Коранический корпус арабского языка
Коранический корпус арабского языка — доступный для поиска электронный онлайн-корпус текстов Корана, включающий 77 430 арабских слов. Целью проекта является предоставление морфологических и синтаксических данных для исследователей, желающих изучить классический арабский язык[1][2][3][4][5].
| Коранический корпус арабского языка | |
|---|---|
| URL | corpus.quran.com |
| Коммерческий | GNU General Public License |
| Тип сайта | корпус текстов |
| Язык(-и) | арабский/английский |
| Расположение сервера | Великобритания |
| Владелец | Лидский университет |
| Начало работы | 2009 |
| Текущий статус | работает и развивается |
Функции
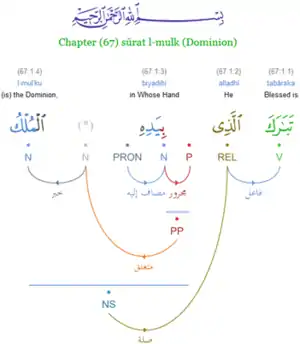
Грамматический анализ текста помогает пользователям раскрывать предполагаемые значения каждого аята и предложения. Каждое слово текста Корана атрибутировано указанием его части речи и несколькими морфологическими характеристиками. В отличие от других корпусов арабского языка, грамматика, используемая Кораническим корпусом, является традиционной арабской грамматикой Ираб (إعراب). Коранический корпус арабского языка — это исследовательский проект, возглавляемый специалистом по компьютерным наукам Кайс Дюкс из Лидского университета[4], который является частью проекта по изучению арабского языка в Школе вычислительной техники под руководством Эрика Атуэлла[6].
Аннотированный корпус включает в себя[1][7]:
- верифицированную вручную частеречную разметку текста на арабском языке;
- аннотированную древовидную структуру корпуса классического арабского языка;
- новую визуализацию традиционной арабской грамматики через графы зависимостей;
- морфологический поиск по тексту Корана;
- машиночитаемый морфологический арабо-английский словарь;
- частеречный конкорданс арабского языка Корана, с лемматизацией;
- онлайновую доску объявлений для волонтёров сообщества.
Частеречная разметка присваивает каждому слову корпуса тег части речи и морфологические признаки — например, указание, является данное слово существительным или глаголом, стоит в мужском или женском роде. На первом этапе проекта была задействована автоматическая частеречная разметка. Затем характеристики для каждого из 77 430 слов Корана поэтапно уточнены двумя аннотаторами, и уточнения продолжаются до настоящего времени.
Лингвистические исследования, в которых используется Коранический корпус, включают в себя обучение скрытой марковской модели частеречной разметки арабского языка[8], автоматическую категоризацию глав Корана[9] и просодический анализ текста[10].
Кроме того, проект предусматривает дословный перевод Корана на основе принятых английских источников вместо осуществления нового перевода Корана[4].
Примечания
- K. Dukes, E. Atwell and N. Habash (2011). Supervised Collaboration for Syntactic Annotation of Quranic Arabic. Language Resources and Evaluation Journal (LREJ). Special Issue on Collaboratively Constructed Language Resources.
- Supervised collaboration for syntactic annotation of Quranic Arabic at ResearchGate. Uploaded by Nizar Habash, Columbia University.
- K. Dukes and T. Buckwalter (2010). A Dependency Treebank of the Quran using Traditional Arabic Grammar. In Proceedings of the 7th International Conference on Informatics and Systems (INFOS). Cairo, Egypt.
- The Quranic Arabic Corpus Архивная копия от 23 февраля 2013 на Wayback Machine at The Muslim Tribune. June 20, 2011.
- Eric Atwell, Claire Brierley, Kais Dukes, Majdi Sawalha and Abdul-Baquee Sharaf. An Artificial Intelligence approach to Arabic and Islamic content on the internet (недоступная ссылка), pg. 2. Riyadh: King Saud University, 2011.
- Engineering Profile for Dr Eric Atwell - School of Computing - University of Leeds. www.comp.leeds.ac.uk.
- K. Dukes and N. Habash (2011). One-step Statistical Parsing of Hybrid Dependency-Constituency Syntactic Representations. International Conference on Parsing Technologies (IWPT). Dublin, Ireland.
- M. Albared, N. Omar and M. Ab Aziz (2011). Developing a Competitive HMM Arabic POS Tagger using Small Training Corpora. (недоступная ссылка) Intelligent Information and Database Systems. Springer Berlin, Heidelberg.
- A. M. Sharaf and E. Atwell (2011). Automatic Categorization of the Quranic Chapters. 7th International Computing Conference in Arabic (ICCA11). Riyadh, Saudi Arabia.
- C. Brierley, M. Sawalha and E. Atwell (2012). Boundary Annotated Qur’an Corpus for Arabic Phrase Break Prediction. Архивная копия от 15 декабря 2018 на Wayback Machine IVACS Annual Symposium. Cambridge.