Британский национальный корпус
Брита́нский национа́льный ко́рпус (BNC от англ. British National Corpus) — это корпус текстов из 100 миллионов слов, содержащий образцы письменного и разговорного британского английского языка из широкого круга источников[1][2][3]. Корпус охватывает британский английский конца XX века, представленный широким разнообразием жанров, и задуман как образец типичного разговорного и письменного британского английского языка того времени.
| Британский национальный корпус | |
|---|---|
| | |
| URL | natcorp.ox.ac.uk |
| Тип сайта | Научная литература |
| Язык(-и) | Британский английский |
| Расположение сервера |
|
| Автор | Издательство Оксфордского университета, Longman, W. & R. Chambers |
| Начало работы | 1994 год |
История
В рамках проекта по созданию BNC сотрудничали три издателя (Издательство Оксфордского университета в качестве ведущего соавтора, а также Longman и W. & R. Chambers), два университета (Оксфордский и Ланкастерский) и Британская библиотека[2].
Создание BNC началось в 1991 году под руководством консорциума BNC и было закончено к 1994 г. После 1994 года не было добавлений новых примеров, но BNC претерпел незначительные изменения перед выпуском второго (BNC World, 2001) и третьего (BNC XML Edition, 2007) издания[4].
Предпосылки
В представлении специалистов по компьютерной лингвистике BNC должен был представлять собой корпус современного на момент составления, встречающегося в реальных условиях языка в устной или письменной форме. В результате, BNC был составлен в форме, удобной для обработки на компьютере, для того, чтобы обеспечить автоматический поиск и обработку методами корпусной лингвистики. Одним из отличий BNC от существовавших корпусов того времени была открытость данных для использования не только в научных исследованиях, но и в коммерческих, и образовательных целях[3].
Создатели ограничили корпус только британским английским, не предполагая включения в него образцов использования всемирного английского языка. Это было сделано отчасти потому, что значительная часть стоимости проекта была оплачена британским правительством, которое было закономерно заинтересовано в поддержке документирования лингвистического разнообразия своей страны[3].
Для построения корпуса такого беспрецедентного размера как BNC потребовалось финансирование и коммерческих, и академических учреждений. В свою очередь, данные BNC впоследствии стали доступны для коммерческого использования и научных исследований[3].
Описание
BNC является одноязычным корпусом, так как он содержит образцы только британского английского языка, хотя иногда в текстах встречаются слова и фразы из других языков. Это синхронический корпус, так как в нём содержатся примеры использования языка только одного временного периода — конец XX века. По этой причине BNC не может служить источником данных о истории развитии британского варианта английского языка[4]. С самого начала те, кто участвовал в сборе письменных данных, стремились сделать BNC сбалансированным корпусом и, следовательно, искали и включали данные из различных источников[3].
Компоненты и содержание
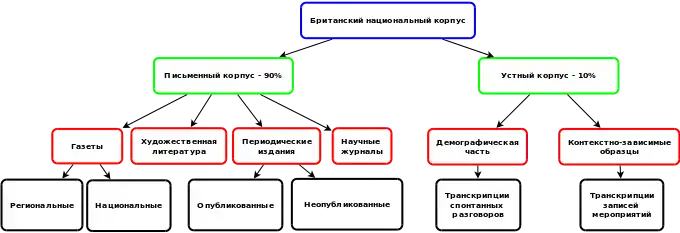
Письменный корпус
90 % корпуса составляют образцы употребления письменного языка. Эти примеры были взяты из региональных и общенациональных газет, научных журналов и периодики различных научных направлений, художественной литературы и публицистики, как из опубликованных, так и неопубликованных материалов (таких как брошюры, письма, студенческие эссе, сценарии, речи), а также из многих других источников[5].
Разговорный корпус
Оставшиеся 10 % материала BNC — это образцы применения разговорного языка, которые были представлены и записаны с помощью практической транскрипции.
Разговорный корпус состоит из двух частей. Демографическая часть содержит транскрипцию спонтанных разговоров, которые происходили в реальных условиях с участием волонтеров из различных возрастных групп, регионов и социальных слоев. Эти разговоры происходили в различных ситуациях, включая деловые или правительственные встречи и обсуждения в радиопередачах или по телефону[5]. Это было сделано для учёта как демографического распределения разговорного языка, так и лингвистически значимого разнообразия языка, обусловленного контекстом[6].
Вторая часть разговорного корпуса включает контекстно-зависимые образцы, такие как транскрипции записей, подготовленных входе особых встреч или мероприятий.
Все исходные записи, транскрибированные для включения в BNC, были помещены в архиве звука британской библиотеки. Большинство записей доступны на сайте фонетической лаборатории Оксфордского университета.
Разметка
Корпус BNC содержит частеречную разметку. Для этого при создании корпуса использовалась система разметки CLAWS. Эта система пережила ряд модификаций, прежде чем была получена последняя — CLAWS4, которая и была использована в корпусе. Система CLAWS1 была основана на скрытой марковской модели и была способна корректно разметить от 96 % до 97 % любого текста. При переходе от CLAWS1 к CLAWS2 пропала необходимость ручной подготовки текста перед запуском процесса разметки. В CLAWS4 вошли такие улучшения, как более мощные возможности по разрешению лексической многозначности и учёт вариаций в орфографии. Дальнейшая работа над системой разметки была ориентирована на увеличение показателей успеха автоматической разметки и на уменьшение ручной работы по подготовке текстов перед началом разметки путем введения в использование дополнительного программного обеспечивания для замещения ручной работы[2][7].
Позже была добавлена разметка, указывающая на неоднозначность некоторых слов и выражений. При этом, несмотря на способность CLAWS4 автоматически определять типы речи и значения слов, необходимость в ручной разметке сохранилась, так как в CLAWS4 не поддерживаются языки, отличные от английского[8][9].
Подкорпусы
Два подкорпуса (подмножества данных BNC) были выпущены под именами BNC Baby и BNC Sampler. Можно получить оба этих подкорпуса, заказав их на сайте BNC[10].
BNC Baby — это подкорпус BNC, который состоит из четырёх наборов образцов по миллиону слов каждый. Слова в каждом наборе соответствуют конкретной жанровой категории. Один набор образцов содержит транскрипции разговоров, а остальные три набора содержат образцы письменных текстов из научной литературы, художественной литературы и газет. При этом в подкорпусе сохранена разметка, имеющаяся в BNC[11]. Последнее (третье) издание было выпущено в формате XML[12].
BNC Sampler представляет собой подкорпус, состоящий из двух частей. Первая часть содержит письменные данные, вторая часть содержит разговорную речь. В каждой части содержится по одному миллиону слов. BNC Sampler изначально использовался для улучшения процесса разметки BNC, что в конечном итоге привело к изданию BNC World. В ходе работ по проекту BNC Sampler улучшался с ростом опыта и знаний о разметке. В итоге был создан тот BNC Sampler, который мы знаем сегодня[13].
Техническая информация
Корпус имеет разметку в соответствии с рекомендациями консорциума Text Encoding Initiative (TEI) и включает полную лингвистическую аннотацую и контекстную информацию[14].
Особенности доступа
Для использования совместно с корпусом инструмента частеречной разметки CLAWS4 необходимо приобретение лицензии[15]. В качестве альтернативы можно использовать сервис разметки, распространяемый Ланкастерским университетом[16].
Сам BNC может быть приобретен как с персональной, так и с коллективной лицензией. Издание BNC доступно в формате XML и поставляется с программным обеспечением поисковой системы Xaira. Корпус можно заказать через веб-сайт BNC[17].
Для XML-издания BNC был разработан корпусный менеджер BNCweb, доступный онлайн. Его интерфейс прост в использовании и поддерживает функции запросов и анализа материалов корпуса[18].
Вопросы разрешения использования материала
BNC стал первым корпусом подобного размера, доступный широкой аудитории. Возможно, это было связано с типовыми формами соглашений между правообладателями и Консорциумом с одной стороны, и между пользователями корпуса и Консорциумом с другой. Создатели корпуса стремились заключить с обладателями прав на интеллектуальную собственность соглашение со стандартной лицензией, одним из положений которого было включение в корпус материала без уплаты каких-либо денежных сборов. Такой договоренности способствовали оригинальность и уникальность корпуса[6].
Однако оказалось непросто сохранить анонимность людей, внесших вклад, без преуменьшения значимости их работы. Любой непрозрачный намек на личность автора удалялся из материалов корпуса. При этом рассматривалась возможность подмены настоящих имен другими именами для сохранения анонимности, что, впрочем, было признано нецелесообразным[6].
Кроме того, у авторов изначально было запрошено разрешение на включение только транскрибированных версий их речи, но не на включение самой речи. Хотя подобное разрешение могло бы быть запрошено повторно, поиск изначальных авторов может быть осложнён проводящимся процессом анонимизации. В то же время стали явными факторы, которые усугубляли нежелание правообладателей жертвовать для корпуса свои материалы: полные тексты исключались из корпуса, что привело к отсутствию мотивация для правообладателей распространять информацию посредством корпуса (особенно в связи с его некоммерческой основой)[6].
Недостатки и ограничения
Слишком общая классификация текстов
По состоянию на 2001 год в BNC все ещё отсутствовала классификация письменных текстов, кроме распределения по сферам (газеты, художественная литература и т. д.), и классификация разговорных текстов, кроме разделения по контекстам и демографическим или социально-экономическим классам участников разговора. Например, в корпус было включено огромное разнообразие образцов художественных текстов (романов, рассказов, поэм и т. п.), но информация об их поджанрах отсутствовала в заголовках образцов и в документации BNC. Таким образом, для исследователей знание о жанровом разнообразии было практически бесполезным, так как для них не было простой возможности получить произведения желаемого поджанра[19].
В 2002 году, с выходом новой версии корпуса — BNC World Edition, была предпринята попытка решения проблемы с классификацией. Кроме сфер для разговорных и письменных текстов были определены 70 классов, что позволило исследователям извлекать из корпуса тексты определённого жанра[20].
Тем не менее, даже после этих нововведений реализация классификации все ещё имеет проблемы, так как назначение жанра или поджанра тексту осложнено различными тонкостями. Разделение на классы для разговорных данных менее очевидно, чем для письменных, в связи с намного большим разнообразием задействованных в разговорах тем. Также имеются проблемы и неоднозначности с определением поджанра какого-либо жанра, так как разделение на поджанры в корпусе было предопределено в целях стандартизации[20].
Ошибки классификации и обманчивые заголовки
При создании корпуса некоторые тексты были неправильно категоризированы, зачастую из-за вводящих в заблуждение заголовков. Например, множество текстов со словом «лекция» в заголовке на самом деле являются обсуждениями в аудитории или обучающими семинарами, в которые вовлечены малые группы людей, или популярными лекциями, направленными на широкую аудиторию (а не лекциями для студентов в ВУЗе)[19]. Одна из причин ошибочной классификации заключается в том, что жанр и поджанр можно указать для большинства текстов, но не для всех. Кроме того, текст на всём своём протяжении может относиться к разным поджанрам, может подпадать под определение разных жанров[20].
Нехватка разговорного материала
Соотношение письменного и разговорного материала в BNC — 10:1[6]. Это связано с тем, что затраты на сбор, транскрибирование и перевод в электронную форму миллиона слов речи, встречающейся в реальных условиях, по крайней мере в 10 раз больше, чем затраты на добавление миллиона слов из газет. Однако существует мнение, что поскольку устная и письменная речь одинаково важны, то и в корпусе они должны быть представлены в равных пропорциях[6].
BNC не очень полезен при изучении некоторых особенностей разговорного языка, так как в него включены только практические транскрипции, а паралингвистические особенности общения обозначены очень поверхностно[21].
Ограниченные возможности изучения лексических взаимосвязей
Взаимосвязи между некоторыми лексическими единицами слишком неоднозначны, чтобы их было возможно эффективно обнаруживать с помощью поисковых запросов. Любая попытка поиска определительных придаточных предложений даст пользователю ошибочные данные, предоставляя случаи использования вопросительных местоимений и слова «that». Кроме того, идентифицировать придаточные предложения, в которых опущены местоимения (как, например, в «the man I saw»), вообще невозможно программными средствами. По этой же причине сложно определить использование некоторых семантических и прагматических категорий (сомнение, несогласие, узнавание)[21].
Ограниченное описание ситуаций
По материалам корпуса можно определить, произносится ли речь мужчиной или женщиной, но по ним невозможно выяснить, к кому обращается человек, произносящий речь — к мужчине или к женщине[21].
Неприменимо для изучения специальных типов текстов
BNC — очень разнообразный и смешанный корпус, поэтому для исследования каких-либо крайне специфичных типов или жанров текстов он не подходит, так как такой тип или жанр скорее всего будет представлен крайне ограничено и тексты такого типа непросто найти в корпусе. Например, в BNC очень мало деловых писем или записанных правительственных встреч, поэтому для исследования их специфики желательно собрать менее объёмный корпус, состоящий только из текстов этих типов[21].
Использование BNC
Обучение английскому языку
Существует два основных способа использования корпуса в языковом обучении: создание методических материалов и обучение через анализ[21].
Методические материалы
Издатели и исследователи могут использовать образцы из корпуса для создания рекомендаций по изучению языка, учебных программ и других методических материалов.
Например, BNC использовался группой японских исследователей в качестве инструмента при разработке веб-системы для изучения английского языка в определённых сферах (бизнес, медицина)[22]. Система предоставляла ученикам доступ к наиболее употребимым шаблонам предложений с целью обучения на этих примерах. Источником таких предложений в системе был BNC (предложения сопровождались ссылками на BNC для доказательства реальности применения).
Обучение через анализ
Анализ корпуса может быть напрямую включен в методики обучения языку. В таком случае ученики получают возможность самостоятельно классифицировать языковые данные корпуса и, следовательно, формировать по этой классификации представление о шаблонах и возможностях изучаемого языка. Данные из корпусов, которые используются в таком методе обучения, имеют относительно маленький объём и поэтому могут повлечь за собой обобщение представлений об изучаемом языке, которое может иметь мало общего с реальным положением вещей[21].
Прочее
BNC может быть использован в качестве источника ссылок при создании и разборе текстов, например, при изучении случаев использования отдельных слов в различных контекстах. Это позволяет ознакомиться с различными способами использования одних и тех же слов[21].
Кроме информации, относящейся к языку, BNC также может послужить источником энциклопедических данных, таких как особенности британской культуры, и стереотипов, популярных в Великобритании[21].
Переводные словари
В Индии в 2012 году при разработке 22 переводных словарей с местных языков на английский были использованы более 12 тысяч слов и фраз из BNC. Разработка велась в рамках движения по реформации системы образования и сохранению в Индии языков малых народов[23].
Тестирование и оценка
BNC, благодаря своему размеру, отлично подходит для использования в качестве материала для тестирования программ[24]. Например, он был использован при тестировании спецификаций языка разметки Text Encoding Initiative (TEI). Кроме того, из BNC были использованы 20 миллионов слов при оценке системы назначения подкатегорий в проекте, посвящённом анализу значений слов Senseval[25].
Научные исследования
- Collocational Evidence from the British National Corpus[26]
Исследование Хофмана и Леманна 2000 года, в котором рассматривались механизмы, дающие возможность людям свободно обращаться с их огромным набором коллокаций. В особенности изучались два механизма, один из которых позволяет коллокациям быть постоянно готовыми к использованию, а другой предоставляет людям возможность с легкостью расширять коллокации грамматически или синтаксически в целях адаптации под конкретную ситуацию. Для этих целей из BNC были извлечены редко встречающиеся комбинации слов[26].
- Non-sentential Utterances: A Corpus Study[27]
Исследование Фернандеза и Гинзбурга 2002 года, в котором рассматривались диалоги, наполненные высказываниями, законченными только интуитивно и не несущими информации за пределами контекста. В основном это типичные короткие ответы на вопросы. В ходе исследования были использованы фрагменты данных BNC, чтобы составить законченную и теоретически обоснованную классификацию таких высказываний[27].
Обработка естественного языка
BNC широко используется в работах в сфере морфологической обработки (раздел обработки естественного языка). В частности, данные из BNC применяются для тестирования точности, надежности и скорости инструментов обработки морфологических маркеров в британском английском[28]. Кроме того, данные из BNC были использованы для создания обширного хранилища информации о морфологических маркерах в английском языке[28].
Признание
Среди специалистов по компьютерной и корпусной лингвистике является общепризнанным тот факт, что BNC — это выдающийся результат, корпус громадного размера. Благодаря огромным усилиям по сбору и дальнейшей обработке большого объёма данных, BNC стал одним из ценнейших корпусов. BNC считается образцовым корпусом, с которого берут пример при разработке последующих корпусов (например, Американский, Чешский и Польский национальные корпуса)[29][30].
BNC2014
В июле 2014 года о BNC издательством Кембриджского университета и Центром по корпусному подходу к социальным наукам в Ланкастерском университете было объявлено о том, что идёт работа по созданию нового британского национального корпуса[31]. Первой стадией совместного проекта этих двух учреждений стало составление нового разговорного корпуса британского английского языка от начала до середины 2010-х годов[32].
См. также
Примечания
- Lou Burnard et al, 1998, XIII.
- Geoffrey Leech et al, 1994, с. 47-63.
- Geoffrey Leech, 1993, с. 9-15.
- What is the BNC?. Retrieved 12 March 2012.
- British National Corpus. Retrieved 12 March 2012.
- Lou Burnard, 2002.
- Geoffrey Leech 1994, 1994, с. 622-628.
- Leech, Geoffrey; Smith, Nicholas The British National Corpus (Version 2) with Improved Word-class Tagging. UCREL, Lancaster University, UK (2000). Дата обращения: 17 марта 2012.
- Leech, Geoffrey; Smith, Nicholas Automatic POS-Tagging of the Corpus. UCREL, Lancaster University, UK (2000). Дата обращения: 17 марта 2012.
- BNC Products. Дата обращения: 18 марта 2012.
- Burnard, Lou Reference Guide for BNC-baby (2003). Дата обращения: 18 марта 2012.
- New edition of BNC Baby available. Дата обращения: 19 марта 2012.
- BNC Sampler: XML edition (2008). Дата обращения: 18 марта 2012.
- Burnard, Lou Users Reference Guide for the British National Corpus (1995). Дата обращения: 18 марта 2012.
- Obtaining a license for the CLAWS tagger. UCREL, Lancaster University, UK. Дата обращения: 17 марта 2012.
- The CLAWS tagging service. UCREL, Lancaster University, UK. Дата обращения: 17 марта 2012.
- How to order. Дата обращения: 17 марта 2012.
- Peter Lang, 2008.
- David Lee, 2001.
- Lee, David NOTES TO ACCOMPANY THE BNC WORLD EDITION (BIBLIOGRAPHICAL) INDEX (недоступная ссылка) (2002). Дата обращения: 17 марта 2012. Архивировано 26 сентября 2012 года.
- Guy Aston, 1998.
- Danny Minn et al, 2005.
- Bilingual dictionaries to promote India’s mother tongues (14 March 2012). Архивировано 31 декабря 2010 года. Дата обращения 17 марта 2012.
- What can I do with the BNC?. Дата обращения: 18 марта 2012.
- Korhonen, Anna EVALUATION RESOURCES for English Subcategorization Acquisition Systems (недоступная ссылка) (2002). Дата обращения: 18 марта 2012. Архивировано 13 декабря 2012 года.
- Sebastian Hoffmann & Hans-Martin Lehmann, 2000.
- Raquel Fernandez & Jonathan Ginzburg, 2002.
- Guido Minnen et al, 2001.
- František Čermák, 2003.
- Richard Xiao, 2008.
- Tony McEnery on Twitter. Retrieved 17 March 2015.
- «Centre for Corpus Approaches to Social Science». Проверено 17 марта 2015.
Литература
- Lou Burnard, Guy Aston. The BNC handbook: exploring the British National Corpus. — Edinburgh: Edinburgh University Press, 1998. — P. xiii. — ISBN 0-7486-1055-3.
- Geoffrey Leech, Roger Garside, Michael Bryant. The large-scale grammatical tagging of text: Experience with the British National Corpus (англ.) // Corpus-based research into language. — Amsterdam: Radopi, 1994. — P. 47-63. — ISSN 90-5183-588-4.
- Geoffrey Leech. 100 million words of English // English Today. — 1993. — Т. 9, № 1. — С. 9–15. — doi:10.1017/S0266078400006854.
- Lou Burnard. Where did we go wrong? a retrospective look at the British National Corpus (англ.) // Teaching and learning by doing corpus analysis. — 2002. — P. 51-71.
- Geoffrey Leech, Roger Garside, Michael Bryant. Claws4: The Tagging Of The British National Corpus (англ.) // Proceedings of the 15th International Conference on Computational Linguistics. — 1994. — P. 622-628.
- Peter Lang. Corpus linguistics with BNCweb: a practical guide. — Peter Lang Publishing Group, 2008. — ISBN 978-3-631-56315-1.
- David Lee. GENRES, REGISTERS, TEXT TYPES, DOMAINS, AND STYLES (англ.) // Language Learning & Technology. — 2001. — Vol. 5, no. 3. — P. 37–72.
- Guy Aston. Learning English with the British National Corpus (англ.) // Статья представлена на 6-й конференции Jornada de Corpus, Barcelona: UPF. — 1998.
- Danny Minn, Hiroshi Sano, Marie Ino, Takahiro Nakamura. Using the BNC to create and develop educational materials and a website for learners of English (англ.) // ICAME Journal. — 2005. — No. 29. — P. 99–113.
- Sebastian Hoffmann, Hans-Martin Lehmann. Collocational Evidence from the British National Corpus (англ.) // Corpora Galore: Analyses and Techniques in Describing English. — 2000. — P. 17-33. — ISSN 90-420-0419-3.
- Raquel Fernandez, Jonathan Ginzburg. Non-sentential Utterances: A corpus study (англ.) // Proceedings of the Third SIGdial Workshop on Discourse and Dialogue. — 2002. — P. 15-26.
- Guido Minnen, John Carrol, Darren Pearce. Applied Morphological Processing of English (англ.) // Natural Language Engineering. — 2001. — Vol. 7, no. 3. — P. 207–223. — doi:10.1017/s1351324901002728.
- František Čermák. Today's Corpus Linguistics: Some Open Questions (англ.) // International Journal of Corpus Linguistics. — 2003. — Vol. 7, no. 2. — P. 265–282. — doi:10.1075/ijcl.7.2.06cer.
- Richard Xiao. Well-known and influential corpora: A survey (англ.) // Corpus Linguistics: An International Handbook. — Berlin: Mouton de Gruyter, 2008. — Vol. 1. — P. 383-457. — ISSN 978-3-11-021142-9. Архивировано 25 апреля 2016 года.