Функция активации
В искусственных нейронных сетях функция активации нейрона определяет выходной сигнал, который определяется входным сигналом или набором входных сигналов. Стандартная компьютерная микросхема может рассматриваться как цифровая сеть функций активации, которые могут принимать значения «ON» (1) или «OFF» (0) в зависимости от входа. Это похоже на поведение линейного перцептрона в нейронных сетях. Однако только нелинейные функции активации позволяют таким сетям решать нетривиальные задачи с использованием малого числа узлов. В искусственных нейронных сетях эта функция также называется передаточной функцией.
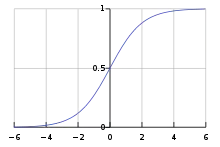
Функции
В биологических нейронных сетях функция активации обычно является абстракцией, представляющей скорость возбуждения потенциала действия в клетке [1]. В наиболее простой форме эта функция является двоичной — то есть нейрон либо возбуждается, либо нет. Функция выглядит как , где — ступенчатая функция Хевисайда. В этом случае нужно использовать много нейронов для вычислений за пределами линейного разделения категорий.


Прямая с положительным угловым коэффициентом может быть использована для отражения увеличения скорости возбуждения по мере увеличения входного сигнала. Такая функция имела бы вид , где — наклон прямой. Эта функция активации линейна, а потому имеет те же проблемы, что и двоичная функция. Кроме того, сети, построенные с использованием таковой модели, имеют нестабильную сходимость, поскольку возбуждение приоритетных входов нейронов стремится к безграничному увеличению, так как эта функция не нормализуема.


Все проблемы, упомянутые выше, можно решить с помощью нормализуемой сигмоидной функции активации. Одна из реалистичных моделей остаётся в нулевом состоянии, пока не придёт входной сигнал, в этот момент скорость возбуждения сначала быстро возрастает, но постепенно достигает асимптоты в 100 % скорости возбуждения. Математически, это выглядит как , где гиперболический тангенс можно заменить любой сигмоидой. Такое поведение реально отражается в нейроне, поскольку нейроны не могут физически возбуждаться быстрее некоторой определённой скорости. Эта модель, однако, имеет несколько проблем в вычислительных сетях, поскольку функция не дифференцируема, что нужно для вычисления обратной передачи ошибки обучения.

Последняя модель, которая используется в многослойных перцептронах — сигмоидная функция активации в форме гиперболического тангенса. Обычно используются два вида этой функции: , образ которой нормализован к интервалу [-1, 1], и , сдвинутая по вертикали для нормализации от 0 до 1. Последняя модель считается более биологически реалистичной, но имеет теоретические и экспериментальные трудности с вычислительными ошибками некоторых типов.


Альтернативные структуры
Специальный класс функций активации, известный как радиальные базисные функции (РБФ) используются в РБФ сетях, которые крайне эффективны в качестве универсальных аппроксиматоров функций. Эти функции активации могут принимать множество форм, но обычно берётся одна из следующих трёх функций:
- Гауссова:
- Мультиквадратичная (англ. Multiquadratics):
- Обратная мультиквадратичная (англ. Inverse Multiquadratics):



где является вектором, представляющим центр функции, а и являются параметрами, влияющими на расходимость радиуса.



Методы опорных векторов (SVM) могут эффективно использовать класс функций активации, который включает как сигмоиды, так и РБФ. В этом случае вход преобразуется для отражения гиперплоскости границы решений основываясь на нескольких обучающих входных данных, называемых опорными векторами . О функции активации для закрытого уровня этих машин говорят как о ядре скалярного произведения (англ. inner product kernel), . Опорные вектора представляются как центры в РБФ с ядром, равным функции активации, но они принимают единственный вид в перцептроне


- ,

где для сходимости и должны удовлетворять некоторым условиям. Эти машины могут принимать полиномиальные функции активации любого порядка


- [2].

Функции активации бывают следующих типов:
Сравнение функций активации
Некоторые желательные свойства функций активации:
- Нелинейность – Если функция активации нелинейна, можно доказать, что двухуровневая нейронная сеть будет универсальным аппроксиматором функции [5]. Тождественная функция активации не удовлетворяет этому свойству. Если несколько уровней используют тождественную функцию активации, вся сеть эквивалентна одноуровневой модели.
- Непрерывная дифференцируемость – Это свойство желательно (RELU не является непрерывно дифференцируемой и имеет некоторые проблемы с оптимизацией, основанной на градиентном спуске, но остаётся допустимой возможностью) для обеспечения методов оптимизации на основе градиентного спуска. Двоичная ступенчатая функция активации не дифференцируема в точке 0 и её производная равна 0 во всех других точках, так что методы градиентного спуска не дают никакого успеха для неё[6].
- Область значений – Если множество значений функции активации ограничено, методы обучения на основе градиента более стабильны, поскольку представления эталонов существенно влияют лишь на ограниченный набор весов связей. Если область значений бесконечна, обучение, как правило, более эффективно, поскольку представления эталонов существенно влияют на большинство весов. В последнем случае обычно необходим меньший темп обучения.
- Монотонность – Если функция активации монотонна, поверхность ошибок, ассоциированная с одноуровневой моделью, гарантированно будет выпуклой [7].
- Гладкие функции с монотонной производной – Показано, что в некоторых случаях они обеспечивают более высокую степень общности.
- Аппроксимирует тождественную функцию около начала координат – Если функции активации имеют это свойство, нейронная сеть будет обучаться эффективно, если её веса инициализированы малыми случайными значениями. Если функция активации не аппроксимирует тождество около начала координат, нужно быть осторожным при инициализации весов[8]. В таблице ниже функции активации, у которых , и непрерывна в точке 0, помечены как имеющие это свойство.



Следующая таблица сравнивает свойства некоторых функций активации, которые являются функциями одной свёртки x от предыдущего уровня или уровней:
| Название | График | Уравнение | Производная (по x) | Область значений | Порядок гладкости | Монотонная | Монотонная производная | Аппроксимирует тождественную функцию около начала координат |
|---|---|---|---|---|---|---|---|---|
| Тождественная | 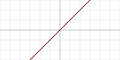 |
Да | Да | Да | ||||
| Единичная ступенька |  |
Да | Нет | Нет | ||||
| Логистическая (сигмоида или Гладкая ступенька) |  |
Да | Нет | Нет | ||||
| th | 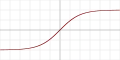 |
Да | Нет | Да | ||||
| arctg | 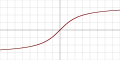 |
Да | Нет | Да | ||||
| Softsign[9][10] |  |
Да | Нет | Да | ||||
| Обратный квадратный корень (англ. Inverse square root unit, ISRU)[11] | 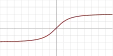 |
Да | Нет | Да | ||||
| Линейный выпрямитель (или Полулинейный элемент) |  |
Да | Да | Нет | ||||
| Линейный выпрямитель с «утечкой» (англ. Leaky rectified linear unit, Leaky ReLU)[14] |  |
Да | Да | Нет | ||||
| Параметрический линейный выпрямитель (англ. Parameteric rectified linear unit, PReLU)[15] | |
Да, когда |
Да | Да, когда | ||||
| Рандомизированный линейный выпрямитель с «утечкой» (англ. Randomized leaky rectified linear unit, RReLU)[16] | |
Да | Да | Нет | ||||
| Экспоненциальная линейная функция (англ. Exponential linear unit, ELU)[17] |  |
Да, когда |
Да, когда |
Да, когда | ||||
| Масштабированная экспоненциальная линейная функция (англ. Scaled exponential linear unit, SELU)[18] |
с и |
Да | Нет | Нет | ||||
| Линейный S-выпрямитель (англ. S-shaped rectified linear activation unit, SReLU)[19] | являются параметрами. |
Нет | Нет | Нет | ||||
| Обратный квадратный линейный корень (англ. Inverse square root linear unit, ISRLU)[11] | 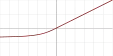 |
Да | Да | Да | ||||
| Адаптивная кусочно-линейная функция (англ. Adaptive piecewise linear, APL)[20] | Нет | Нет | Нет | |||||
| SoftPlus[21] | 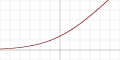 |
Да | Да | Нет | ||||
| Выгнутая тождественная функция (англ. Bent identity) | 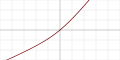 |
Да | Да | Да | ||||
| Cигмоидно-взвешенная линейная функция (англ. Sigmoid-weighted linear unit, SiLU)[22] | Нет | Нет | Нет | |||||
| SoftExponential[23] |  |
Да | Да | Да, когда | ||||
| Синусоида[24] |  |
Нет | Нет | Да | ||||
| Sinc |  |
Нет | Нет | Нет | ||||
| Гауссова |  |
Нет | Нет | Нет |








































































- ↑ Здесь, H является ступенчатой функцией Хевисайда.
- ↑ α является стохастической переменной, берущейся из равномерного распределения в момент обучения, значение которой фиксируется равным математическому ожиданию распределения в момент тестирования.
- ↑ ↑ ↑ Здесь является логистической функцией.
Следующая таблица перечисляет функции активации, которые не являются функциями от одной свёртки x от предыдущего уровня или уровней:
| Название | Уравнение | Производные | Область значений | Степень гладкости |
|---|---|---|---|---|
| Softmax | для i = 1, …, J | |||
| Maxout[25] |




↑ Здесь обозначает символ Кронекера.

См. также
- Логистическая функция
- Выпрямитель (нейронные сети)
- Устойчивость (теория обучения)
- Softmax
Примечания
- Hodgkin, Huxley, 1952, с. 500–544.
- Haykin, 1999.
- Биполярная – принимающая значение -1 до начала координат и 1 после, в отличие от двоичной ступенчатой функции, которая принимает до начала координат значения 0.)
- Функция подъёма принимает значение 0 до начала координат и линейна после.
- Cybenko, 2006, с. 303.
- Snyman, 2005.
- Wu, 2009, с. 3432–3441.
- Sussillo, David & Abbott, L. F. (2014-12-19), Random Walk Initialization for Training Very Deep Feedforward Networks, arΧiv:1412.6558 [cs.NE]
- James Bergstra, Guillaume Desjardins, Pascal Lamblin, Yoshua Bengio. Quadratic polynomials learn better image features". Technical Report 1337 (недоступная ссылка). Département d’Informatique et de Recherche Opérationnelle, Université de Montréal (2009). Дата обращения: 30 сентября 2018. Архивировано 25 сентября 2018 года.
- Glorot, Bengio, 2010.
- Carlile, Brad; Delamarter, Guy; Kinney, Paul; Marti, Akiko & Whitney, Brian (2017-11-09), Improving Deep Learning by Inverse Square Root Linear Units (ISRLUs), arΧiv:1710.09967 [cs.LG]
- По аналогии с диодом – пропускает ток (не меняя его) в одну сторону, и не пропускает в другую.
- Nair, Hinton, 2010, с. 807–814.
- Maas, Hannun, Ng, 2013.
- He, Zhang, Ren, Sun, 2015.
- Xu, Wang, Chen, Li, 2015.
- Clevert, Djork-Arné; Unterthiner, Thomas & Hochreiter, Sepp (2015-11-23), Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs), arΧiv:1511.07289 [cs.LG]
- Klambauer, Unterthiner, Mayr, Hochreiter, 2017.
- Jin, Xiaojie; Xu, Chunyan; Feng, Jiashi; Wei, Yunchao; Xiong, Junjun & Yan, Shuicheng (2015-12-22), Deep Learning with S-shaped Rectified Linear Activation Units, arΧiv:1512.07030 [cs.CV]
- Forest Agostinelli; Matthew Hoffman; Peter Sadowski & Pierre Baldi (21 Dec 2014), Learning Activation Functions to Improve Deep Neural Networks, arΧiv:1412.6830 [cs.NE]
- Xavier Glorot, Antoine Bordes, Yoshua Bengio. Deep sparse rectifier neural networks. International Conference on Artificial Intelligence and Statistics (2011).
- Elfwing, Uchibe, Doya, 2018.
- Godfrey, Gashler, 2016, с. 481–486.
- Gashler, Ashmore, 2014.
- Goodfellow, Warde-Farley, Mirza, Courville, Bengio, 2013, с. 1319–1327.
Литература
- Hodgkin A. L., Huxley A. F. A quantitative description of membrane current and its application to conduction and excitation in nerve // The Journal of Physiology. — 1952. — Т. 117, вып. 4. — С. 500–544. — PMID 12991237.
- Simon S. Haykin. [ в «Книгах Google» Neural Networks: A Comprehensive Foundation]. — Prentice Hall, 1999. — ISBN 978-0-13-273350-2.
- Cybenko G.V. [ в «Книгах Google» Approximation by Superpositions of a Sigmoidal function] // Mathematics of Control, Signals, and Systems / Jan H. van Schuppen. — Springer International, 2006. — С. 303.
- Jan Snyman. [ в «Книгах Google» Practical Mathematical Optimization: An Introduction to Basic Optimization Theory and Classical and New Gradient-Based Algorithms]. — Springer Science & Business Media, 2005. — ISBN 978-0-387-24348-1.
- Huaiqin Wu. Global stability analysis of a general class of discontinuous neural networks with linear growth activation functions // Information Sciences. — 2009. — Т. 179, вып. 19. — С. 3432–3441. — doi:10.1016/j.ins.2009.06.006.
- Xavier Glorot, Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks // International Conference on Artificial Intelligence and Statistics (AISTATS'10). — Society for Artificial Intelligence and Statistics, 2010.
- Vinod Nair, Geoffrey E. Hinton. Rectified Linear Units Improve Restricted Boltzmann Machines // 27th International Conference on International Conference on Machine Learning. — USA: Omnipress, 2010. — С. 807–814. — (ICML'10). — ISBN 9781605589077.
- Andrew L. Maas, Awni Y. Hannun, Andrew Y. Ng. Rectifier nonlinearities improve neural network acoustic models // Proc. ICML. — 2013. — Июнь (т. 30, вып. 1).
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Proceeding ICCV’15 Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). — Washington: IEEE Computer Society, 2015. — С. 1026-1034. — ISBN 978-1-4673-8391-2.
- Bing Xu, Naiyan Wang, Tianqi Chen, Mu Li. Empirical Evaluation of Rectified Activations in Convolutional Network // Computer Vision and Pattern Recognition. — 2015.
- Günter Klambauer, Thomas Unterthiner, Andreas Mayr, Sepp Hochreiter. Self-Normalizing Neural Networks // Advances in Neural Information Processing Systems. — 2017. — Июнь (т. 30, вып. 2017). — . — arXiv:1706.02515.
- Stefan Elfwing, Eiji Uchibe, Kenji Doya. Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning // Neural Networks. — 2018.
- Luke B. Godfrey, Michael S. Gashler. A continuum among logarithmic, linear, and exponential functions, and its potential to improve generalization in neural networks // 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management: KDIR. — 2016. — Февраль (т. 1602). — . — arXiv:1602.01321.
- Michael S. Gashler, Stephen C. Ashmore. Training Deep Fourier Neural Networks To Fit Time-Series Data // International Conference on Intelligent Computing. — Springrt, Cham, 2014. — С. 48-55.
- Ian J. Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio. Maxout Networks // JMLR Workshop and Conference Proceedings. — 2013. — Т. 28, вып. 3. — С. 1319–1327. — . — arXiv:1302.4389.