, SMP) | U+10000…U+1FFFF |
| 2 | Дополнительная идеографическая плоскость (Supplementary Ideographic Plane, SIP) | U+20000…U+2FFFF |
| 3 | Третичная идеографическая плоскость (Tertiary Ideographic Plane, TIP) | U+30000…U+3FFFF |
| 4—13 | не используются | U+40000…U+DFFFF |
| 14 | Дополнительная специализированная плоскость (Supplementary Special-purpose Plane, SSP) | U+E0000…U+EFFFF |
| 15—16 | Дополнительные области для частного использования (Supplementary Private Use Area-A/B, SPUA-A/B) | U+F0000…U+10FFFF |
Система кодирования
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
- буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов;
- цифры;
- знаки пунктуации;
- специальные знаки (математические, технические, идеограммы и пр.);
- разделители.
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character). С 2014 года считается, что все буквы крупных письменностей в Юникод внесены, и если символ доступен в составном варианте, дублировать его в монолитном виде не нужно.
Общие принципы
- Гарантии стабильности
- Как только символ появился в кодировке, он не сдвинется и не исчезнет. Таким образом, каждый новый Юникод будет надмножеством старого. Если же потребуется изменить порядок символов, это делается не переменой позиций, а национальным порядком сортировки. Есть и другие, более тонкие гарантии стабильности — например, не будут меняться таблицы нормализации[67].
- Динамическая компоновка
- Такой высокой цели, как универсальность, Юникод добивается путём динамической сборки печатного текста. Иногда для удобства делают и монолитные символы, но в целом A + ¨ = Ä.
- Логический порядок
- Порядок символов приблизительно совпадает с порядком прочтения и набора, и не совпадает с порядком отображения, особенно в двунаправленном тексте. Существуют исторические исключения: так, в лаосском огласовки могут идти перед согласной, хотя читаются после.
- Преобразуемость
- Если в важной кодировке две формы одного символа закодированы разными позициями, это делает и Юникод. Преобразование не обязательно 1:1 — один символ другой кодировки может преобразоваться в несколько символов Юникода, и наоборот.
- Простой текст
- Юникод кодирует простой текст без оформления. Считается, что простой текст должен хранить достаточно данных, чтобы читаемо отобразить его, и больше ничего.
- Символы, не глифы
- Символ — единица смысла. Глиф — изображение, содержащееся в шрифте и выводящееся на экран/печать.
- Так, в шрифте арабского стиля настали́к будут тысячи глифов. Но в кодировке около 200 символов стандартного арабского, передающих смысл. И наоборот, иногда (см. Унификация) разные символы могут иметь одинаковый глиф.
- Универсальность
- Юникод разработан для людей разных языков и профессий: работающих в бизнесе, образовании, религии и науке, для современных и исторических текстов.
- За пределами Юникода лежат:
- письменности, про которые мало что известно, чтобы надёжно закодировать символы;
- письменности, чьи пользователи не пришли к де-факто стандарту;
- нетекстовые (например, пиктографические) письменности.
- Унификация
- Юникод старается не дублировать символы. Так, английская буква «вай», французская «игрек» и немецкая «ипсилон» — одна и та же кодовая позиция Y. Мало того, сходные иероглифы китайского и японского — одна кодовая позиция.
- Существует несколько важных исключений. Сходные буквы разных письменностей кодируются разными кодовыми позициями. Часто позиции дублируются для упрощения обработки — так, в Юникоде три буквы Ð с разными строчными. Математический штрих и такой же штрих для индикации мягкости звуков — разные символы, второй считается буквой-модификатором. Преобразуемость может идти вразрез с унификацией — строчная греческая сигма имеет две разных формы, и они — разные кодовые позиции.
- Эффективность
- Юникод устроен так, чтобы эффективные реализации были осуществимы. Коды символов — последовательные числа от 0 до 10FFFF16, это позволяет иметь дело с таблицами поиска. UTF-8 и UTF-16 — самосинхронизирующиеся коды, а важнейшие символы доступны без раскодировки. Юникод избегает форматирующих символов, которые меняют внутреннее состояние. И многое другое.
Политика консорциума
Консорциум не создаёт нового, а констатирует сложившийся порядок вещей[68]. Например, картинки «эмодзи» были добавлены потому, что японские операторы мобильной связи широко их использовали. Для этого добавление символа проходит через сложный процесс[68]. И, например, символ российского рубля прошёл его за три месяца, как только получил официальный статус, причём до этого он много лет де-факто использовался и его отказывались включить в Юникод.
Товарные знаки кодируют только в порядке исключения. Так, в Юникоде нет флага Windows или яблока Apple.
Эмодзи не вводятся в Юникод, если:[69]
- Понятие можно получить комбинацией имеющихся символов: «мыть руки» = «вода» + «руки». Белку часто изображают картинкой бурундука.
- Понятие слишком специфическое: если на картинке японского блюда суши рисуют, например, суши с креветкой, то не стоит запрашивать другие виды суши.
- Понятие может вызвать волну новых добавлений.
- Картинка содержит текст. Консорциум перестал включать такие эмодзи.
- Картинка преходящая (например, вирус COVID-19). Некоторые производители рисуют вирус на месте эмодзи «микроб».
- Требуется закодировать конкретное изображение (например, интернет-мем).
- Вариации направления движения: например, бегун бежит в другую сторону.
Комбинируемые символы
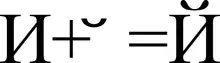
Cимволы в Юникоде подразделяются на базовые (англ. base characters) и комбинируемые (англ. combining characters). Комбинируемые символы обычно следуют за базовым и изменяют его отображение определённым образом. К комбинируемым символам, например, относятся диакритические знаки, знаки ударения. Например, русскую букву «Й» в Юникоде можно записать в виде базового символа «И» (U+0418) и комбинируемого символа « ̆» (U+0306), отображаемого над базовым.
Комбинируемые символы помечены в таблицах символов Юникода особыми категориями:
- Nonspacing Mark — безынтервальный (непротяжённый) знак; таковые обычно отображаются над или под базовым символом и не занимают отдельной горизонтальной позиции (интервала) в отображаемой строке;
- Enclosing Mark — обрамляющий знак; эти символы также не занимают отдельной горизонтальной позиции (интервала) в отображаемой строке, но отображаются сразу с нескольких сторон базового символа;
- Spacing Combining Mark — интервальный (протяжённый) комбинируемый знак; таковые, как и базовый символ, занимают отдельную горизонтальную позицию (интервал) в отображаемой строке.
Особый тип комбинируемых символов — селекторы варианта начертания (англ. variation selectors). Они действуют только на те базовые символы, для которых такие варианты определены. К примеру, в версии Юникода 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма.
Алгоритмы нормализации
Из-за наличия в Юникоде комбинируемых символов одни и те же знаки письменности можно представить различными кодами. Так, например, букву «Й» в примере выше можно записать как отдельным символом, так и сочетанием базового и комбинированного. Из-за этого сравнение строк байт за байтом становится невозможным. Алгоритмы нормализации (англ. normalization forms) решают эту проблему, выполняя приведение символов к определённому стандартному виду. Приведение осуществляется путём замены символов на эквивалентные с использованием таблиц и правил. «Декомпозицией» называется замена (разложение) одного символа на несколько составляющих символов, а «композицией», наоборот, — замена (соединение) нескольких составляющих символов на один символ.
В стандарте Юникода определены четыре алгоритма нормализации текста: NFD, NFC, NFKD и NFKC.
NFD
NFD, англ. normalization form D («D» от англ. decomposition), форма нормализации D — каноническая декомпозиция — алгоритм, согласно которому выполняется рекурсивное разложение составных символов (англ. precomposed characters) на последовательность из одного или нескольких простых символов в соответствии с таблицами декомпозиции. Рекурсивное потому, что в процессе разложения составной символ может быть разложен на несколько других, некоторые из которых тоже являются составными, и к которым применяется дальнейшее разложение.
Примеры:
|
→ |
| |||||
|
→ |
|
| |||||||
|
→ |
|
|
| |||||||||
|
→ |
|
|
| |||||||||||
|
→ |
|
|
| |||||||||||||
NFC
NFC, англ. normalization form C («C» от англ. composition), форма нормализации C — алгоритм, согласно которому последовательно выполняются каноническая декомпозиция и каноническая композиция. Сначала каноническая декомпозиция (алгоритм NFD) приводит текст к форме D. Затем каноническая композиция — операция, обратная NFD, обрабатывает текст от начала к концу с учётом следующих правил:
- символ
Sсчитается начальным, если имеет нулевой класс комбинируемости (англ. combining class of zero) согласно таблице символов Юникода; - в любой последовательности символов, начинающейся с символа
S, символCблокируется отS, только если междуSиCесть какой-либо символB, который либо является начальным, либо имеет одинаковый или больший класс комбинируемости, чемC. Это правило распространяется только на строки, прошедшие каноническую декомпозицию; - символ считается первичным композитом, если имеет каноническую декомпозицию в таблице символов Юникода (или каноническую декомпозицию для хангыля и он не входит в список исключений);
- символ
Xможет быть первично совмещён с символомY, если и только если существует первичный композитZ, канонически эквивалентный последовательности <X,Y>; - если очередной символ
Cне блокируется последним встреченным начальным базовым символомLи он может быть успешно первично совмещён с ним, тоLзаменяется на композитL-C, аCудаляется.
Пример:
|
|
→ |
| |||||||
NFKD
NFKD, англ. normalization form KD, форма нормализации KD — совместимая декомпозиция — алгоритм, согласно которому последовательно выполняются каноническая декомпозиция и замены символов текста по таблицам совместимой декомпозиции. Таблицы совместимой декомпозиции предусматривают замену на почти эквивалентные символы[70]:
- похожих на буквы (ℍ и ℌ);
- обведённых кружками (①);
- с изменёнными размерами (カ и カ);
- повёрнутых (︷ и {);
- степеней (⁹ и ₉);
- дробей (¼);
- других (™).
Примеры:
|
→ |
| |||||
|
→ |
| |||||
|
→ |
| |||||
|
→ |
| |||||
|
→ |
| |||||
|
→ |
| |||||||||
|
→ |
| |||||||
NFKC
NFKC, англ. normalization form KC, форма нормализации KC — алгоритм, согласно которому последовательно выполняются совместимая декомпозиция (алгоритм NFKD) и каноническая композиция (алгоритм NFC).
Примеры
| Исходный текст | NFD | NFC | NFKD | NFKC | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
|
|
|
|
| ||||||||||||||||||||||
Двунаправленное письмо
Стандарт Юникод поддерживает письменности языков как с направлением написания слева направо (англ. left-to-right, LTR), так и с написанием справа налево (англ. right-to-left, RTL) — например, арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учётом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленность (англ. bidirectional text, BiDi). Некоторые упрощённые обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево, и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунктуации) при отображении принимают направление окружающего их текста.
Представленные символы
Юникод включает практически все современные письменности, в том числе:
- арабскую,
- армянскую,
- бенгальскую,
- бирманскую,
- глаголицу,
- греческую,
- грузинскую,
- деванагари,
- еврейскую,
- кириллицу,
- китайскую (китайские иероглифы активно используются в японском языке, а также изредка в корейском),
- коптскую,
- кхмерскую,
- латинскую,
- тамильскую,
- корейскую (хангыль),
- чероки,
- эфиопскую,
- японскую (которая включает в себя, кроме слоговой азбуки, ещё и китайские иероглифы)
и другие.
С академическими целями добавлены многие исторические письменности, в том числе: германские руны, древнетюркские руны, древнегреческая письменность, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Государственные флаги не включены в Юникод напрямую. Для их кодирования используются пары из 26 буквенных символов, предназначенных для представления двухбуквенных кодов стран по стандарту ISO 3166-1 alpha-2. Эти буквы закодированы в диапазоне от U+1F1E6 🇦 regional indicator symbol letter a (HTML 🇦) до U+1F1FF 🇿 regional indicator symbol letter z (HTML 🇿).
В Юникод принципиально не включаются логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в области пользовательских символов. Существуют свободные бесплатные шрифты, включающие в себя логотипы компаний, программных продуктов и другие товарные знаки (например, Шрифт Awesome[71]).
ISO/IEC 10646
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO/IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO) началось в 1991 году. В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный набор кодированных символов (англ. universal coded character set). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Различия стандартов Юникод и ISO/IEC 10646:
- небольшие различия в терминологии;
- ISO/IEC 10646 не включает разделы, необходимые для полноценной реализации поддержки Юникода:
Способы представления
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Punycode — другая форма кодирования последовательностей Unicode-символов в так называемые ACE-последовательности, которые состоят только из алфавитно-цифровых символов, как это разрешено в доменных именах.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наибольшую компактность и обратную совместимость с 7-битной системой ASCII; текст, состоящий только из символов с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII и может быть отображён любой программой, работающей с ASCII; и наоборот, текст, закодированный 7-битной ASCII может быть отображён программой, предназначенной для работы с UTF-8. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байт, в которых первый байт всегда имеет маску 11xxxxxx, а остальные — 10xxxxxx. В UTF-8 не используются суррогатные пары.
Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в ОС Plan 9[72]. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
UTF-16 и UTF-32
UTF-16 — кодировка, позволяющая записывать символы Юникода в диапазонах U+0000…U+D7FF и U+E000…U+10FFFF (общим количеством 1 112 064). При этом каждый символ записывается одним или двумя словами (суррогатная пара). Кодировка UTF-16 описана в приложении Q к международному стандарту ISO/IEC 10646, а также ей посвящён документ IETF RFC 2781 под названием «UTF-16, an encoding of ISO 10646».
UTF-32 — способ представления Юникода, при котором каждый символ занимает ровно 4 байта. Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод в ней непосредственно индексируемы, поэтому найти символ по номеру его позиции в файле можно чрезвычайно быстро, и получение любого символа n-й позиции при этом является операцией, занимающей всегда одинаковое время. Это также делает замену символов в строках UTF-32 очень простой. Напротив, кодировки с переменной длиной требуют последовательного доступа к символу n-й позиции, что может быть очень затратной по времени операцией. Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения любого символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства, редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства, зачастую не оправдано.
Порядок байтов
В потоке данных UTF-16 младший байт может записываться либо перед старшим (англ. UTF-16 little-endian, UTF-16LE), либо после старшего (англ. UTF-16 big-endian, UTF-16BE). Аналогично существует два варианта четырёхбайтной кодировки — UTF-32LE и UTF-32BE.
Маркер последовательности байтов
Для указания на использование Юникода, в начале текстового файла или потока может передаваться Маркер последовательности байтов (англ. byte order mark (BOM)) — символ U+FEFF (неразрывный пробел нулевой ширины). По его виду можно легко различить как формат представления Юникода, так и последовательность байтов. Маркер последовательности байтов может принимать следующий вид:
- UTF-8
- EF BB BF
- UTF-16BE
- FE FF
- UTF-16LE
- FF FE
- UTF-32BE
- 00 00 FE FF
- UTF-32LE
- FF FE 00 00
Юникод и традиционные кодировки
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше такая кодировка всегда задавалась непосредственно, то теперь она может задаваться таблицей соответствия между данной кодировкой и Юникодом. Фактически почти все 8-битные кодировки теперь можно рассматривать как форму представления некоторого подмножества Юникода. И это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки символов в Юникод.
Кроме того, многие форматы данных позволяют вставлять любые символы Юникода, даже если документ записан в старой 8-битной кодировке. Например, в HTML можно использовать коды с амперсандом.
Реализации
Большинство современных операционных систем в той или иной степени обеспечивает поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах. Подробнее см. в статье Юникод в операционных системах семейства Microsoft Windows.
UNIX-подобные операционные системы, в том числе GNU/Linux, BSD, OS X, используют для представления Юникода кодировку UTF-8. Большинство программ может работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Это решение увеличило расход памяти, но позволило вернуть в программирование важную абстракцию: произвольный одиночный символ (тип char). В частности, программист мог работать со строкой, как с простым массивом. Успех не был окончательным, Юникод перерос ограничение в 16 бит и к версии J2SE 5.0 произвольный символ снова стал занимать переменное число единиц памяти — один char или два (см. суррогатная пара).
Сейчас[когда?] большинство[сколько?] языков программирования поддерживает строки Юникода, хотя их представление может различаться в зависимости от реализации.
Методы ввода
Поскольку ни одна раскладка клавиатуры не может позволить вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Microsoft Windows
Начиная с Windows 2000, служебная программа «Таблица символов» (charmap.exe) поддерживает символы Юникода и позволяет копировать их в буфер обмена. Реализована поддержка только базовой плоскости (коды символов U+0000…U+FFFF); символы с кодами от U+10000 «Таблица символов» не отображает. Похожая таблица есть в Microsoft Word.
Иногда можно набрать шестнадцатеричный код, нажать Alt+X, и код будет заменён на соответствующий символ, например, в WordPad, Microsoft Word. В редакторах Alt+X выполняет и обратное преобразование. В программах, работающих в среде Windows, чтобы получить символ Unicode, нужно при нажатой клавише Alt набрать десятичное значение кода символа на цифровой клавиатуре: например, комбинации Alt+0171 и Alt+0187 выводят левую и правую кавычки-ёлочки, соответственно, Alt+0151 — длинное тире, Alt+0769 — знак ударения, Alt+0133 — многоточие и пр.
Macintosh
В Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый «Unicode Hex Input». При зажатой клавише Option требуется набрать четырёхзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFD, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активизировать в соответствующем разделе системных настроек и затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2, существует также приложение «Character Palette», позволяющее выбирать символы из таблицы, в которой можно выделять символы определённого блока или символы, поддерживаемые конкретным шрифтом.
GNU/Linux
В GNOME также есть утилита «Таблица символов» (ранее gucharmap), позволяющая отображать символы определённого блока или системы письма и предоставляющая возможность поиска по названию или описанию символа. Когда код нужного символа известен, его можно ввести в соответствии со стандартом ISO 14755: при зажатых клавишах Ctrl+⇧ Shift ввести шестнадцатеричный код (начиная с некоторой версии GTK+, ввод кода нужно предварить нажатием клавиши «U»). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
Все приложения X Window, включая GNOME и KDE, поддерживают ввод при помощи клавиши Compose. Для клавиатур, на которых нет отдельной клавиши Compose, для этой цели можно назначить любую клавишу — например, ⇪ Caps Lock.
Консоль GNU/Linux также допускает ввод символа Юникода по его коду — для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при зажатой клавише Alt. Можно вводить символы и по их шестнадцатеричному коду: для этого нужно зажать клавишу AltGr, и для ввода цифр A—F использовать клавиши расширенного блока клавиатуры от NumLock до ↵ Enter (по часовой стрелке). Поддерживается также и ввод в соответствии с ISO 14755. Для того чтобы перечисленные способы могли работать, нужно включить в консоли режим Юникода вызовом unicode_start(1) и выбрать подходящий шрифт вызовом setfont(8).
Mozilla Firefox для Linux поддерживает ввод символов по ISO 14755.
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним и тем же символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
- Тексты на китайском, корейском и японском языках имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Переключение горизонтального и вертикального написания для этих языков не предусмотрено в Юникоде — это должно осуществляться средствами языков разметки или внутренними механизмами текстовых процессоров.
- Наличие или отсутствие в Юникоде разных начертаний одного и того же символа в зависимости от языка. Нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку.
- Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханча), но при этом в Юникоде обозначаются одним и тем же символом (так называемая CJK-унификация), хотя упрощённые и полные иероглифы всё же имеют разные коды.
- Аналогично, русский и сербский языки используют разное начертание курсивных букв п и т (в сербском они выглядят как п (и̅) и т (ш̅), см. сербский курсив).
- Перевод из строчных букв в заглавные тоже зависит от языка. Например: в турецком существуют буквы İi и Iı — таким образом, турецкие правила изменения регистра конфликтуют с английскими, которые предписывают «i» переводить в «I». Подобные проблемы есть и в других языках — например, в канадском диалекте французского языка регистр переводится немного не так, как во Франции[73].
- Даже с арабскими цифрами есть определённые типографские тонкости: цифры бывают «прописными» и «строчными», пропорциональными и моноширинными[74] — для Юникода разницы между ними нет. Подобные нюансы остаются за программным обеспечением.
Некоторые недостатки связаны не с самим Юникодом, а с возможностями обработчиков текста.
- Файлы нелатинского текста в Юникоде всегда занимают больше места, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков, алфавит которых укладывается в ASCII, а также наличие в тексте символов двух и более языков, алфавит которых не укладывается в ASCII[75]). Файл шрифта всех символов таблицы Юникод занимает сравнительно много места в памяти и требует бо́льших вычислительных ресурсов, чем шрифт только одного национального языка пользователя[76]. С увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной; тем не менее, она остаётся актуальной для портативных устройств, например, для мобильных телефонов.
- Хотя поддержка Юникода реализована в наиболее распространённых операционных системах, до сих пор не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки порядка байтов (BOM) и плохо поддерживаются диакритические символы. Проблема является временной и есть следствие сравнительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).
- Производительность всех программ обработки строк (в том числе и сортировок в БД) снижается при использовании Юникода вместо однобайтовых кодировок.
Некоторые редкие системы письма всё ещё не представлены должным образом в Юникоде. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, как, например, в церковнославянском языке, пока не реализовано.
Написание слова «Unicode»
«Unicode» — одновременно и имя собственное (или часть имени, например, Unicode Consortium), и имя нарицательное, происходящее из английского языка.
На первый взгляд предпочтительнее использовать написание «Уникод». В русском языке уже есть морфемы «уни-» (слова с латинским элементом «uni-» традиционно переводились и писались через «уни-»: универсальный, униполярный, унификация, униформа) и «код». Напротив, торговые марки, заимствованные из английского языка, обычно передаются посредством практической транскрипции, в которой деэтимологизированное сочетание букв «uni-» записывается в виде «юни-» («Юнилевер», «Юникс» и т. п.), то есть точно так же, как в случае с побуквенными сокращениями, вроде UNICEF «United Nations International Children’s Emergency Fund» — ЮНИСЕФ.
На сайте Консорциума есть специальная страница, где рассматриваются проблемы передачи слова «Unicode» в различных языках и системах письма. Для русской кириллицы указан вариант «Юникод»[1]. В MS Windows также используется вариант «Юникод».
В Википедии на русском языке используется вариант «Юникод» как наиболее распространённый.
См. также
- Символы, представленные в Юникоде
- ASCII
- ISO 8859-1
- UTF-8
- UTF-16
- UTF-32
- Кириллица в Юникоде
- Дроби в Юникоде
- XeTeX
- Свободные универсальные шрифты
- Windows Glyph List 4
- Широкий символ
- Библиотека GLib содержит широкий набор функций для работы c символами и строками в кодировке Unicode
- Проект:Внесение символов алфавитов народов России в Юникод
Примечания
- Unicode Transcriptions (англ.) (недоступная ссылка). Дата обращения: 10 мая 2010. Архивировано 8 апреля 2006 года.
- Уникод в словаре Paratype
- The Unicode® Standard: A Technical Introduction (недоступная ссылка). Дата обращения: 4 июля 2010. Архивировано 10 марта 2010 года.
- History of Unicode Release and Publication Dates (недоступная ссылка). Дата обращения: 4 июля 2010. Архивировано 10 января 2010 года.
- The Unicode Consortium (недоступная ссылка). Дата обращения: 4 июля 2010. Архивировано 27 июня 2010 года.
- Foreword (недоступная ссылка). Дата обращения: 4 июля 2010. Архивировано 27 июня 2010 года.
- General Structure (недоступная ссылка). Дата обращения: 5 июля 2010. Архивировано 27 июня 2010 года.
- European Alphabetic Scripts (недоступная ссылка). Дата обращения: 4 июля 2010. Архивировано 27 июня 2010 года.
- Что такое Unicode?
- Unicode 88 (недоступная ссылка). Дата обращения: 8 июля 2010. Архивировано 6 сентября 2017 года.
- Unicode and Microsoft Windows NT (англ.) (недоступная ссылка). Microsoft Support. Дата обращения: 12 ноября 2009. Архивировано 26 сентября 2009 года.
- Unicode используется почти на 50% веб-сайтов (недоступная ссылка). Дата обращения: 9 февраля 2010. Архивировано 11 июня 2010 года.
- History of Unicode Release and Publication Dates
- Enumerated Versions
- About Versions
- Unicode® 1.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 1.0.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode Data 1.0.1 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 1.1 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 1995 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 2.0.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 2.0.14 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 2.1.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 2.1.2 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 3.0.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 3.0.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 3.1.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 3.1.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 3.2.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 3.2.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 4.0.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 4.0.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 4.1.0 (англ.). Unicode Consortium. Дата обращения: 8 декабря 2017.
- Unicode Data 4.1.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 5.0.0 (англ.). Unicode Consortium (14 июля 2006). Дата обращения: 8 декабря 2017.
- Unicode Data 5.0.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode 5.1.0 (англ.). Unicode Consortium (4 апреля 2008). Дата обращения: 8 декабря 2017.
- Unicode Data 5.1.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 5.2.0 (англ.). Unicode Consortium (1 октября 2009). Дата обращения: 8 декабря 2017.
- Unicode Data 5.2.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 6.0.0 (англ.). Unicode Consortium (11 октября 2010). Дата обращения: 8 декабря 2017.
- Unicode Data 6.0.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 6.1.0 (англ.). Unicode Consortium (31 января 2012). Дата обращения: 8 декабря 2017.
- Unicode Data 6.1.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 6.2.0 (англ.). Unicode Consortium (26 сентября 2012). Дата обращения: 7 декабря 2017.
- Unicode Data 6.2.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 6.3.0 (англ.). Unicode Consortium (30 сентября 2012). Дата обращения: 7 декабря 2017.
- Unicode Data 6.3.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 7.0.0 (англ.). Unicode Consortium (16 июня 2014). Дата обращения: 8 декабря 2017.
- Unicode Data 7.0.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 8.0.0 (англ.). Unicode Consortium (17 июня 2015). Дата обращения: 8 декабря 2017.
- Unicode Data 8.0.0 (англ.). Дата обращения: 4 декабря 2017.
- Unicode® 9.0.0 (англ.). Unicode Consortium (21 июня 2016). Дата обращения: 8 декабря 2017.
- Unicode Data 9.0.0 (англ.). Дата обращения: 6 декабря 2017.
- Unicode® 10.0.0 (англ.). Unicode Consortium (27 июня 2017). Дата обращения: 8 декабря 2017.
- Unicode Data 10.0.0 (англ.). Дата обращения: 7 декабря 2017.
- Unicode Data 11.0.0 (англ.). Дата обращения: 12 апреля 2019.
- The Unicode Blog: Announcing The Unicode® Standard, Version 11.0
- Unicode 11.0.0
- The Unicode Blog: Announcing The Unicode® Standard, Version 12.0
- Unicode 12.0.0
- The Unicode Blog: Unicode Version 12.1 released in support of the Reiwa Era
- Unicode 12.1.0
- The Unicode Blog: Announcing The Unicode Standard, Version 13.0
- Unicode 13.0.0
- Roadmap to the TIP (Tertiary Ideographic Plane)
- Unicode Character Encoding Stability Policy
- FAQ — Emoji & Dingbats
- Guidelines for Submitting Unicode® Emoji Proposals
- Нормализация Unicode
- GitHub — FortAwesome/Font-Awesome: The iconic SVG, font, and CSS toolkit
- Архивированная копия (недоступная ссылка). Дата обращения: 27 февраля 2007. Архивировано 29 октября 2006 года. (англ.)
- Регистр в Unicode — это непросто
- В большинстве шрифтов для ПК реализованы «прописные» (маюскульные) моноширинные цифры.
- В некоторых случаях документ (не простой текст) в Юникоде может занимать существенно меньше места, чем документ в однобайтовой кодировке. Например, если некая веб-страница содержит примерно поровну русского и греческого текста, то в однобайтовой кодировке придётся либо русские, либо греческие буквы записывать, используя возможности формата документов, в виде кодов с амперсандом, которые занимают 6—7 байт на символ (при использовании десятичных кодов), то есть в среднем на букву придётся 3,5—4 байта, в то время как UTF-8 занимает только 2 байта на греческую или русскую букву.
- Один из файлов шрифтов Arial Unicode имеет размер 24 мегабайта; существует Times New Roman размером 120 мегабайт, он содержит количество символов, близкое к 65536.
Ссылки
- Официальный сайт Консорциума Юникода (англ.)
- Unicode в каталоге ссылок Curlie (dmoz) (англ.)
- Статья «Что такое Unicode?» (рус.) на официальном сайте Консорциума
- Последняя версия стандарта Юникод (англ.)
- Последнюю версию стандарта ISO/IEC 10646 ищите в списке доступных стандартов (англ.). Документы, соответствующие стандарту Unicode 7.0: ISO/IEC 10646 (файл ZIP) (англ.), Amendments 1 (файл ZIP) (англ.), Amendments 2 (по состоянию 2014-08-06 ещё недоступен)
- Таблица символов Юникода с названиями и описаниями (рус.) (англ.) (нем.)
- Связь Юникода версии 5.0.0 и ISO/IEC 10646 (файл PDF) (англ.)
- FAQ по UTF-8 и Unicode (англ.)
- Кириллица в Юникоде: http://www.unicode.org/charts/PDF/U0400.pdf, http://www.unicode.org/charts/PDF/U0500.pdf, http://www.unicode.org/charts/PDF/U2DE0.pdf, http://www.unicode.org/charts/PDF/UA640.pdf (англ.) Архивная копия от 17 ноября 2008 на Wayback Machine
- Включение поддержки дополнительных символов Юникода в Windows (англ.)
- Поиск по символам Юникода (англ.)
Шрифтолитейное дело и шрифтовой дизайн | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Понятия |  | ||||||||
| Строение шрифта |
| ||||||||
| Характеристики шрифта | |||||||||
| Классификация шрифтов алфавитного письма |
| ||||||||
| Начертания шрифта | |||||||||
| Единицы измерения | |||||||||
| Компьютерная типографика | |||||||||
| |||||||||
