Ограниченная машина Больцмана
Ограниченная машина Больцмана (англ. restricted Boltzmann machine), сокращённо RBM — вид генеративной стохастической нейронной сети, которая определяет распределение вероятности на входных образцах данных.
Первая ограниченная машина Больцмана была построена в 1986 году Полом Смоленски под названием Harmonium[1], но приобрела популярность только после изобретения Хинтоном быстрых алгоритмов обучения в середине 2000-х годов.
Такое название машина приобрела как модификация обычной машины Больцмана, в которой нейроны разделили на видимые и скрытые, а связи допустимы только между нейронами разного типа, таким способом ограничив связи. Значительно позже, в 2000-х годах, ограниченные машины Больцмана приобрели большую популярность и стали рассматриваться уже не как вариации машины Больцмана, а как особые компоненты в архитектуре сетей глубинного обучения. Объединение нескольких каскадов ограниченных машин Больцмана формирует глубокую сеть доверия, особый вид многослойных нейронных сетей, которые могут самообучаться без учителя при помощи алгоритма обратного распространения ошибки[2].
Особенностью ограниченных машин Больцмана является возможность проходить обучение без учителя, но в определённых приложениях ограниченные машины Больцмана обучаются с учителем. Скрытый слой машины представляет собой глубокие признаки в данных, которые выявляются в процессе обучения (см. также Data mining).
Ограниченные машины Больцмана имеют широкий спектр применений — это задачи снижения размерности данных[3], задачи классификации[4], коллаборативная фильтрация[5], выделение признаков (англ. feature learning)[6] и тематическое моделирование[7].
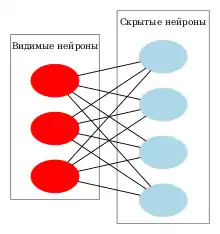
В ограниченной машине Больцмана нейроны образуют двудольный граф, с одной стороны графа находятся видимые нейроны (вход), а с другой стороны — скрытые, причём перекрёстные связи устанавливаются между каждым видимым и каждым скрытым нейроном. Такая система связей позволяет применить при обучении сети метод градиентного спуска с контрастивной дивергенцией[8].
Структура сети
Ограниченная машина Больцмана базируется на бинарных элементах с распределением Бернулли, составляющие видимый и скрытый слои сети. Связи между слоями задаются с помощью матрицы весов (размера m × n), а также смещений для видимого слоя и для скрытого слоя.





Вводится понятие энергии сети (v, h) как

или в матричной форме

Подобной функцией энергии обладает также Сеть Хопфилда. Как и для обычной машины Больцмана, через энергию определяется вероятность распределения на векторах видимого и скрытого слоя[9]:

где — статсумма, определяемая как для всех возможных сетей (иными словами, — константа нормализации, которая гарантирует, что сумма всех вероятностей равна единице). Определение вероятности для отдельного входного вектора (маргинальное распределение) проводится аналогично через сумму конфигураций всевозможных скрытых слоёв[9]:



По причине структуры сети как двудольного графа, отдельные элементы скрытого слоя независимы друг от друга и активируют видимый слой, и наоборот отдельные элементы видимого слоя независимы друг от друга и активируют скрытый слой[8]. Для видимых элементов и для скрытых элементов условные вероятности v определяются через произведения вероятностей h:



и наоборот условные вероятности h определяются через произведение вероятностей v:

Конкретные вероятности активации для одного элемента определяются как
- и


где — логистическая функция для активации слоя.

Видимые слои могут иметь также мультиномиальное распределение, в то время как скрытые слои распределены по Бернулли. В случае мультиномиальности вместо логистической функции используется softmax:

где K — количество дискретных значений видимых элементов. Такое представление используется в задачах тематического моделирования[7] и в рекомендательных системах[5].
Связь с другими моделями
Ограниченная машина Больцмана представляет собой частный случай обычной машины Больцмана и марковской сети[10][11]. Их графовая модель соответствует графовой модели факторного анализа[12].
Алгоритм обучения
Целью обучения является максимизация вероятности системы с заданным набором образцов (матрицы, в которой каждая строка соответствует одному образцу видимого вектора ), определяемой как произведение вероятностей



или же, что одно и то же, максимизации логарифма произведения:[10][11]

Для тренировки нейронной сети используется алгоритм контрастивной дивергенции (CD) с целью нахождения оптимальных весов матрицы , его предложил Джеффри Хинтон, первоначально для обучения моделей PoE («произведение экспертных оценок»)[13][14]. Алгоритм использует семплирование по Гиббсу для организации процедуры градиентного спуска, аналогично методу обратного распространения ошибок для нейронных сетей.

В целом один шаг контрастивной дивергенции (CD-1) выглядит следующим образом:
- Для одного образца данных v вычисляются вероятности скрытых элементов и применяется активация для скрытого слоя h для данного распределения вероятностей.
- Вычисляется внешнее произведение (семплирование) для v и h, которое называют позитивным градиентом.
- Через образец h проводится реконструкция образца видимого слоя v', а потом выполняется снова семплирование с активацией скрытого слоя h'. (Этот шаг называется Семплирование по Гиббсу.)
- Далее вычисляется внешнее произведение, но уже векторов v' и h', которое называют негативным градиентом.
- Матрица весов поправляется на разность позитивного и негативного градиента, помноженного на множитель, задающий скорость обучения: .
- Вносятся поправки в биасы a и b похожим способом: , .



Практические указания по реализации процесса обучения можно найти на личной странице Джеффри Хинтона[9].
См. также
- Автокодировщик
- Глубокое обучение
- Машина Гельмгольца
- Сеть Хопфилда
Ссылки
- Smolensky, Paul. Chapter 6: Information Processing in Dynamical Systems: Foundations of Harmony Theory // Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations (англ.) / Rumelhart, David E.; McLelland, James L.. — MIT Press, 1986. — P. 194—281. — ISBN 0-262-68053-X. Архивированная копия (недоступная ссылка). Дата обращения: 10 ноября 2017. Архивировано 13 июня 2013 года.
- Hinton, G. Deep belief networks (неопр.) // Scholarpedia. — 2009. — Т. 4, № 5. — С. 5947. — doi:10.4249/scholarpedia.5947.
- Hinton, G. E.; Salakhutdinov, R. R. Reducing the Dimensionality of Data with Neural Networks (англ.) // Science : journal. — 2006. — Vol. 313, no. 5786. — P. 504—507. — doi:10.1126/science.1127647. — PMID 16873662.
- (2008) «Classification using discriminative restricted Boltzmann machines» in Proceedings of the 25th international conference on Machine learning - ICML '08.: 536. DOI:10.1145/1390156.1390224.
- (2007) «Restricted Boltzmann machines for collaborative filtering» in Proceedings of the 24th international conference on Machine learning - ICML '07.: 791. DOI:10.1145/1273496.1273596.
- (2011) «An analysis of single-layer networks in unsupervised feature learning» in International Conference on Artificial Intelligence and Statistics (AISTATS)..
- Ruslan Salakhutdinov and Geoffrey Hinton (2010). Replicated softmax: an undirected topic model Архивная копия от 25 мая 2012 на Wayback Machine. Neural Information Processing Systems 23
- Miguel Á. Carreira-Perpiñán and Geoffrey Hinton (2005). On contrastive divergence learning. Artificial Intelligence and Statistics.
- Geoffrey Hinton (2010). A Practical Guide to Training Restricted Boltzmann Machines. UTML TR 2010—003, University of Toronto.
- Sutskever, Ilya; Tieleman, Tijmen. On the convergence properties of contrastysive divergence (англ.) // Proc. 13th Int'l Conf. on AI and Statistics (AISTATS) : journal. — 2010. Архивировано 10 июня 2015 года.
- Asja Fischer and Christian Igel. Training Restricted Boltzmann Machines: An Introduction. Архивная копия от 10 июня 2015 на Wayback Machine. Pattern Recognition 47, p. 25—39, 2014.
- María Angélica Cueto; Jason Morton; Bernd Sturmfels. Geometry of the restricted Boltzmann machine (неопр.) // Algebraic Methods in Statistics and Probability. — American Mathematical Society, 2010. — Т. 516. — arXiv:0908.4425. (недоступная ссылка)
- Geoffrey Hinton (1999). Products of Experts. ICANN 1999.
- Hinton, G. E. Training Products of Experts by Minimizing Contrastive Divergence (англ.) // Neural Computation : journal. — 2002. — Vol. 14, no. 8. — P. 1771—1800. — doi:10.1162/089976602760128018. — PMID 12180402.
Литература
- Introduction to Restricted Boltzmann Machines. Edwin Chen’s blog, July 18, 2011.
- A Beginner’s Guide to Restricted Boltzmann Machines. Deeplearning4j Documentation
- Understanding RBMs. Deeplearning4j Documentation, August 4, 2015.
- Python implementation of Bernoulli RBM and tutorial
- SimpleRBM is a very small RBM code (24kB) useful for you to learn about how RBMs learn.