Метод опорных векторов
Метод опорных векторов (англ. SVM, support vector machine) — набор схожих алгоритмов обучения с учителем, использующихся для задач классификации и регрессионного анализа. Принадлежит семейству линейных классификаторов и может также рассматриваться как частный случай регуляризации по Тихонову. Особым свойством метода опорных векторов является непрерывное уменьшение эмпирической ошибки классификации и увеличение зазора, поэтому метод также известен как метод классификатора с максимальным зазором.
Основная идея метода — перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с наибольшим зазором в этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, создающая наибольшее расстояние до двух параллельных гиперплоскостей. Алгоритм основан на допущении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
Постановка задачи
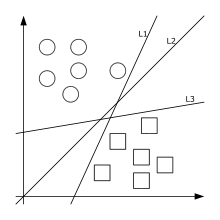
Часто в алгоритмах машинного обучения возникает необходимость классифицировать данные. Каждый объект данных представляется как вектор (точка) в -мерном пространстве (упорядоченный набор чисел). Каждая из этих точек принадлежит только одному из двух классов. Вопрос состоит в том, можно ли разделить точки гиперплоскостью размерности (−1). Это — типичный случай линейной разделимости. Искомых гиперплоскостей может быть много, поэтому полагают, что максимизация зазора между классами способствует более уверенной классификации. То есть, можно ли найти такую гиперплоскость, чтобы расстояние от неё до ближайшей точки было максимальным. Это эквивалентно[1] тому, что сумма расстояний до гиперплоскости от двух ближайших к ней точек, лежащих по разные стороны от неё, максимальна. Если такая гиперплоскость существует, она называется оптимальной разделяющей гиперплоскостью, а соответствующий ей линейный классификатор называется оптимально разделяющим классификатором.

Формальное описание задачи
Мы полагаем, что точки имеют вид:

где принимает значение 1 или −1, в зависимости от того, какому классу принадлежит точка . Каждое — это -мерный вещественный вектор, обычно нормализованный значениями или . Если точки не будут нормализованы, то точка с большими отклонениями от средних значений координат точек слишком сильно повлияет на классификатор. Мы можем рассматривать это как обучающую выборку, в которой для каждого элемента уже задан класс, к которому он принадлежит. Мы хотим, чтобы алгоритм метода опорных векторов классифицировал их таким же образом. Для этого мы строим разделяющую гиперплоскость, которая имеет вид:




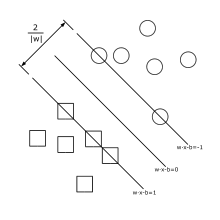

Вектор — перпендикуляр к разделяющей гиперплоскости. Параметр равен по модулю расстоянию от гиперплоскости до начала координат. Если параметр b равен нулю, гиперплоскость проходит через начало координат, что ограничивает решение.


Так как нас интересует оптимальное разделение, нас интересуют опорные вектора и гиперплоскости, параллельные оптимальной и ближайшие к опорным векторам двух классов. Можно показать, что эти параллельные гиперплоскости могут быть описаны следующими уравнениям (с точностью до нормировки).


Если обучающая выборка линейно разделима, то мы можем выбрать гиперплоскости таким образом, чтобы между ними не лежала ни одна точка обучающей выборки и затем максимизировать расстояние между гиперплоскостями. Ширину полосы между ними легко найти из соображений геометрии, она равна [2], таким образом наша задача минимизировать . Чтобы исключить все точки из полосы, мы должны убедиться для всех , что




Это может быть также записано в виде:

Случай линейной разделимости
Проблема построения оптимальной разделяющей гиперплоскости сводится к минимизации , при условии (1). Это задача квадратичной оптимизации, которая имеет вид:

По теореме Куна — Таккера эта задача эквивалентна двойственной задаче поиска седловой точки функции Лагранжа

где — вектор двойственных переменных.

Сведем эту задачу к эквивалентной задаче квадратичного программирования, содержащую только двойственные переменные:

Допустим мы решили данную задачу, тогда и можно найти по формулам:



В итоге алгоритм классификации может быть записан в виде:

При этом суммирование идёт не по всей выборке, а только по опорным векторам, для которых .

Случай линейной неразделимости
Для того, чтобы алгоритм мог работать в случае, если классы линейно неразделимы, позволим ему допускать ошибки на обучающей выборке. Введём набор дополнительных переменных , характеризующих величину ошибки на объектах . Возьмём за отправную точку (2), смягчим ограничения неравенства, так же введём в минимизируемый функционал штраф за суммарную ошибку:



Коэффициент — параметр настройки метода, который позволяет регулировать отношение между максимизацией ширины разделяющей полосы и минимизацией суммарной ошибки.

Аналогично, по теореме Куна-Таккера сводим задачу к поиску седловой точки функции Лагранжа:

По аналогии сведём эту задачу к эквивалентной:

На практике для построения машины опорных векторов решают именно эту задачу, а не (3), так как гарантировать линейную разделимость точек на два класса в общем случае не представляется возможным. Этот вариант алгоритма называют алгоритмом с мягким зазором (soft-margin SVM), тогда как в линейно разделимом случае говорят о жёстком зазоре (hard-margin SVM).
Для алгоритма классификации сохраняется формула (4), с той лишь разницей, что теперь ненулевыми обладают не только опорные объекты, но и объекты-нарушители. В определённом смысле это недостаток, поскольку нарушителями часто оказываются шумовые выбросы, и построенное на них решающее правило, по сути дела, опирается на шум.

Константу C обычно выбирают по критерию скользящего контроля. Это трудоёмкий способ, так как задачу приходится решать заново при каждом значении C.
Если есть основания полагать, что выборка почти линейно разделима, и лишь объекты-выбросы классифицируются неверно, то можно применить фильтрацию выбросов. Сначала задача решается при некотором C, и из выборки удаляется небольшая доля объектов, имеющих наибольшую величину ошибки . После этого задача решается заново по усечённой выборке. Возможно, придётся проделать несколько таких итераций, пока оставшиеся объекты не окажутся линейно разделимыми.

Ядра
Алгоритм построения оптимальной разделяющей гиперплоскости, предложенный в 1963 году Владимиром Вапником и Алексеем Червоненкисом — алгоритм линейной классификации. Однако в 1992 году Бернхард Босер, Изабель Гийон и Вапник предложили способ создания нелинейного классификатора, в основе которого лежит переход от скалярных произведений к произвольным ядрам, так называемый kernel trick (предложенный впервые М. А. Айзерманом, Э. М. Браверманом и Л. И. Розоноэром для метода потенциальных функций), позволяющий строить нелинейные разделители. Результирующий алгоритм крайне похож на алгоритм линейной классификации, с той лишь разницей, что каждое скалярное произведение в приведённых выше формулах заменяется нелинейной функцией ядра (скалярным произведением в пространстве с большей размерностью). В этом пространстве уже может существовать оптимальная разделяющая гиперплоскость. Так как размерность получаемого пространства может быть больше размерности исходного, то преобразование, сопоставляющее скалярные произведения, будет нелинейным, а значит функция, соответствующая в исходном пространстве оптимальной разделяющей гиперплоскости, будет также нелинейной.
Если исходное пространство имеет достаточно высокую размерность, то выборка может быть линейно разделимой.
Наиболее распространённые ядра:
- Полиномиальное (однородное):
- Полиномиальное (неоднородное):
- Радиальная базисная функция: , для
- Радиальная базисная функция Гаусса:
- Сигмоид: , для почти всех и








См. также
Примечания
- Вьюгин, 2013, с. 86—90.
- К. В. Воронцов. Лекции по методу опорных векторов
Литература
- Владимир Вьюгин. Математические основы теории машинного обучения и прогнозирования. — МЦМНО, 2013. — 390 с. — ISBN 978-5-4439-0111-4.
- Nello Cristianini, John Shawe-Taylor. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. — Cambridge University Press, 2000. — ISBN 978-1-139-64363-4.
- Alexander Statnikov, Constantin F. Aliferis, Douglas P. Hardin. A Gentle Introduction to Support Vector Machines in Biomedicine: Theory and methods. — World Scientific, 2011. — ISBN 978-981-4324-38-0.
- Alexey Nefedov. Support Vector Machines: A Simple Tutorial. — 2016.
Ссылки
- Data Mining. 10. Лекция: Методы классификации и прогнозирования. Метод опорных векторов // Интуит.ру
- Юрий Лифшиц. Метод опорных векторов (Слайды) — лекция № 7 из курса «Алгоритмы для Интернета»