Суффиксное дерево
Суффиксное дерево — бор, содержащий все суффиксы некоторой строки (и только их). Позволяет выяснять, входит ли строка w в исходную строку t, за время O(|w|), где |w| — длина строки w.
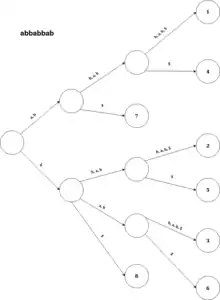
Основные определения и описание структуры
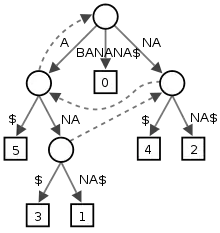
|




















Свойства суффиксных деревьев
Лемма. Местоположение w явно в компактном суффиксном дереве тогда и только тогда, когда w является не вложенным суффиксом t или w — правое ветвление.
Доказательство. . Если явно, то это может быть либо лист, либо вершина ветвления или корень (в этом случае и w — вложенный суффикс t).


Если — лист, тогда также является и суффиксом t. Значит, это должен быть не вложенный суффикс, так как иначе он появился бы где-нибудь ещё в строке t: v — суффикс t такой, что w — префикс v. Этот узел не может быть листом.

Если — узел ветвления, тогда должны существовать, по меньшей мере, два выходящих ребра из с различными метками. Это означает, что существуют два различных суффикса u, v, что w — префикс u и w — префикс v, где v = wxs, u = , x . Следовательно, w — правое ветвление.


. Если w является не вложенным суффиксом t, это должен быть лист. Если w — правое ветвление, то имеются два суффикса u и v, u = wxs, v = , x , тогда w является узлом ветвления. Лемма доказана.

Теперь легко видеть, почему ответ на вопрос, входит ли слово w в строку t, может быть найден за время O(|w|): нужно только проверить, является ли w местоположением (явным или неявным) в cst(t).
Метки рёбер должны представлять собой указатели на положение в строке, чтобы суффиксное дерево расходовало память размером O(n). Метка (p, q) ребра означает подстроку или пустую строку, если p > q.

Укконен вводит название открытые рёбра для рёбер, заканчивающихся в листьях. Пометки открытых рёбер записывают как (p, ) вместо (p, |t|), где — длина, всегда большая, чем |t|.

Пусть T — -дерево. Пусть — узел T, v — наидлиннейший суффикс w такой, что — также узел T. Непомеченное ребро от до называется суффиксным звеном. Если v = w, оно называется атомарным.


Утверждение. В ast(t) и cst(t$), где $ t, все суффиксные звенья являются атомарными.

Доказательство. Символ $ называется символом-стражем. Первая часть (для ast(t)) следует из определения, так как местоположения являются явными. Для доказательства второй (случай cst(t)) части мы должны показать, что для каждого узла также является узлом cst(t). Если — узел cst(t), то является либо листом, либо узлом ветвления. Если является листом, тогда aw — не вложенный суффикс t. Благодаря символу-стражу, из леммы следует, что все суффиксы (включая корень, пустой суффикс) являются явными, так как только корень — вложенный суффикс. Поэтому w является листом или корнем. Если — узел ветвления, тогда aw — правое ветвление, как и w. Следовательно, местоположение явно по лемме. Утверждение доказано.
Как следует из этого доказательства, символ-страж гарантирует существование листьев для всех суффиксов. С таким символом не может быть вложенных суффиксов, кроме пустого. Если мы опустим символ-страж, некоторые суффиксы могут стать вложенными, и их местоположения станут неявными.
Требования суффиксного дерева к памяти
Утверждение. Компактное суффиксное дерево может быть представлено в виде, требующем O(n) памяти.
Доказательство. Суффиксное дерево содержит не более одного листа на каждый суффикс (в точности один с символом-стражем). Каждый внутренний узел должен быть узлом ветвления, следовательно, внутренний узел имеет по меньшей мере двух потомков. Каждое ветвление увеличивает число листьев по меньшей мере на единицу, поэтому мы имеем не более n внутренних узлов и не более n листьев.
Для представления строк, являющихся метками рёбер, мы используем индексацию в исходной строке, как описано выше. Каждый узел имеет не более одного предка и, таким образом, общее число ребер не превышает 2n.
Аналогично, каждый узел имеет не более одного суффиксного звена, тогда общее число суффиксных звеньев также ограничено числом 2n. Утверждение доказано.
Как пример суффиксного дерева с 2n-1 вершинами можно рассмотреть дерево для слова . Размер атомарного суффиксного дерева для строки t составляет O().


Построение дерева за линейное время. Алгоритм mcc. (McCreight’s Algorithm)
Алгоритм mcc начинает работу с пустого дерева и добавляет суффиксы, начиная с самого длинного. Алгоритм mcc не является on-line алгоритмом, то есть для его работы необходима вся строка целиком. Для корректной работы требуется, чтобы строка завершалась специальным символом, отличным от других, так, чтобы ни один суффикс не являлся префиксом другого суффикса. Каждому суффиксу в дереве будет соответствовать лист. Для алгоритма мы определим — текущий суффикс (на шаге ), (голова) — наибольший префикс суффикса , который является также префиксом другого суффикса , где . (хвост) определим как .







Ключевой идеей алгоритма mcc является соотношение между и .

Лемма. Если где — буква алфавита, — строка (может быть пустая), тогда — префикс .



Доказательство. Пусть . Тогда существует , , такой, что является как префиксом , так и префиксом . Тогда — префикс и , следовательно, является префиксом головы . Лемма доказана.




Мы знаем местоположение , и если мы будем иметь суффиксное звено, то можем быстро перейти к местоположению — префикса головы без необходимости находить путь от корня дерева. Но местоположение могло бы не являться явным (если местоположение не было явным на предыдущем шаге) и суффиксное звено могло бы быть ещё не установлено для узла . Решение, данное МакКреем, находит узел за два шага: «повторное сканирование» («rescanning») и «сканирование» («scanning»). Мы проходим дерево наверх от узла пока не найдем суффиксное звено, следуем по нему и затем применяем повторное сканирование пути до местоположения (которое является простым, потому что мы знаем длину и это местоположение существует, так что мы не должны читать полные метки ребер, двигаясь вниз по дереву, мы можем просто проверять только начальные буквы и длину слов).


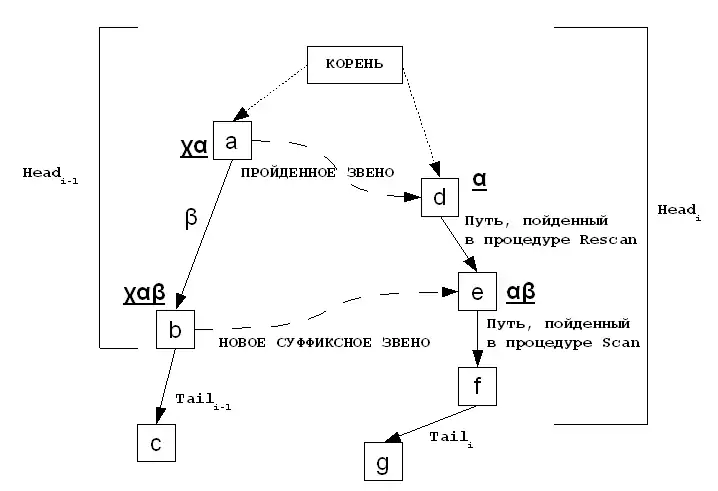
Рисунок демонстрирует эту идею. Вместо попытки найти путь от корня до узла , алгоритм переходит до , следует суффиксному звену до , проводит повторное сканирование пути до (возможно неявного) местоположения и остается найти путь до , проходя посимвольно.



Алгоритм состоит из трех частей.
1. Сначала он определяет структуру предыдущей головы, находит следующее доступное суффиксное звено и следует по нему.
2. Затем он повторно сканирует часть предыдущей головы, для которой длина является известной (эта часть названа ).

3. Наконец алгоритм устанавливает суффиксное звено для , сканирует оставшуюся часть (названную ) и добавляет новый лист для .

Узел ветвления создается во второй фазе повторного сканирования, если не существует местоположения . В этом случае сканирование не является необходимым, потому что если была бы длиннее чем , тогда являлось бы правым ветвлением, но по лемме является также правым ветвлением, так узел уже должен существовать. Узел создается в третьей фазе, если местоположение ещё не явно.



Алгоритм 1 (mcc, McCreight) Вход: строка t 1: T: = пустое дерево; 2: head0 := ; 3: n:= length(t); 4: for i:= 1 to n do 5: найти , , такие, что a. headi-1 = , b. если предок узла headi-1 не корень (root), обозначим его , в противном случае c. и ( |headi-1| = 0) 6: if ( >0) then 7: следовать по суффиксному звену от узла до ; 8: end if 9: := Rescan(); 10: установить суффиксное звено от до 11: (,taili) := Scan(,sufi-); 12: добавить лист, соответствующий taili; 13: end for











Обратите внимание, что если тогда и узнается одинаково быстро, как следуя суффиксному звену согласно строке 7 алгоритма.

Процедура Rescan ищет местоположение . Если местоположение ещё не явно, добавляется новый узел. Этот случай имеет место, когда голова () просмотрена целиком: если голова длиннее (и узел уже определен), должно являться префиксом более чем двух суффиксов и также является левым ветвлением . Местоположение может являться только явным, если этот узел уже является узлом ветвления, и если не было левым ветвлением тогда , должно быть, был длиннее, потому что встретился более длинный префикс.


Процедура Scan производит поиск в глубину дерева и возвращает позицию.
Процедура 1 Rescan(n,) Вход: узел n, строка 1: i:=1; 2: while i ||do 3: найти ребро e=nn',w1 = 1; 4: if i+|w|>||+1 then 5: k:=||-i+1; 6: расщепить ребро e с новым узлом m и ребрами nm и mn'; 7: return m; 8: end if 9: i:=i+|w|; 10: n:=n'; 11: end while 12: return n';




Процедура 2 Scan(n,) Вход: узел n, строка 1: i:=1; 2: while существует ребро e=nn', w1 = i do 3: k:=1; 4: while wk = i и k|w| do 5: k:=k+1; 6: i:=i+1; 7: end while 8: if k>|w| then 9: n:=n'; 10: else 11: расщепить ребро e с новым узлом m и ребрами nm и mn'; 12: return (m,i,...,); 13: end if 14: end while 15: return (n,i,...,);



Построение дерева за линейное время. Алгоритм ukk. (Ukkonen’s Algorithm)
Алгоритм, который изобрел Эско Укконен для построения суффиксного дерева за линейное время, вероятно, самый простой из таких алгоритмов. Простота происходит оттого, что алгоритм можно представить сначала как простой, но неэффективный метод, который с помощью нескольких приёмов реализации на уровне «здравого смысла» достигает уровня лучших алгоритмов по времени счёта в наихудших условиях. В PDF with figures сделано примерно то же самое.
Подробное объяснение алгоритма и реализация на C++ : cs.mipt.ru(на русском) и marknelson.us(на английском)
Для алгоритма Укконена нам потребуются
1) Неявные суффиксные деревья 2) Общее описание алгоритма 3) Оптимизация алгоритма
Неявные суффиксные деревья.
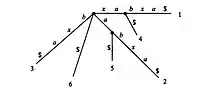
xabxa$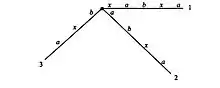
xabxa$Алгоритм Укконена строит последовательность неявных суффиксных деревьев, последнее из которых преобразуется в настоящее суффиксное дерево строки S.
Неявное суффиксное дерево строки S — это дерево, полученное из суффиксного дерева S$ удалением всех вхождений терминального символа $ из меток дуг дерева, удалением после этого дуг без меток и удалением затем вершин, имеющих меньше двух детей. Неявное суффиксное дерево префикса S[l..i] строки S аналогично получается из суффиксного дерева для S[l..i]$ удалением символов $, дуг и вершин, как описано выше.
Неявное суффиксное дерево для любой строки S будет иметь меньше листьев, чем суффиксное дерево для строки S$, в том и только том случае, если хотя бы один из суффиксов S является префиксом другого суффикса. Терминальный символ $ был добавлен к концу S как раз во избежание этой ситуации. В определении настоящего суффиксного дерева это очень важный момент. Однако если S заканчивается символом, который больше нигде в S не появляется, то неявное суффиксное дерево для S будет иметь лист для каждого суффикса и, следовательно, будет настоящим суффиксным деревом.
Хотя неявное суффиксное дерево может иметь листья не для всех суффиксов, в нём закодированы все суффиксы S — каждый произносится символами какого-либо пути от корня этого неявного суффиксного дерева. Однако если этот путь не кончается листом, то не будет маркера, обозначающего конец пути. Таким образом, неявные суффиксные деревья сами по себе несколько менее информативны, чем настоящие. Мы будем использовать их только как вспомогательное средство в алгоритме Укконена, чтобы получить настоящее суффиксное дерево для S.
Общее описание алгоритма.
Построить дерево T1
for i from 1 to m - 1 do begin {фаза i + 1}
for j from 1 to i + 1 begin {продолжение j}
найти в текущем дереве конец пути из корня с меткой S[j..i].
Если нужно, продолжить путь, добавив символ S(i + 1),
обеспечив появление строки S[j..i + 1] в дереве,
end;
end;Алгоритм Укконена строит неявное суффиксное дерево Ti для каждого префикса S[l..i] строки S, начиная с T1 и увеличивая i на единицу, пока не будет построено Tm. Настоящее суффиксное дерево для S получается из Tm, и вся работа требует времени О(m). Мы объясним алгоритм Укконена, представив сначала метод, с помощью которого все деревья строятся за время O(m³), а затем оптимизируем реализацию этого метода так, что будет достигнута заявленная скорость.
Три правила продолжения суффикса.
Чтобы превратить это общее описание в алгоритм, мы должны точно указать, как выполнять продолжение суффикса. Пусть S[j..i] = β — суффикс S[1..i]. В продолжении j, когда алгоритм находит конец β в текущем дереве, он продолжает β, чтобы обеспечить присутствие суффикса βS(i + 1) в дереве. Алгоритм действует по одному из следующих трех правил.
Правило 1. В текущем дереве путь β кончается в листе. Это значит, что путь от корня с меткой β доходит до конца некоторой «листовой» дуги (дуги, входящей в лист). При изменении дерева нужно добавить к концу метки этой листовой дуги символ S(i + 1).
Правило 2. Ни один путь из конца строки β не начинается символом S(i + 1), но по крайней мере один начинающийся оттуда путь имеется. В этом случае должна быть создана новая листовая дуга, начинающаяся в конце β, помеченная символом S(i + 1). При этом, если β кончается внутри дуги, должна быть создана новая вершина. Листу в конце новой листовой дуги сопоставляется номер j. Таким образом, в правиле 2 возможно два случая.
Правило 3. Некоторый путь из конца строки β начинается символом S(i + 1). В этом случае строка βS(i + 1) уже имеется в текущем дереве, так что ничего не надо делать (в неявном суффиксном дереве конец суффикса не нужно помечать явно).
Поиск в суффиксном дереве
Пусть задан текст и на вход приходит набор паттернов. После построения суффиксного дерева по тексту по алгоритму Укконена каждый паттерны можно искать так:
|
Обобщённое суффиксное дерево
Суффиксное дерево можно построить на наборе строк через конкатенация строк либо без.

Конкатенация строк
|

Такой подход проблемный из-за наличия синтетических суффиксов, но решается это уменьшением второго индекса суффиксной пары в дугах к листовым вершинам.
Без конкатенации строк
В этом алгоритме синтетических суффиксов не будет.
|





Нужно учиывать, что сжатые метки на разных дугах могут относиться к разным строкам, поэтому на дугах нужно хранить три числа.
Суффиксы для двух строк могут совпадать, но в то же время никакой суффикс не будет префиксом другого суффикса (из-за сентинела). Тогда лист указывает на все строки и начальные позиции этого суффикса.
Сравнение с ключевыми деревьями
Для решения задачи о поиске набора паттернов существует алгорим Ахо-Корасик. Он находит все вхождения за — суммарная длина паттернов, T — длина текста, k — число вхождений.

Ассимптотически поиск всех вхождений в суффиксном дереве работает за такое же время. Но дело в том, что Ахо-Корасик использует память на дерево ключей , время на построение и время на поиск . А вот суффиксное дерево занимает память , время — построение и на поиск.


То есть, если образцов много и больше чем текст, то суффиксное дерево маленькое, но долго ищет. В ином случае Ахо-Корасик, когда паттерны короткие, а текст больше, занимает меньше памяти, но суффиксное дерево ищет быстрее.
Таким образом выбор между тем или другим зависит от граничного времени или памяти.
См. также
Литература
- Гасфилд Д. Строки, деревья и последовательности в алгоритмах: Информатика и вычислительная биология / Пер. с англ. И. В. Романовского. — 2-е изд. — СПб.: Невский Диалект, 2003. — 654 с.
- Смит Б. Методы и алгоритмы вычислений на строках = Computing Patterns in Strings. — М.: Вильямс, 2006. — 496 с. — ISBN 5-8459-1081-1, 0-201-39839-7.
- Окулов С. М. Алгоритмы обработки строк. — М.: Бином, 2013. — 255 с. — ISBN 978-5-9963016-2-1.
Ссылки
- Moritz Maaß Suffix Trees and their Applications.
- Суффиксные деревья на сайте algolist.manual.ru
- Реализации алгоритма Укконена на C++ на сайте e-maxx.ru
- Построение суффиксного дерева алгоритмом Укконена на habrahabr.ru
- Suffix Trees in Python — на Python'е
- Модуль для работы с суффиксными деревьями — на PHP
- Модуль для работы с суффиксными деревьями — на Perl
- реализация на C++ алгоритма Укконена
