Предсказание структуры белка
Предсказа́ние структу́ры белка́ (англ. protein structure prediction) — направление молекулярного моделирования, предсказание по аминокислотной последовательности трёхмерной структуры белка[1] (вторичной, третичной или четвертичной). Данная задача является одной из самых важных целей биоинформатики и теоретической химии. Данные, полученные при помощи предсказания, применяются в медицине (например, в фармацевтике) и биотехнологии при создании новых ферментов).
Введение
Огромные объёмы данных о последовательности белков стали доступны в результате современных широкомасштабных работ по секвенированию ДНК, таких как проект «Геном человека». Несмотря на усилия всего сообщества в области структурной геномики, количество экспериментально определённых белковых структур — обычно с помощью трудоёмкой и относительно дорогой рентгеновской кристаллографии или ЯМР-спектроскопии — значительно отстаёт от количества белковых последовательностей, что делает предсказание третичной структуры белка крайне востребованным[2].
Предсказание структуры белка остаётся чрезвычайно трудной и не до конца разрешённой задачей. Две основные проблемы — это расчёт свободной энергии и нахождение глобального минимума этой энергии[3]. Метод предсказания структуры белка должен исследовать пространство всех возможных структур белка, которое является астрономически большим. Эти проблемы можно частично обойти с помощью сравнительного (гомологического) моделирования и методах распознавания укладки (фолда), в которых пространство поиска сокращается из-за предположения, что рассматриваемый белок принимает структуру, близкую к экспериментально определённой структуре другого гомологичного белка. С другой стороны, методы предсказания структуры белка ab initio должны явно разрешать эти проблемы, не опираясь на начальные предположения[4][5].
В декабре 2020 года команда DeepMind (исследовательского подразделения Google) объявила о решении фундаментальной научной проблемы предсказания структуры белка. Программа, разработанная компанией и основанная на нейросетях, смогла предсказывать структуру белка с высокой точностью.[6]
Структура белка
Вторичная структура белка
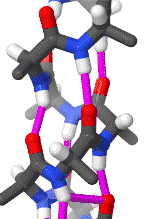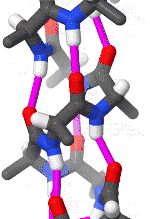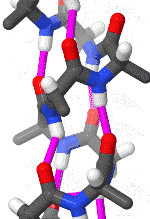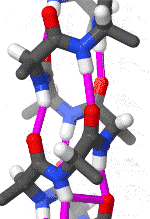
Альфа-спираль
Альфа-спираль является наиболее распространённым типом вторичной структуры в белках. Альфа-спираль имеет 3,6 аминокислоты на поворот, а Н-связь образуется между каждым четвёртым остатком; средняя длина составляет 10 аминокислот (3 витка) или 10 Å, но варьируется от 5 до 40 (от 1,5 до 11 витков). Выравнивание Н-связей создаёт дипольный момент для спирали с результирующим частичным положительным зарядом на амино-конце спирали. Наиболее распространённое расположение α-спиралей находится на поверхности белков, где они обеспечивают взаимодействие с водной средой[7].
Внутренняя сторона спирали обычно содержит гидрофобные аминокислоты, а внешняя сторона гидрофильные аминокислоты. Таким образом, каждая третья из четырёх аминокислот в цепи будет гидрофобной, и поэтому эту аминокислоту можно легко обнаружить. В лейциновой молнии повторяющийся узор остатков лейцина на внешних сторонах двух соседних спиралей является, в значительной степени, характеризующем для данной структуры. Другие α-спирали, находящиеся в гидрофобном ядре белка или же в трансмембранных доменах белков, имеют более высокий процент гидрофобных аминокислот, которые равномернее распределены по цепи, что также служит хорошим маркером для данных частей белков. Качественное содержание аминокислот может быть хорошим маркером α-спиральной области. Регионы, имеющую большую концентрацию различных аминокислот, таких как аланин (A), глутаминовая кислота(E), лейцин (L) и метионин (M), а также более бедные по концентрации пролина (P), глицина (G), тирозина (Y) и серина (S), как правило, образуют α-спираль[8][9].
β-лист
β-листы образованы Н-связями между в среднем 5—10 последовательными аминокислотами в одной части цепи и ещё 5—10 дальше по цепочке. Каждая цепь может проходить в одном и том же направлении, образуя параллельный лист, если цепи идут в разных направлениях, то образуется антипараллельный лист. Характер Н-связи различен в параллельной и антипараллельной конфигурации. Углы ψ и φ аминокислот в листах значительно варьируются в одной области Карты Рамачандрана. Предсказать местоположение β-листов в структуре белка сложнее, чем α-спиралей[10][11].
Петля
Петли представляют собой области белковой цепи, которые между α-спиралями и β-листами, различной длины и трёхмерной конфигурации и могут располагать, как на поверхности белка, так и ближе к ядру[12].
Петли шпилек, которые представляют собой полный оборот в полипептидной цепи, соединяющей две антипараллельные β-цепи, могут быть длиной до двух аминокислот. Петли могут взаимодействуют с окружающей средой(вода и другие растворители) и другими белками. Поскольку геометрия аминокислот в петлях не ограничена в пространством, как аминокислоты в области ядра, где очень плотная укладка цепи, и не так сильно влияют на правильную укладку белка, то там может происходить большее количество замен, вставок и делеций, которые не повлияют на функции белка. Таким образом, при выравнивании последовательностей, наличие этих мутаций (вставок, делеций, замен) может указывать на петлю. Позиции интронов в геномной ДНК иногда соответствуют местам петель в кодируемом белке, петли также имеют тенденцию иметь заряженные и полярные аминокислоты и часто являются компонентом сайтов связывания[13].
Третичная структура белка
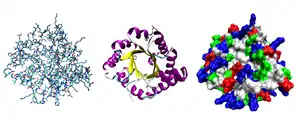
Третичная структура — пространственное строение (включая конформацию) всех элементов вторичной структуры, состоящей из единственной цепи аминокислот. Спирализация линейной полипептидной цепи уменьшает её размеры примерно в 4 раза; а укладка в третичную структуру делает её в десятки раз более компактной, чем исходная цепь[14].
Поскольку ни полипептидная цепь, ни α-спирали и β-листы не дают представления об объёме, форме полипептидной цепи, перед исследователем всегда стоит необходимость определения трёхмерной или пространственной конфигурации белка.[15]
Четвертичная структура белка
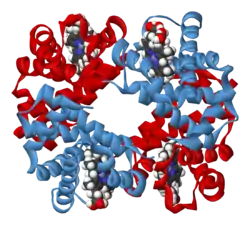
Четвертичная структура — способ укладки в пространстве отдельных полипептидных цепей, обладающих одинаковой (или разной) первичной, вторичной или третичной структурой, и формирование единого в структурном и функциональном отношениях макромолекулярного образования. Специфичность четвертичной структуры белков проявляется в определённой конформационной автономии полипептидных фрагментов, входящих в состав макромолекулы белка. Вклад гидрофобных взаимодействий в стабилизацию третичной и четвертичной структуры белков весьма значителен: в случае третичной структуры на их долю приходится больше половины стабилизирующей силы.[16]
Многие белки представляют собой сборки из нескольких полипептидных цепей. Примеры белков с четвертичной структурой включают гемоглобин , ДНК-полимеразу и различные ионные каналы[17]
Предсказание структуры белка
Алгоритмы предсказания вторичной структуры
Алгоритмы предсказания вторичной структуры — это набор методов предсказания локальной вторичной структуры белков, основанных только на знании об их аминокислотной последовательности[18]. Для белков предсказание состоит в соотнесении отдельных участков аминокислотной последовательности с наиболее вероятными классами вторичных структур, таких, как α-спирали, β-тяжи или петли[18]. Точность предсказания определяется, как соотношение количества аминокислот, для которых предсказанный структурный класс совпал со структурным классом, определённым для этой аминокислоты алгоритмом DSSP[en] (или похожим алгоритмом, к примеру, алгоритмом STRIDE), к общему числу аминокислот в последовательности. Эти алгоритмы производят разметку аминокислотной последовательности белка в соответствии с принадлежностью аминокислот к одному из классов вторичной структуры, различающихся специфическими паттернами водородных связей и наборами двугранных углов. Для DSSP это 8 класcов, которые можно объединить в три группы: 3 класса спиралей (α-спираль, π-спираль и 310-спираль), два класса β-структур (изолированные β-мостики и β-листы) и три вида петли (повороты, изгибы и неклассифицированные элементы, отвечающие характеристикам петли)[19]. Чаще всего для оценки качества структуры используют упрощенную классификацию, в которой классы внутри этих трёх групп считаются тождественными[2]. Алгоритмы предсказания вторичной структуры белка можно условно разделить на группы, основываясь на принципах, лежащих в их основе. Эти группы включают в себя статистические методы, методы ближайших соседей, методы, использующие нейронные сети, методы опорных векторов и методы, основанные на скрытых марковских моделях.[20]
Ниже рассмотрены некоторые из этих алгоритмов.
Статистический метод Чоу-Фасмана основан на расчёте оценки вероятности принадлежности определённой аминокислоты к определённому классу вторичной структуры в базах данных. Предсказание делается относительно трёх классов вторичных структур: петли, β-листа и поворота. Цель алгоритма — найти участок из определённого для каждого класса вторичной структуры количества идущих подряд аминокислот, для каждой из которых оценка вероятности принадлежности к этому классу вторичной структуры больше заданного значения. На выход такие алгоритмы выдают предсказанные таким образом участки для каждого из трёх основных классов вторичных структур, картированные на последовательность.[21]
Первый этап метода ближайших соседей (алгоритм NNSSP) заключается в поиске гомологичной последовательности, для которой известна трёхмерная структура. Учитывая локальные структурные особенности определённого аминокислотного остатка в трёхмерной структуре гомологичной последовательности, такие, как доступность для растворителя, полярность и вторичная структура, каждому аминокислотному остатку присваивается «класс окружения». Оценка вероятности принадлежности аминокислоты в центре исследуемого сегмента длиной n аминокислот к определённому классу вторичной структуры рассчитывается как логарифм частоты нахождения этой аминокислоты в окружении, к которому относится большинство её соседей, в базах данных.[22]
Один из алгоритмов, использующих нейронные сети, PSIPRED, включает в себя четыре основных этапа: генерация позиционной весовой матрицы с помощью PSI-BLAST, первичное предсказание вторичной структуры и дальнейшая фильтрация предсказаний. Второй и третий этапы задействуют две нейросети. Для определения принадлежности аминокислоты к определённому классу вторичной структуры на вход первой нейронной сети подаётся фрагмент позиционной весовой матрицы размером 33x21, соответствующий фрагменту исходной последовательности в 33 аминокислоты с аминокислотой интереса по центру[23]. Эта сеть имеет два скрытых слоя и три выходных узла, соответствующих трём предсказываемым классам вторичной структуры. Вторая нейронная сеть используется для фильтрации предсказаний первой сети и также обладает тремя выходного узлами для каждого класса вторичной структуры в центральной позиции исследуемого окна. На выход алгоритм выдаёт разметку аминокислотной последовательности по элементам вторичной структуры.[24]
Помимо вышеописанного, классические алгоритмы с использованием скрытых марковских моделей, такие как алгоритм прямого-обратного хода, алгоритм Витерби и алгоритм Баума-Велша, могут быть оптимизированы для соотнесения аминокислотной последовательности с классами вторичных структур.[25]
Наилучшие современные методы определения вторичной структуры белка достигают около 80 % точности[26]. Точность ныне существующих методов предсказания вторичных структур оценивается такими еженедельно обновляющимися ресурсами, как LiveBench и EVA[27].
Первичная подготовка
Большинство методов моделирования третичной структуры оптимизированы для моделирования третичной структуры отдельных белковых доменов. Этап, называемый анализом домена или предсказанием границы домена, обычно выполняется первым, чтобы разделить белок на потенциальные структурные домены. Как и в случае с остальными этапами предсказания третичной структуры, это можно сделать с помощью сравнения с известными структурами или ab initio только с помощью последовательности (обычно с помощью машинного обучения, задействующего ковариацию)[28][29]. Структуры отдельных доменов объединяются в одну окончательную третичную структуру в процессе, называемом сборкой доменов[30].
Методы, основанные на расчёте энергии
Методы моделирования ab initio- стремятся создавать трёхмерные белковые модели «с нуля», то есть они основаны на физических принципах, а не непосредственно на экспериментально полученных данных о структурах. Существует множество возможных подходов, которые либо пытаются имитировать сворачивание белка, либо применяют стохастические методы для поиска возможных решений (то есть поиск глобального максимума некой энергетической функции)[31]. Эти подходы, как правило, требуют огромных вычислительных ресурсов и, таким образом, могут быть применены только для крошечных белков. Для прогнозирования структуры белка ab initio для более крупных белков требуются более совершённые алгоритмы и большие вычислительные ресурсы, представленные либо мощными суперкомпьютерами (такими как Blue Gene или MDGRAPE-3), либо распределёнными вычислениями (такими как Folding@home, Human Proteome Folding Project и Rosetta@Home)[32].
Коэволюционирующие последовательности в предсказании контактов в 3D
Поскольку секвенирование стало более распространённым явлением в 1990-х годах, несколько групп исследователей использовали выравнивание белковых последовательностей для предсказания коррелированных мутаций, и была надежда, что эти совместно эволюционирующие остатки могут быть использованы для предсказания третичной структуры. Предполагается, что когда мутация одного аминокислотного остатка не является летальной, может возникнуть компенсаторная мутация для стабилизации взаимодействий между остатками. В ранних работах использовались так называемые локальные методы для расчёта коррелированных мутаций белковых последовательностей, при этом из-за независимого рассмотрения каждой пары остатков возникали ложные корреляции[33][34].
В 2011 году другой статистический подход продемонстрировал, что предсказанных коэволюционирующих остатков достаточно, чтобы предсказать трёхмерную укладку белка, при условии, что имеется достаточно последовательностей (необходимо > 1000 гомологичных последовательностей)[35]. Метод EVfold не использует моделирование по гомологии и может быть запущен на стандартном персональном компьютере даже для белков, состоящих из сотен остатков. Точность предсказаний этого и связанных с ним подходов, была продемонстрирована на многих структурах и картах контактов[36][37][38].
Сравнительное моделирование структуры белка
Сравнительное моделирование структуры белка использует структуры, полученные ранее с помощью экспериментальных методов в качестве отправных точек. Это эффективно, так как, судя по всему, хотя число существующих белков огромно, количество третичных структурных мотивов, к которым принадлежит большинство белков, ограничено[4].
Эти методы также можно разделить на две группы[39]:
- Моделирование по гомологии основано на предположении о том, что гомологичные белки обладают схожей структурой. Так как укладка белка более консервативна, чем его аминокислотная последовательность, структура изучаемого белка может быть предсказана с неплохой точностью даже в случае далёкого родства с белком, использующимся в качестве шаблона, при условии, что гомологию между шаблоном и целевым белком можно проследить выравниванием последовательностей[40]. Было высказано предположение, что основная слабость сравнительного моделирования состоит в неточности выравниваний, а не в ошибках в прогнозировании структуры при условии известного хорошего выравнивания[41]. Неудивительно, что моделирование по гомологии достигает наилучших результатов, когда целевой белок и шаблон имеют схожие последовательности.[4]
- Распознавание укладки производит поиск аминокислотной последовательности, для которой неизвестна структура, в базе данных известных структур[42]. В каждом случае используется score-функция для оценки совместимости последовательности со структурой, что позволяет получить набор возможных трёхмерных моделей. Этот тип методов также известен как 3D-1D распознавание укладки из-за анализа совместимости между трёхмерными структурами и линейными белковыми последовательностями.[43]
Предсказание геометрии боковых радикалов
Точное предсказание расположения боковых аминокислотных радикалов в структуре представляет собой отдельную проблему в прогнозировании структуры белка. Методы, которые решают проблему прогнозирования геометрии боковых радикалов, включают в себя устранение тупиков и методы самосогласованного поля[44][45]. Конформации боковых радикалов с низкой энергией обычно определяются на жёстком полипептидном остове и используют набор дискретных конформаций боковой цепи, «ротамеров». Принцип работы таких методов заключается в поиске набора ротамеров, минимизирующего общую энергию модели[40]</ref>.
Эти методы используют библиотеки ротамеров, которые представляют собой наборы благоприятных конформаций для каждого типа остатка в белке. Библиотеки ротамеров могут содержать информацию о конформации, её частоте и стандартных отклонениях относительно средних значений торсионных углов, которые могут быть использованы при отборе вариантов[46]. Библиотеки ротамеров получают с помощью структурной биоинформатики или другого статистического анализа конформаций боковых цепей в известных по экспериментальным данным структурах белков. Библиотеки ротамеров могут быть независимыми от остова, зависимыми от вторичной структуры или зависимыми от остова. Библиотеки ротамеров, не зависимые от остова, не используют информацию о конформации остова и рассчитываются по всем доступным боковым цепям определённого типа (например, первый пример библиотеки ротамеров, сделанный Пондером и Ричардсом в Йельском университете в 1987 году[47]). Библиотеки, зависящие от вторичной структуры, представляют собой различные торсионные углы и (или) частоты ротамеров для классов вторичных структур (альфа-спирали, бэта-листа или петли[48]). Зависящие от остова библиотеки ротамеров представляют собой конформации и (или) их частоты, зависящие от локальной конформации основной цепи, которая определяется торсионными углами фи и пси и не зависит от вторичной структуры[49]. Современные версии этих библиотек, используемые в большинстве программ, представлены в виде многомерных распределений вероятности или частоты, где пики соответствуют конформациям торсионного угла, рассматриваемым как отдельные ротамеры.[50]
Белок-белковый докинг
Белок-белковый докинг (или Белок-белковое взаимодействие (ББВ)) — метод молекулярного моделирования, позволяющий предсказать наиболее выгодную для образования устойчивого комплекса ориентацию и конформацию одной молекулы (лиганда) в центре связывания другой (рецептора). Данные о положении и конформации белков партнеров используются для предсказания силы взаимодействия посредством так называемых оценочных функций.[51]
Вычислительные способы предсказания белок-белковых взаимодействий
Так как до сих пор нет полных данных интерактома и не все белок-белковые взаимодействия обнаружены, при реконструкции сигнальных или метаболических карт взаимодействий используют различные вычислительные методы. Они позволяют устранить пробелы, предсказывая наличие тех или иных взаимодействий между узлами сети. С помощью вычислительных методов можно предсказать не только возможность ББВ, но также и их силу[52].
Ниже приведено несколько вычислительных подходов предсказания белок-белковых взаимодействий:
- Поиск событий слияния генов или доменов белков: слияния генов, что часто также означает слияние доменов, можно использовать для поиска функциональной связи между белками. При этом используется предположение, что слиянию этих генов в течение эволюции способствовал отбор[53].
- Методы сравнительной геномики и кластеризации генов: часто гены, которые кодируют белки со схожей функцией или взаимодействующие друг с другом белки, находятся в одном опероне (в случае бактерий) или совместно регулируются (корегуляция) (в случае эукариот). Такие гены обычно близко расположены в геноме. Методы кластеризации генов оценивают вероятность совместной встречаемости ортологов белков, которые кодируют гены из одного кластера. Такие подходы помогают выявлять скорее функциональное взаимодействие между белками, чем их физический контакт[52].
- Методы, основанные на филогенетических профилях: в таких методах предполагают, что если негомологичные белки функционально связаны, то существует вероятность того, что они могут вступать в ББВ и коэволюционировать. Для того чтобы найти функциональную связь между белками, используют кластеризацию по филогенетическим профилям этих белков или же оценивают вероятность совместной встречаемости белков в различных протеомах[52]. Идея того, что у взаимодействующих друг с другом белков часто схожие по топологии филогенетические деревья, используется в методе «mirror tree»[54].
- Способы предсказания на основе гомологии: данный подход предполагает, что исследуемые белки будут взаимодействовать друг с другом, если известно, что их гомологи вступают во взаимодействие. Такие пары белков из разных организмов, которые сохранили в течение эволюции способность взаимодействовать друг с другом, называются интерологами. Примерами сервисов, использующих данный метод, являются PPISearch и BIPS[52].
- Предсказание, основанное на данных коэкспрессии генов: если исследуемые белки кодируют гены с похожими паттернами экспрессии (схожий профиль и уровень экспрессии) в разные временные промежутки, то можно предположить, что эти белки функционально связаны и, возможно, как-то взаимодействуют друг с другом[55].
- Методы на основе сетевой топологии: сети ББВ можно представить в виде графа, где узлами являются белки, а каждое ребро обозначает взаимодействие между белками. С помощью математической интерпретации сети ББВ (например, в виде матрицы смежности) можно определить, как белки функционально связаны между собой, а также предсказать новые ББВ. Если у двух белков очень много общих партнёров в сети, то скорее всего они принимают участие в одном биологическом процессе и потенциально могут взаимодействовать друг с другом[52].
- In-Silico Two-Hybrid подход: главное предположение данного метода — взаимодействующие друг с другом белки коэволюционируют, чтобы сохранить функциональность. Данный метод анализирует множественные выравнивания белкового семейства и ищет скоррелированные мутации для предсказания ББВ и поиска оснований, входящих в участок связывания[56].
- Предсказание ББВ, основанное на структуре белков: такой подход позволяет не только выяснить, могут ли белки взаимодействовать, но и охарактеризовать это взаимодействие (например, его физические характеристики или аминокислоты, входящие в состав поверхности взаимодействия двух белков). Одним из методов, использующих трёхмерную структуру белков, является докинг. Сюда же относят методы, которые предполагают эволюционную консервативность оснований, входящих в состав поверхности взаимодействия. Таким образом, на основе уже известных структур можно предсказать, как будет выглядеть мультимолекулярный комплекс исследуемых белков[52].
- Методы, основанные на машинном обучении или интеллектуальном анализе текста: на основе машинного обучения был разработан метод предсказания ББВ, который использует только последовательности исследуемых белков[57]. Это позволяет проанализировать, хотя и менее точно, бóльшее число возможных взаимодействий, так как для работы используются только аминокислотные последовательности. Интеллектуальный анализ текста ищет связь между белками, рассматривая их взаимное упоминание в предложениях или параграфах различных текстовых блоков[58].
CASP
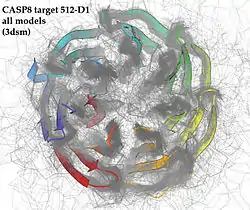
CASP (от англ. Critical Assessment of protein Structure Prediction — критическая оценка предсказания белковых структур) — масштабный эксперимент по предсказанию белковых структур. Проходит с 1994 года с периодичностью каждые два года[59]. CASP объективно тестирует методы предсказания белковых структур и предоставляет независимую оценку структурного моделирования. Основная цель CASP — помощь в улучшении методов определения трёхмерной структуры белков из их аминокислотных последовательностей. Более 100 исследовательских групп принимают участие в проекте на постоянной основе. Один из главных принципов CASP — отсутствие у участников какой-либо предварительной информации о белке, кроме аминокислотной последовательности. По этой причине в CASP используется двойной слепой метод — ни организаторы, ни эксперты, ни участники не знают структуры тестируемых белков до окончания стадии предсказаний. Тестируемые белки — чаще всего ещё не разрешённые структуры, полученные методами рентгеноструктурного анализа и ЯМР[60].
Данное мероприятие помогает сравнить передовые методы предсказания структур белков и поиск «идеального» алгоритма, который лишь по аминокислотной последовательности сможет предсказывать третичную структуру белка[61].
На последнем CASP13 победила команда, которая использовала нейронную сеть AlphaFold. Так что, скорее всего, предсказание структур белков в будущем будут делать, используя именно нейронные сети[62].
Foldit

Фолдит — онлайн-головоломка об укладке белка. Игра является частью исследовательского проекта и разработана в Вашингтонском университете. Предмет игры — наилучшим образом свернуть структуру выбранных белков; лучшие пользовательские решения анализируются учёными, которые могут с их помощью найти решение реальных научных проблем, связанных с поиском вакцин и биологическими инновациями. Большинство из лучших игроков «Фолдита» не имеют биохимического образования[63].
Целью данной игры является в предсказание трёхмерной структуры определённого белка с самым низким уровнем свободной энергии[64]. Каждое задание публикуется на сайте на определённый срок, в течение которого пользователи соревнуются между собой.
Во время игры игроки интерактивно манипулируют молекулой, меняя углы остова белка и также расположение радикалов аминокислот. Игроки способны устанавливать ограничения на определённых участках («rubber bands») или «замораживать» их. Также пользователям предоставляется панель инструментов для выполнения автоматизированных задач, например, команда «wiggle» позволяет локально минимизировать энергию.
Пользователь получает информацию о том, насколько хорошо ему удаётся сворачивать белок, в форме баллов, которые начисляются, в частности, за образование новых водородных связей, сокрытие гидрофобных остатков внутрь молекулы и т. д. Также программа даёт игрокам подсказки, например подсвечивает участки, в которых определённые группы перекрываются и их следует развести, открытые гидрофобные участки, которые следует скрыть от воздействия воды и т. д. Сайт позволяет пользователям делиться друг с другом вариантами решений, обсуждать их[63].
История
Одним из первых алгоритмов предсказания вторичной структуры белка был метод Чоу-Фасмана (англ. Chou–Fasman method), опирающийся в первую очередь на вероятностные параметры, определённые с помощью относительных частот возникновения каждой аминокислоты в каждом типе вторичных структур[21]. Точность метода Чоу-Фасмана составляет около 50—60 %[65].
Следующей примечательной программой был метод GOR, названный по первым буквам фамилий его разработчиков, — метод, основанный на теории информации[66]. Он использует вероятностный метод байесовского вывода[66]. Метод GOR учитывает не только вероятность того, что аминокислота определённого типа включена в определённую вторичную структуру, но и условную вероятность того, что аминокислота включена в эту вторичную структуру с учётом вклада её соседей (при этом не предполагается, что соседи имеют такую же структуру)[66]. Первоначальный метод GOR обладал точностью около 65 % и был значительно более успешен в предсказании альфа-спиралей, нежели чем бета-листов, которые он часто неверно предсказывал как петли или неорганизованные участки[65].
Ещё одним большим шагом вперёд стало использование методов машинного обучения: первые методы нейронных сетей были использованы в программах для предсказания вторичных структур белков. В качестве обучающих выборок они использовали последовательности белков с экспериментально полученными структурами для определения общих мотивов, связанных с определённым расположением вторичных структур[67]. Эти методы более чем на 70 % точны в своих предсказаниях, хотя количество бета-тяжей так же часто занижается из-за отсутствия информации о трёхмерной структуре, которая позволила бы оценить паттерны водородных связей, которые могут способствовать формированию бета-листа[65]. PSIPRED и JPRED являются одними из самых известных программ для предсказания вторичной структуры белка, основанных на нейронных сетях[68][69]. Позже метод опорных векторов оказался особенно полезным для предсказания поворотов, которые трудно идентифицировать статистическими методами[70][71].
Расширения методов машинного обучения используются для предсказания более точных локальных свойств белков, таких как торсионные углы остова в областях с неклассифицированной структурой. И метод опорных векторов, и нейронные сети были использованы для решения этой проблемы[70][72][73]. Совсем недавно программа SPINE-X позволила точно прогнозировать реальные торсионные углы и успешно использовать эту информацию для прогнозирования структуры ab initio[74].
Примечания
- Zaki, M. J., Bystroff, C. Protein structure prediction, Humana Press, 2008, 337 p. Фрагмент текста на Google Books
- Yang Y., Gao J., Wang J., Heffernan R., Hanson J., Paliwal K., Zhou Y. Sixty-five years of the long march in protein secondary structure prediction: the final stretch? (англ.) // Briefings In Bioinformatics. — 2018. — 1 May (vol. 19, no. 3). — P. 482—494. — doi:10.1093/bib/bbw129. — PMID 28040746.
- Anfinsen C. B. Principles that Govern the Folding of Protein Chains (англ.) // Science. — 1973. — 20 July (vol. 181, no. 4096). — P. 223—230. — ISSN 0036-8075. — doi:10.1126/science.181.4096.223.
- Li Bian, Fooksa Michaela, Heinze Sten, Meiler Jens. Finding the needle in the haystack: towards solving the protein-folding problem computationally (англ.) // Critical Reviews in Biochemistry and Molecular Biology. — 2017. — 4 October (vol. 53, no. 1). — P. 1—28. — ISSN 1040-9238. — doi:10.1080/10409238.2017.1380596.
- Zhang Yang. Progress and challenges in protein structure prediction (англ.) // Current Opinion in Structural Biology. — 2008. — June (vol. 18, no. 3). — P. 342—348. — ISSN 0959-440X. — doi:10.1016/j.sbi.2008.02.004.
- Фундаментальная «проблема белка» решена. Ученые бились над ней полвека, а помогли им в итоге программисты Google — и это может быть очень важно для медицины, meduza.io, 13 декабря 2020 года.
- Richardson Jane S. The Anatomy and Taxonomy of Protein Structure (англ.) // Advances in Protein Chemistry Volume 34. — 1981. — P. 167—339. — ISBN 9780120342341. — ISSN 0065-3233. — doi:10.1016/S0065-3233(08)60520-3.
- Pace C. N., Scholtz J. M. A helix propensity scale based on experimental studies of peptides and proteins. (англ.) // Biophysical Journal. — 1998. — July (vol. 75, no. 1). — P. 422—427. — doi:10.1016/s0006-3495(98)77529-0. — PMID 9649402.
- Nick Pace C., Martin Scholtz J. A Helix Propensity Scale Based on Experimental Studies of Peptides and Proteins (англ.) // Biophysical Journal. — 1998. — July (vol. 75, no. 1). — P. 422—427. — ISSN 0006-3495. — doi:10.1016/s0006-3495(98)77529-0.
- Chothia C. Conformation of twisted beta-pleated sheets in proteins. (англ.) // Journal Of Molecular Biology. — 1973. — 5 April (vol. 75, no. 2). — P. 295—302. — doi:10.1016/0022-2836(73)90022-3. — PMID 4728692.
- Richardson J. S., Richardson D. C. Natural beta-sheet proteins use negative design to avoid edge-to-edge aggregation. (англ.) // Proceedings Of The National Academy Of Sciences Of The United States Of America. — 2002. — 5 March (vol. 99, no. 5). — P. 2754—2759. — doi:10.1073/pnas.052706099. — PMID 11880627.
- Финкельштейн А. В., Птицын О. Б. Вторичные структуры полипептидных цепей // Физика белка. — Москва: КДУ, 2005. — С. 86—95. — ISBN 5-98227-065-2.
- Choi Yoonjoo, Agarwal Sumeet, Deane Charlotte M. How long is a piece of loop? (англ.) // PeerJ. — 2013. — 12 February (vol. 1). — P. e1. — ISSN 2167-8359. — doi:10.7717/peerj.1.
- What are macromolecular structures?
- tertiary structure // IUPAC, 1996, 68, 2193. (Basic terminology of stereochemistry (IUPAC Recommendations 1996)) on page 2220, IUPAC Gold Book.
- Clarke, Jeremy M. Berg; John L. Tymoczko; Lubert Stryer. Web content by Neil D. Section 3.5Quaternary Structure: Polypeptide Chains Can Assemble Into Multisubunit Structures // Biochemistry. — 5. ed., 4. print.. — New York, NY [u.a.]: W. H. Freeman, 2002. — ISBN 0-7167-3051-0.
- Chou, Kuo-Chen; Cai, Yu-Dong. Predicting protein quaternary structure by pseudo amino acid composition (англ.) // Proteins: Structure, Function, and Bioinformatics : journal. — 2003. — 1 November (vol. 53, no. 2). — P. 282—289. — doi:10.1002/prot.10500. — PMID 14517979.
- Yang Yuedong, Gao Jianzhao, Wang Jihua, Heffernan Rhys, Hanson Jack, Paliwal Kuldip, Zhou Yaoqi. Sixty-five years of the long march in protein secondary structure prediction: the final stretch? (англ.) // Briefings in Bioinformatics. — 2016. — 31 December. — P. bbw129. — ISSN 1467-5463. — doi:10.1093/bib/bbw129.
- Wolfgang Kabsch, Christian Sander. Dictionary of protein secondary structure: Pattern recognition of hydrogen-bonded and geometrical features // Biopolymers. — 1983-12. — Т. 22, вып. 12. — С. 2577–2637. — ISSN 1097-0282 0006-3525, 1097-0282. — doi:10.1002/bip.360221211.
- Xu, Ying, Xu, Dong, Liang, Jie. Computational Methods for Protein Structure Prediction and Modeling : Volume 1: Basic Characterization. — 2007. — ISBN 978-0-387-68372-0.
- Chou Peter Y., Fasman Gerald D. Prediction of protein conformation (англ.) // Biochemistry. — 1974. — 15 January (vol. 13, no. 2). — P. 222—245. — ISSN 0006-2960. — doi:10.1021/bi00699a002.
- Asaf A. Salamov, Victor V. Solovyev. Prediction of Protein Secondary Structure by Combining Nearest-neighbor Algorithms and Multiple Sequence Alignments // Journal of Molecular Biology. — 1995-03. — Т. 247, вып. 1. — С. 11–15. — ISSN 0022-2836. — doi:10.1006/jmbi.1994.0116.
- Daniel W A Buchan, David T Jones. The PSIPRED Protein Analysis Workbench: 20 years on // Nucleic Acids Research. — 2019-04-26. — Т. 47, вып. W1. — С. W402–W407. — ISSN 1362-4962 0305-1048, 1362-4962. — doi:10.1093/nar/gkz297.
- David T Jones. Protein secondary structure prediction based on position-specific scoring matrices 1 1Edited by G. Von Heijne // Journal of Molecular Biology. — 1999-09. — Т. 292, вып. 2. — С. 195–202. — ISSN 0022-2836. — doi:10.1006/jmbi.1999.3091.
- Kiyoshi Asai, Satoru Hayamizu, Ken'ichi Handa. Prediction of protein secondary structure by the hidden Markov model // Bioinformatics. — 1993. — Т. 9, вып. 2. — С. 141–146. — ISSN 1460-2059 1367-4803, 1460-2059. — doi:10.1093/bioinformatics/9.2.141.
- Pirovano Walter, Heringa Jaap. Protein Secondary Structure Prediction (англ.) // Methods in Molecular Biology. — 2009. — 30 October. — P. 327—348. — ISBN 9781603272407. — ISSN 1064-3745. — doi:10.1007/978-1-60327-241-4_19.
- Bioinformatics / Shui Qing Ye. — Chapman and Hall/CRC, 2007-08-20. — ISBN 978-0-429-14203-1.
- Seung Hwan Hong, Keehyoung Joo, Jooyoung Lee. ConDo: protein domain boundary prediction using coevolutionary information (англ.) // Bioinformatics. — 2019-07-15. — Vol. 35, iss. 14. — P. 2411—2417. — ISSN 1367-4803. — doi:10.1093/bioinformatics/bty973.
- Ovchinnikov S, Kim De, Wang Ry, Liu Y, DiMaio F, Baker D. Improved De Novo Structure Prediction in CASP11 by Incorporating Coevolution Information Into Rosetta (англ.). Proteins (сентябрь 2016). Дата обращения: 13 апреля 2020.
- Dong Xu, Lukasz Jaroszewski, Zhanwen Li, Adam Godzik. AIDA: ab initio domain assembly for automated multi-domain protein structure prediction and domain–domain interaction prediction (англ.) // Bioinformatics. — 2015-07-01. — Vol. 31, iss. 13. — P. 2098—2105. — ISSN 1367-4803. — doi:10.1093/bioinformatics/btv092.
- Bian Lia et al. Finding the needle in the haystack: towards solving the proteinfolding problem computationally (англ.) // Crit Rev Biochem Mol Biol : journal. — 2018. — Vol. 52, no. 1. — P. 1—28. — doi:10.1080/10409238.2017.1380596.
- Philip Hunter. Into the fold. Advances in technology and algorithms facilitate great strides in protein structure prediction // EMBO reports. — 2006-03. — Т. 7, вып. 3. — С. 249–252. — ISSN 1469-221X. — doi:10.1038/sj.embor.7400655.
- Ulrike Göbel, Chris Sander, Reinhard Schneider, Alfonso Valencia. Correlated mutations and residue contacts in proteins (англ.) // Proteins: Structure, Function, and Bioinformatics. — 1994. — Vol. 18, iss. 4. — P. 309—317. — ISSN 1097-0134. — doi:10.1002/prot.340180402.
- William R. Taylor, Kerr Hatrick. Compensating changes in protein multiple sequence alignments (англ.) // Protein Engineering, Design and Selection. — 1994-03-01. — Vol. 7, iss. 3. — P. 341—348. — ISSN 1741-0126. — doi:10.1093/protein/7.3.341.
- Debora S. Marks, Lucy J. Colwell, Robert Sheridan, Thomas A. Hopf, Andrea Pagnani. Protein 3D Structure Computed from Evolutionary Sequence Variation (англ.) // PLOS One. — Public Library of Science, 2011-07-12. — Vol. 6, iss. 12. — P. e28766. — ISSN 1932-6203. — doi:10.1371/journal.pone.0028766.
- Lukas Burger, Erik van Nimwegen. Disentangling Direct from Indirect Co-Evolution of Residues in Protein Alignments (англ.) // PLOS Computational Biology. — 2010-01-01. — Vol. 6, iss. 1. — P. e1000633. — ISSN 1553-7358. — doi:10.1371/journal.pcbi.1000633.
- Faruck Morcos, Andrea Pagnani, Bryan Lunt, Arianna Bertolino, Debora S. Marks. Direct-coupling analysis of residue coevolution captures native contacts across many protein families (англ.) // Proceedings of the National Academy of Sciences. — National Academy of Sciences, 2011-12-06. — Vol. 108, iss. 49. — P. E1293–E1301. — ISSN 1091-6490 0027-8424, 1091-6490. — doi:10.1073/pnas.1111471108.
- Timothy Nugent, David T. Jones. Accurate de novo structure prediction of large transmembrane protein domains using fragment-assembly and correlated mutation analysis (англ.) // Proceedings of the National Academy of Sciences. — National Academy of Sciences, 2012-06-12. — Vol. 109, iss. 24. — P. E1540–E1547. — ISSN 1091-6490 0027-8424, 1091-6490. — doi:10.1073/pnas.1120036109.
- Yang Zhang. Progress and challenges in protein structure prediction (англ.) // Current Opinion in Structural Biology. — Elsevier, 2008-06-01. — Vol. 18, iss. 3. — P. 342—348. — ISSN 0959-440X. — doi:10.1016/j.sbi.2008.02.004.
- Bian Li, Michaela Fooksa, Sten Heinze, Jens Meiler. Finding the needle in the haystack: towards solving the protein-folding problem computationally (англ.) // Critical Reviews in Biochemistry and Molecular Biology. — 2018-01-02. — Vol. 53, iss. 1. — P. 1–28. — ISSN 1549-7798 1040-9238, 1549-7798. — doi:10.1080/10409238.2017.1380596.
- Yang Zhang, Jeffrey Skolnick. The protein structure prediction problem could be solved using the current PDB library (англ.) // Proceedings of the National Academy of Sciences. — National Academy of Sciences, 2005-01-25. — Vol. 102, iss. 4. — P. 1029—1034. — ISSN 1091-6490 0027-8424, 1091-6490. — doi:10.1073/pnas.0407152101.
- J. U. Bowie, R. Luthy, D. Eisenberg. A method to identify protein sequences that fold into a known three-dimensional structure (англ.) // Science. — 1991-07-12. — Vol. 253, iss. 5016. — P. 164—170. — ISSN 1095-9203 0036-8075, 1095-9203. — doi:10.1126/science.1853201.
- Yo Matsuo, Haruki Nakamura, Ken Nishikawa. Detection of Protein 3D-1D Compatibility Characterized by the Evaluation of Side-Chain Packing and Electrostatic Interactions (англ.) // The Journal of Biochemistry. — 1995-07. — Vol. 118, iss. 1. — P. 137–148. — ISSN 0021-924X 1756-2651, 0021-924X. — doi:10.1093/oxfordjournals.jbchem.a124869.
- Desmet J, De Maeyer M, Hazes B, Lasters I. The Dead-End Elimination Theorem and Its Use in Protein Side-Chain Positioning (англ.). Nature (9 апреля 1992). Дата обращения: 27 апреля 2020.
- Patrice Koehl, Marc Delarue. Application of a Self-consistent Mean Field Theory to Predict Protein Side-chains Conformation and Estimate Their Conformational Entropy // Journal of Molecular Biology. — 1994-06. — Т. 239, вып. 2. — С. 249—275. — ISSN 0022-2836. — doi:10.1006/jmbi.1994.1366.
- Roland L Dunbrack. Rotamer Libraries in the 21st Century (англ.) // Current Opinion in Structural Biology. — Elsevier, 2002-08-01. — Vol. 12, iss. 4. — P. 431—440. — ISSN 0959-440X. — doi:10.1016/S0959-440X(02)00344-5.
- Jay W. Ponder, Frederic M. Richards. Tertiary templates for proteins: Use of packing criteria in the enumeration of allowed sequences for different structural classes (англ.) // Journal of Molecular Biology. — 1987-02-20. — Vol. 193, iss. 4. — P. 775—791. — ISSN 0022-2836. — doi:10.1016/0022-2836(87)90358-5.
- Simon C. Lovell, J. Michael Word, Jane S. Richardson, David C. Richardson. The penultimate rotamer library (нем.) // Proteins: Structure, Function, and Bioinformatics. — 2000. — Bd. 40, H. 3. — S. 389—408. — ISSN 1097-0134. — doi:10.1002/1097-0134(20000815)40:33.0.CO;2-2.
- Maxim V. Shapovalov, Roland L. Dunbrack. A Smoothed Backbone-Dependent Rotamer Library for Proteins Derived from Adaptive Kernel Density Estimates and Regressions (англ.) // Structure. — 2011-06-08. — Vol. 19, iss. 6. — P. 844—858. — ISSN 0969-2126. — doi:10.1016/j.str.2011.03.019.
- Andrew M. Watkins, Timothy W. Craven, P. Douglas Renfrew, Paramjit S. Arora, Richard Bonneau. Rotamer Libraries for the High-Resolution Design of β-Amino Acid Foldamers // Structure (London, England : 1993). — 2017-11-07. — Т. 25, вып. 11. — С. 1771–1780.e3. — ISSN 0969-2126. — doi:10.1016/j.str.2017.09.005.
- Thomas Lengauer, Matthias Rarey. Computational methods for biomolecular docking (англ.) // Current Opinion in Structural Biology. — 1996-06-01. — Vol. 6, iss. 3. — P. 402–406. — ISSN 0959-440X. — doi:10.1016/S0959-440X(96)80061-3.
- Keskin, O.; Tuncbag, N; Gursoy, A. Predicting Protein–Protein Interactions from the Molecular to the Proteome Level (англ.) // Chemical Reviews : journal. — 2016. — Vol. 116, no. 8. — P. 4884—4909. — PMID 27074302.
- Enright, A. J.; Iliopoulos, I.; Kyrpides, N.C.; Ouzounis, C.A. Protein Interaction Maps for Complete Genomes Based on Gene Fusion Events (англ.) // Nature : journal. — 1999. — Vol. 402, no. 6757. — P. 86—90. — PMID 10573422.
- Pazos, F.; Valencia, A. Similarity of Phylogenetic Trees as Indicator of Protein-Protein Interaction (англ.) // Protein Eng., Des. Sel. : journal. — 2001. — Vol. 14, no. 9. — P. 609—614. — PMID 11707606.
- Jansen, R.; IGreenbaum, D.; Gerstein, M. Relating Whole- Genome Expression Data with Protein-Protein Interactions (англ.) // Genome Res. : journal. — 2002. — Vol. 12, no. 1. — P. 37—46. — PMID 11779829.
- Pazos, F.; Valencia, A. In Silico Two-Hybrid System for the Selection of Physically Interacting Protein Pairs (англ.) // Proteins: Struct., Funct., Genet. : journal. — 2002. — Vol. 47, no. 2. — P. 219—227. — PMID 11933068.
- Shen, J.; IZhang, J.; Luo, X.; Zhu, W.; Yu, K.; Chen, K.; Li, Y.; Jiang, H. Predicting protein-protein interactions based only on sequences information (англ.) // Proceedings of the National Academy of Sciences of the United States of America : journal. — 2007. — Vol. 104, no. 11. — P. 4337—4341. — PMID 17360525.
- Papanikolaou, N.; Pavlopoulos, G.A.; Theodosiou, T.; Iliopoulos, I. Protein-protein interaction predictions using text mining methods (англ.) // Methods : journal. — 2015. — Vol. 74. — P. 47—53. — PMID 25448298.
- Moult John, Pedersen Jan T., Judson Richard, Fidelis Krzysztof. A large-scale experiment to assess protein structure prediction methods (англ.) // Proteins: Structure, Function, and Genetics. — 1995. — November (vol. 23, no. 3). — P. ii—iv. — ISSN 0887-3585. — doi:10.1002/prot.340230303.
- Moult J., Pedersen J. T., Judson R., Fidelis K. A large-scale experiment to assess protein structure prediction methods. (англ.) // Proteins. — 1995. — November (vol. 23, no. 3). — doi:10.1002/prot.340230303. — PMID 8710822.
- Ben-David M., Noivirt-Brik O., Paz A., Prilusky J., Sussman J. L., Levy Y. Assessment of CASP8 structure predictions for template free targets. (англ.) // Proteins. — 2009. — Vol. 77 Suppl 9. — P. 50—65. — doi:10.1002/prot.22591. — PMID 19774550.
- Google's DeepMind predicts 3D shapes of proteins, The Guardian (2 декабря 2018). Дата обращения 19 июля 2019.
- Cooper S., Khatib F., Treuille A., Barbero J., Lee J., Beenen M., Leaver-Fay A., Baker D., Popović Z., Players F. Predicting protein structures with a multiplayer online game (англ.) // Nature : journal. — 2010. — Vol. 466. — P. 756—760. — doi:10.1038/nature09304. — PMID 20686574.
- Good B.M., Su A.I. Games with a scientific purpose // Genome Biol.. — 2011. — Т. 12. — С. 135. — doi:10.1186/gb-2011-12-12-135. — PMID 22204700.
- Mount, David W. Bioinformatics : sequence and genome analysis. — 2nd ed. — Cold Spring Harbor, N.Y.: Cold Spring Harbor Laboratory Press, 2004. — xii, 692 pages с. — ISBN 0-87969-687-7, 978-0-87969-687-0, 0-87969-712-1, 978-0-87969-712-9, 978-974-652-070-6, 974-652-070-9.
- Garnier J., Osguthorpe D.J., Robson B. Analysis of the accuracy and implications of simple methods for predicting the secondary structure of globular proteins (англ.) // Journal of Molecular Biology. — 1978. — March (vol. 120, no. 1). — P. 97—120. — ISSN 0022-2836. — doi:10.1016/0022-2836(78)90297-8.
- Holley L. H., Karplus M. Protein secondary structure prediction with a neural network. (англ.) // Proceedings of the National Academy of Sciences. — 1989. — 1 January (vol. 86, no. 1). — P. 152—156. — ISSN 0027-8424. — doi:10.1073/pnas.86.1.152.
- Buchan Daniel W A, Jones David T. The PSIPRED Protein Analysis Workbench: 20 years on (англ.) // Nucleic Acids Research. — 2019. — 26 April (vol. 47, no. W1). — P. W402—W407. — ISSN 0305-1048. — doi:10.1093/nar/gkz297.
- Drozdetskiy Alexey, Cole Christian, Procter James, Barton Geoffrey J. JPred4: a protein secondary structure prediction server (англ.) // Nucleic Acids Research. — 2015. — 16 April (vol. 43, no. W1). — P. W389—W394. — ISSN 0305-1048. — doi:10.1093/nar/gkv332.
- PHAM THO HOAN, SATOU KENJI, HO TU BAO. SUPPORT VECTOR MACHINES FOR PREDICTION AND ANALYSIS OF BETA AND GAMMA-TURNS IN PROTEINS (англ.) // Journal of Bioinformatics and Computational Biology. — 2005. — April (vol. 03, no. 02). — P. 343—358. — ISSN 0219-7200. — doi:10.1142/S0219720005001089.
- Zhang Q., Yoon S., Welsh W. J. Improved method for predicting -turn using support vector machine (англ.) // Bioinformatics. — 2005. — 29 March (vol. 21, no. 10). — P. 2370—2374. — ISSN 1367-4803. — doi:10.1093/bioinformatics/bti358.
- Zimmermann O., Hansmann U. H. E. Support vector machines for prediction of dihedral angle regions (англ.) // Bioinformatics. — 2006. — 27 September (vol. 22, no. 24). — P. 3009—3015. — ISSN 1367-4803. — doi:10.1093/bioinformatics/btl489.
- Kuang R., Leslie C. S., Yang A.-S. Protein backbone angle prediction with machine learning approaches (англ.) // Bioinformatics. — 2004. — 26 February (vol. 20, no. 10). — P. 1612—1621. — ISSN 1367-4803. — doi:10.1093/bioinformatics/bth136.
- Faraggi Eshel, Yang Yuedong, Zhang Shesheng, Zhou Yaoqi. Predicting Continuous Local Structure and the Effect of Its Substitution for Secondary Structure in Fragment-Free Protein Structure Prediction (англ.) // Structure. — 2009. — November (vol. 17, no. 11). — P. 1515—1527. — ISSN 0969-2126. — doi:10.1016/j.str.2009.09.006.