Логистическая регрессия
Логистическая регрессия или логит-модель (англ. logit model) — статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём его сравнения с логистической кривой. Эта регрессия выдаёт ответ в виде вероятности бинарного события (1 или 0).
Описание
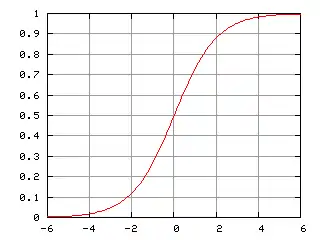

Логистическая регрессия применяется для прогнозирования вероятности возникновения некоторого события по значениям множества признаков. Для этого вводится так называемая зависимая переменная , принимающая лишь одно из двух значений — как правило, это числа 0 (событие не произошло) и 1 (событие произошло), и множество независимых переменных (также называемых признаками, предикторами или регрессорами) — вещественных , на основе значений которых требуется вычислить вероятность принятия того или иного значения зависимой переменной. Как и в случае линейной регрессии, для простоты записи вводится фиктивный признак



Делается предположение о том, что вероятность наступления события равна:


где , и — векторы-столбцы значений независимых переменных и параметров (коэффициентов регрессии) — вещественных чисел , соответственно, а — так называемая логистическая функция (иногда также называемая сигмоидом или логит-функцией):







Так как принимает лишь значения 0 и 1, то вероятность принять значение 0 равна:

Для краткости функцию распределения при заданном можно записать в таком виде:

Фактически, это есть распределение Бернулли с параметром, равным .

Подбор параметров
Для подбора параметров необходимо составить обучающую выборку, состоящую из наборов значений независимых переменных и соответствующих им значений зависимой переменной . Формально, это множество пар , где — вектор значений независимых переменных, а — соответствующее им значение . Каждая такая пара называется обучающим примером.



Обычно используется метод максимального правдоподобия, согласно которому выбираются параметры , максимизирующие значение функции правдоподобия на обучающей выборке:

Максимизация функции правдоподобия эквивалентна максимизации её логарифма:
- , где


Для максимизации этой функции может быть применён, например, метод градиентного спуска. Он заключается в выполнении следующих итераций, начиная с некоторого начального значения параметров :

На практике также применяют метод Ньютона и стохастический градиентный спуск.
Регуляризация
Для улучшения обобщающей способности получающейся модели, то есть уменьшения эффекта переобучения, на практике часто рассматривается логистическая регрессия с регуляризацией.
Регуляризация заключается в том, что вектор параметров рассматривается как случайный вектор с некоторой заданной априорной плотностью распределения . Для обучения модели вместо метода наибольшего правдоподобия при этом используется метод максимизации апостериорной оценки, то есть ищутся параметры , максимизирующие величину:


В качестве априорного распределения часто выступает многомерное нормальное распределение с нулевым средним и матрицей ковариации , соответствующее априорному убеждению о том, что все коэффициенты регрессии должны быть небольшими числами, идеально — многие малозначимые коэффициенты должны быть нулями. Подставив плотность этого априорного распределения в формулу выше, и прологарифмировав, получим следующую оптимизационную задачу:



где — параметр регуляризации. Этот метод известен как L2-регуляризованная логистическая регрессия, так как в целевую функцию входит L2-норма вектора параметров для регуляризации.

Если вместо L2-нормы использовать L1-норму, что эквивалентно использованию распределения Лапласа, как априорного, вместо нормального, то получится другой распространённый вариант метода — L1-регуляризованная логистическая регрессия:

Применение
Эта модель часто применяется для решения задач классификации — объект можно отнести к классу , если предсказанная моделью вероятность , и к классу в противном случае. Получающиеся при этом правила классификации являются линейными классификаторами.


Связанные методы
На логистическую регрессию очень похожа пробит-регрессия, отличающаяся от неё лишь другим выбором функции . Softmax-регрессия обобщает логистическую регрессию на случай многоклассовой классификации, то есть когда зависимая переменная принимает более двух значений. Все эти модели в свою очередь являются представителями широкого класса статистических моделей — обобщённых линейных моделей.
См. также
Литература
- Andrew Ng. Stanford CS229 Lecture Notes
| Вычислительная статистика |
| ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Корреляция и зависимость |
| ||||||||
| Регрессионный анализ |
| ||||||||
| Регрессия как статистическая модель |
| ||||||||
| Разложение дисперсии |
| ||||||||
| Исследование модели |
| ||||||||
| Предпосылки |
| ||||||||
| Планирование эксперимента |
| ||||||||
| Численная аппроксимация | |||||||||
| Приложения |
| ||||||||

