GENCODE
GENCODE — проект геномных исследований, являющийся составной частью проекта «Энциклопедия элементов ДНК» (ENCODE)[2].
| GENCODE | |
|---|---|
| Содержимое | |
| Описание | Энциклопедия генов и генных вариантов |
| Тип данных | Аннотации генов человека и мыши в формате GTF/GFF3 |
| Контакты | |
| Исследовательский центр | Институт Сэнгера (Welcome Trust Sanger Institute) |
| Авторы | Harrow J, et al [1] |
| Дата выпуска | Сентябрь 2012 |
| Доступность | |
| Сайт | GENCODE |
| Прочее | |
| Лицензия | Открытый доступ |
| Частота релизов |
Геном человека — раз в 3 месяца Геном мыши — раз в 6 месяцев |
| Версия | GENCODE 28 (человеческий геном), M17 (мышиный геном) |
GENCODE был создан в рамках пилотной фазы проекта ENCODE с целью определить и картировать все белок-кодирующие гены из библиотеки ENCODE[3]. Сейчас проект нацелен на создание энциклопедии генов и их вариантов с полным описанием их структурных характеристик в геномах человека и мыши с помощью методов вычислительного анализа, ручной аннотации и экспериментальной проверки[4].
Конечная цель проекта — создание базы аннотаций, включающей все белок-кодирующие локусы с альтернативными транскриптами[5], некодирующие локусы с обнаруженными транскриптами[6] и псевдогены[7].
История
В сентябре 2003 года Национальный институт исследований генома человека (NHGRI) открыл публичный исследовательский консорциум ENCODE для реализации проекта по определению всех функциональных элементов человеческого генома. Этот проект является продолжением проекта «Геном человека» (англ. The Human Genome Project)[8], запущенного в 1990 году Национальной организацией здравоохранения США (NIH). Целью проекта была расшифровка последовательности ДНК человека. В 2003 году были опубликованы результаты, и научное сообщество высказало заинтересованность в исследовании функциональных элементов генома человека для лучшего понимания механизмов развития некоторых заболеваний. Для этого и был запущен проект ENCODE. Он был разделен на три фазы: пилотная (начальная) фаза, разработка методологии и продуктивная фаза[9]. В ходе пилотной фазы планировалось исследовать около 30 Mb генома человека, а полученные результаты учесть в дальнейшем при анализе остального человеческого генома[9]. Для картирования на этот фрагмент генома известных белок-кодирующих генов был создан проект GENCODE[3].
В апреле 2005 года была выпущена первая версия GENCODE с аннотацией 44 локусов человеческого генома[3]. В ней было описано 416 известных геномных локусов, 26 новых белок-кодирующих локусов, 82 транскрибирующихся и 170 псевдогенных локусов. Во втором релизе (14 октября 2005 года) была обновлена и подтверждена информация об аннотированных раньше локусах, в основном, благодаря экспериментальным данным RACE и RT-PCR[3].
В июне 2007 года пилотная фаза ENCODE была завершена[10]. Проект был признан удачным, и институт Сэнгера (Welcome Trust Sanger Institute) получил грант от NHGRI для масштабирования проекта GENCODE[11].
В 2012 году был выпущен крупнейший релиз GENCODE 7 (на основе данных на момент декабря 2011 года), в котором была скомбинирована автоматическая аннотация Ensembl и аннотация вручную. С 2013 года GENCODE был удостоен второго гранта на продолжение работы по аннотации генома человека, а также на аннотацию мышиного генома для сравнительных исследований геномов мыши и человека[11].
В апреле 2018 года была выпущена версия GENCODE 28 (содержащая данные, обработанные до ноября 2017 года)[12].
Задачи
Задачи, решавшиеся в проекте GENCODE, вставали перед научным сообществом по мере расширения познаний в области генетики. Как правило, эти задачи были связаны с уточнением определений генетических терминов и с изучением функций геномных участков, ранее не подвергавшихся близкому рассмотрению. Ниже приведены примеры интересных вопросов и тем, которые исследуются в рамках GENCODE[11].
Определение понятия «ген»
Задача определения понятия «ген» стоит перед учеными на протяжении всего времени с тех пор, как исследователи задумались о вопросах наследственности. В 1900-х годах ген рассматривался как некая дискретная единица наследственности, затем ген стали считать основой для биосинтеза белка, а в последнее время это понятие расширили до геномного фрагмента, транскрибирующегося в РНК[13]. Хотя определение гена претерпело значительные изменения за последний век, оно осталось сложным и противоречивым предметом обсуждения для многих ученых. В ходе развития проектов ENCODE и, в частности, GENCODE, были подробнее описаны ещё более проблематичные аспекты определения — такие как альтернативный сплайсинг, межгенные участки, а также сложные паттерны рассеянной регуляции, консервативность некодирующих участков и обилие генов, продуцирующих некодирующие РНК. Поскольку глобальной целью проекта GENCODE является создание энциклопедии генов и генных вариантов, эти проблемы поставили проект перед необходимостью дать обновленное определение понятия гена[13].
Псевдогены
Псевдогены — это белок-кодирующие (или сходные с ними) последовательности ДНК, в которых произошла делеция или сдвиг рамки считывания[14]. В большинстве геномных баз данных их упоминают как побочные продукты аннотации более привычных белок-кодирующих последовательностей. Однако недавний анализ показал, что некоторые из псевдогенов не просто экспрессируются, но и функционируют, играя роль в различных биологических процессах[15]. Чтобы разобраться со всеми сложностями описания псевдогенов, в рамках GENCODE исследователи создали онтологию псевдогенов с использованием автоматических, ручных и экспериментальных методов, чтобы связать воедино их различные свойства, в том числе свойства последовательности, эволюцию и возможную биологическую функцию[4]. Количество аннотированных псевдогенов растет с каждой новой версией GENCODE (см. Основная статистика).
Длинные некодирующие РНК (lncRNA)
Одной из ключевых областей исследования проекта GENCODE является изучение биологического значения длинных некодирующих РНК (lncRNA). Для более глубокого понимания и изучения экспрессии lncRNA у человека, в рамках GENCODE был запущен подпроект для разработки пользовательских микрочипов для количественного определения таких транскриптов в аннотации lncRNA[6]. Некоторое количество подобных платформ было создано с помощью системы Agilent Technologies eArray, они доступны в стандартном формате Аgilent[16].
Датасет длинных некодирующих РНК, представленный в GENCODE (в частности, в версии GENCODE 7), считается самым большим из всех представленных датасетов lncRNA. При этом он мало перекрывается с другими существующими датасетами[6]. Транскрипты, аннотированные как lncRNA, далее могут быть классифицированы на следующие типы на основе их положения в геноме относительно белок-кодирующих генов:
- Антисмысловая РНК: локус, для которого был найден хотя бы один транскрипт, перекрывающийся с экзоном белок-кодирующего гена на противоположной цепи, или есть опубликованные данные об антисмысловой регуляции какого-либо гена;
- Длинная межгенная некодирующая РНК (lincRNA[17]);
- «Перекрывающийся»: локус, содержащий белок-кодирующий ген внутри интрона на той же цепи;
- «Интронный»: локус, расположенный внутри интрона, но не перекрывающийся с экзонами на той же цепи;
- Процессированный транскрипт: локус, для которого ни один транскрипт не содержит открытую рамку считывания, и который не может быть отнесен ни к одной из предыдущих категорий из-за сложной структуры.
Основные участники
В таблице приведены институты, чье участие было анонсировано на сайте GENCODE[18].
| Пилотная фаза | Масштабирование проекта | Вторая фаза (текущая) |
|---|---|---|
| Институт Сэнгера, Кэмбридж, Великобритания | Институт Сэнгера, Кэмбридж, Великобритания | Институт Сэнгера, Кэмбридж, Великобритания |
| Муниципальный Институт Медицинских Исследований (IMIM), Барселона, Каталония | Центр Геномной Регуляции (CRG), Барселона, Каталония | Центр Геномной Регуляции (CRG), Барселона, Каталония |
| Университет Женевы, Швейцария | Университет Лозанны, Швейцария | Университет Лозанны, Швейцария |
| Калифорнийский Университет, Беркли, США | Университет Санта Круз (UCSC), Калифорния, США | Университет Санта Круз (UCSC), Калифорния, США |
| Европейский Биоинформатический Институт, Хинкстон, Великобритания | Массачусетский технологический институт (MIT), Бостон США | Массачусетский технологический институт (MIT), Бостон, США |
| Йельский университет, Нью-Хейвен, США | Йельский университет, Нью-Хейвен, США | |
| Испанский Национальный Центр Раковых Исследований (CNIO), Мадрид, Испания | Испанский Национальный Центр Раковых Исследований (CNIO), Мадрид, Испания | |
| Университет Вашингтона (WashU), Сент-Луис, США | Европейский Биоинформатический Институт, Кэмбридж, Великобритания |
Основная статистика
Полнота данных в аннотациях GENCODE непрерывно растёт. Ниже приведена статистика версии GENCODE 28[19]. Эта версия соответствует выпуску Ensembl 92 и содержит аннотацию, сделанную по сборке человеческого генома GRCh38, но доступную также для сборки GRCh37).
| Категории | Всего | Категории | Всего |
|---|---|---|---|
| Общее количество генов | 58 381 | Всего транскриптов | 203 835 |
| Белок-кодирующие гены | 19 901 | Белок-кодирующие транскрипты: | 82 335 |
| Гены длинных некодирующих РНК | 15 779 | - кодирующие полный белок | 56 541 |
| Гены малых некодирующих РНК | 7 569 | - кодирующие фрагмент белка | 25 794 |
| Псевдогены: | 14 723 | Нонсенс-опосредованно распавшиеся транскрипты | 14 889 |
| - обработанные псевдогены | 10 693 | Транскрипты локусов длинных некодирующих РНК | 28 468 |
| - необработанные псевдогены | 3 519 | ||
| - унитарные псевдогены | 218 | ||
| - полиморфные псевдогены | 38 | ||
| - псевдогены | 18 | ||
| Генные сегменты иммуноглобулин-T-клеточного рецептора: | 645 | Общее число различных аннотаций | 61 132 |
| - белок-кодирующие сегменты | 408 | Число генов, к которым относится больше одной аннотации | 13 641 |
| - псевдогены | 237 |
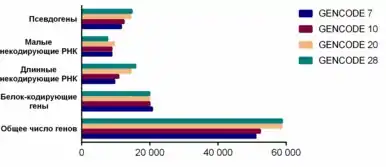
Сравнение версий GENCODE
Сравнительная статистика четырёх основных релизов GENCODE продемонстрирована на графике справа[20].
Данные свидетельствуют о том, что покрытие генома (количество обнаруженных и аннотированных локусов) стабильно увеличивается. При этом доля белок-кодирующих генов среди аннотированных уменьшается — в основном, из-за результатов аннотирования поли(A)-сайтов и кэп-анализа экспрессии генов (CAGE)[4]. Одновременно с этим увеличивается количество псевдогенов и локусов, аннотированных как длинные некодирующие РНК.
Методология
В проекте GENCODE применялись ручная и автоматическая аннотация. При верификации результатов использовались данные лабораторных экспериментов[21].
Автоматическая аннотация (ENSEMBL)
Информация о транскриптах Ensembl, полученных при автоматической аннотации генов, основывалась на экспериментальных данных о последовательностях белков и мРНК из публичных баз данных[22]. Помимо белок-кодирующих участков, аннотировались нетранслируемые участки, длинные некодирующие РНК и короткие некодирующие РНК[4].
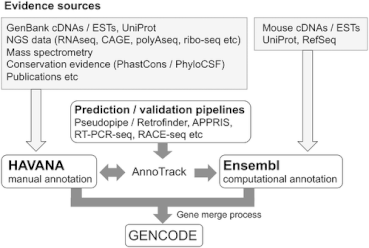
Аннотация вручную (группа HAVANA)
HAVANA (Human and Vertebrate Analysis and Annotation) — исследовательская группа, осуществляющая ручную аннотацию транскриптов в проекте GENCODE[3][4].
Помимо группы HAVANA, в состав консорциума GENCODE входило ещё несколько групп, проводивших анализ аннотированных локусов с помощью программ Ensembl и помогавших аннотаторам в идентификации пропущенных либо неверно аннотированных локусов, в том числе сайтов сплайсинга. Для обмена информацией между группами использовалась трекинговая система AnnoTrack[24]. В процессе также использовались данные экспериментов РНК-секвенирования, CAGE и Ditag[25].
Помимо официально вовлечённых в проект групп, над улучшением качества аннотации GENCODE работали независимые исследователи[26].
Объединение ручной и автоматической аннотаций
При объединении все модели транскриптов, полученные автоматической и ручной аннотацией, сравнивались для перекрывающихся транскриптов. Найденные расхождения детектировались с использованием системы AnnoTrack[4].
Автоматическая аннотация не всегда может считаться корректной (так, только в 45 % случаев автоматической аннотации корректно предсказываются все альтернативные транскрипты[4]). В случае несовпадения аннотаций приоритетной являлась аннотация HAVANA, так как ручная аннотация в сложных случаях предполагала анализ геномного контекста, литературы и использование экспериментальных данных Mus musculus. Тем не менее, для таких случаев сохраняется информация, полученная обоими способами аннотации[4].
Оценка качества
Транскриптам присваивается определённый уровень поддержки на основании сравнения транскрипта GENCODE с выравниванием мРНК и маркерных экспрессирующихся последовательностей (EST), полученным из Ensembl и UCSC. В итоге аннотации каждого транскрипта делятся на определённые вручную, автоматически или слитые аннотации, то есть те, для которых и автоматический метод, и метод аннотирования вручную дали одинаковые результаты[4].
Амплификация, секвенирование, картирование и валидация результатов
С помощью амплификации кДНК были сгенерированы двуцепочечные кДНК человеческих тканей (мозга, сердца, почки, яичка, печени, селезёнки, лёгкого и скелетной мышцы). Очищенная ДНК использовалась для создания геномной библиотеки с помощью набора Illumina «Genomic DNA sample prep kit». Библиотека была отсеквенирована на платформе Illumina Genome Analyzer 2. Риды (по 35 или 75 нуклеотидов) картировались на референсный геном человека сборки hg19 и предсказанные ампликоны с использованием программы Bowtie. Транскрипты валидировались только ридами, которые однозначно картировались на геном. Места соединений экзонов считались достоверными, если на них картировалось минимум 10 ридов, содержащими хотя бы 4 (для ридов длиной 35 нуклеотидов) или 8 (для ридов длиной 75 нуклеотидов) нуклеотидов в каждом из двух экзонов, разделённых сайтом сплайсинга[4].
Прочие подходы
Для аннотации альтернативных транскриптов генов использовался веб-сервис APPRIS (CNIO). APPRIS выбирает один вариант в качестве «главной изоформы» на основании информации о белковом продукте гена и об ортологах близких видов. APPRIS широко использовался при масштабировании проекта ENCODE и при аннотации геномов других видов (Mus sp., Danio sp., Rattus sp.)[27].
Для поиска кодирующих последовательностей в транскриптах, автоматически предсказанных на основании данных РНК-секвенирования, использовалась программа PhyloCSF. Она основывается на анализе паттернов эволюции, выравнивая транскрипт с экзонами позвоночных из UCSC (включая 33 плацентарных млекопитающих)[4].
Организация данных
Текущая версия набора генов человека в GENCODE включает файлы аннотаций (в форматах GTF и GFF3), FASTA-файлы и файлы METADATA, связанные с аннотацией GENCODE для всех геномных участков[12]. Они соотнесены с референсной хромосомой и хранятся в отдельных файлах, которые содержат: генную аннотацию, сайты полиаденилирования, аннотированные группой HAVANA, псевдогены, предсказанные алгоритмами Йельского университета и университета Санта-Круз (США), длинные некодирующие РНК, а также структуры тРНК, предсказанные tRNA-Scan [12].
Определение уровня аннотации
Все гены датасета GENCODE классифицируются на три категории в соответствии с типом аннотации[4]:
- Уровень 1 (подтвержденный локус): включает транскрипты, которые были аннотированы вручную и проверены экспериментально с помощью RT-PCR — секвенирования, а также псевдогены, подтвержденные тремя разными методологиями[4].
- Уровень 2 (аннотированный вручную локус): к нему относятся транскрипты, аннотированые только вручную группой HAVANA, а также транскрипты, совмещенные с моделями, полученными по автоматическому протоколу Ensembl[4].
- Уровень 3 (автоматически аннотированный локус): отражает транскрипты или псевдогены, предсказанные только с помощью автоматической аннотации Ensembl[4].
Определение статуса гена/транскрипта
Генам и транскриптам присваиваются статусы «известный», «новый» и «предполагаемый» в зависимости от их представленности в других основных базах данных и от оснований, использованных для построения составляющих их транскриптов[4].
Известный («known»): представлен в базах данных HUGO Gene Nomenclature Committee (HGNC) и RefSeq[4].
Новый («novel»): не представлен в базах HGNC или RefSeq, но хорошо подтверждается либо транскриптом, специфичным для данного локуса, либо свидетельствами его присутствия в паралогичном или ортологичном локусе[4].
Предполагаемый («putative»): не представлен в базах НGNC или RefSeq, но подтверждается признаками существования более короткого и редкого транскрипта[4].
Связанные с GENCODE проекты
Ensembl
Проект Ensembl является важной частью проекта ENCODE и представляет собой геномный браузер, позволяющий визуализировать сборку генома и все данные проекта ENCODE, в частности, аннотированные в проекте GENCODE геномные участки[28].
RGASP
RGASP (The RNA-seq Genome Annotation Assessment Project) — проект, организованный в рамках консорциума GENCODE после семинара EGASP (ENCODE Genome Annotation Assessment Project) по предсказанию генов. Было проведено две сессии семинаров для анализа результатов секвенирования РНК, а также рассмотрения его различных (методических и технических) аспектов. Одной из наиболее существенных находок первых двух стадий проекта стала важность соотнесения чтения с качеством полученного предсказания гена. В 2014 году была проведена третья сессия семинаров RGASP, где основное внимание было уделено картированию чтений на геном. Проект предоставил софт для аннотации транскриптов (определение, реконструкция и расчет количества транскриптов)[29].
Примечания
- Williams F. M., Scollen S., Cao D., Memari Y., Hyde C. L., Zhang B., Sidders B., Ziemek D., Shi Y., Harris J., Harrow I., Dougherty B., Malarstig A., McEwen R., Stephens J. C., Patel K., Menni C., Shin S. Y., Hodgkiss D., Surdulescu G., He W., Jin X., McMahon S. B., Soranzo N., John S., Wang J., Spector T. D. Genes contributing to pain sensitivity in the normal population: an exome sequencing study. (англ.) // PLoS Genetics. — 2012. — Vol. 8, no. 12. — P. e1003095—1003095. — doi:10.1371/journal.pgen.1003095. — PMID 23284290.
- ENCODE: Encyclopedia of DNA Elements (англ.). ENCODE. Stanford University. — Официальный сайт проекта и одноименного консорциума ENCODE. Дата обращения: 19 мая 2018.
- Harrow J., Denoeud F., Frankish A., Reymond A., Chen C. K., Chrast J., Lagarde J., Gilbert J. G., Storey R., Swarbreck D., Rossier C., Ucla C., Hubbard T., Antonarakis S. E., Guigo R. GENCODE: producing a reference annotation for ENCODE. (англ.) // Genome Biology. — 2006. — Vol. 7 Suppl 1. — P. 4—1. — doi:10.1186/gb-2006-7-s1-s4. — PMID 16925838.
- Harrow J., Frankish A., Gonzalez J. M., Tapanari E., Diekhans M., Kokocinski F., Aken B. L., Barrell D., Zadissa A., Searle S., Barnes I., Bignell A., Boychenko V., Hunt T., Kay M., Mukherjee G., Rajan J., Despacio-Reyes G., Saunders G., Steward C., Harte R., Lin M., Howald C., Tanzer A., Derrien T., Chrast J., Walters N., Balasubramanian S., Pei B., Tress M., Rodriguez J. M., Ezkurdia I., van Baren J., Brent M., Haussler D., Kellis M., Valencia A., Reymond A., Gerstein M., Guigó R., Hubbard T. J. GENCODE: the reference human genome annotation for The ENCODE Project. (англ.) // Genome Research. — 2012. — September (vol. 22, no. 9). — P. 1760—1774. — doi:10.1101/gr.135350.111. — PMID 22955987.
- Frankish A., Mudge J. M., Thomas M., Harrow J. The importance of identifying alternative splicing in vertebrate genome annotation. (англ.) // Database : The Journal Of Biological Databases And Curation. — 2012. — Vol. 2012. — P. 014—014. — doi:10.1093/database/bas014. — PMID 22434846.
- Derrien T., Johnson R., Bussotti G., Tanzer A., Djebali S., Tilgner H., Guernec G., Martin D., Merkel A., Knowles D. G., Lagarde J., Veeravalli L., Ruan X., Ruan Y., Lassmann T., Carninci P., Brown J. B., Lipovich L., Gonzalez J. M., Thomas M., Davis C. A., Shiekhattar R., Gingeras T. R., Hubbard T. J., Notredame C., Harrow J., Guigó R. The GENCODE v7 catalog of human long noncoding RNAs: analysis of their gene structure, evolution, and expression. (англ.) // Genome Research. — 2012. — September (vol. 22, no. 9). — P. 1775—1789. — doi:10.1101/gr.132159.111. — PMID 22955988.
- Pei B., Sisu C., Frankish A., Howald C., Habegger L., Mu X. J., Harte R., Balasubramanian S., Tanzer A., Diekhans M., Reymond A., Hubbard T. J., Harrow J., Gerstein M. B. The GENCODE pseudogene resource. (англ.) // Genome Biology. — 2012. — 26 September (vol. 13, no. 9). — P. 51—51. — doi:10.1186/gb-2012-13-9-r51. — PMID 22951037.
- All About The Human Genome Project (HGP) (англ.). National Human Genome Research Institute (1 октября 2015). — О проекте "Геном человека". Дата обращения: 12 мая 2018.
- ENCODE Project Consortium. The ENCODE (ENCyclopedia Of DNA Elements) Project. (англ.) // Science (New York, N.Y.). — 2004. — 22 October (vol. 306, no. 5696). — P. 636—640. — doi:10.1126/science.1105136. — PMID 15499007.
- ENCODE Project Consortium, Ewan Birney, John A. Stamatoyannopoulos, Anindya Dutta, Roderic Guigó. Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project // Nature. — 2007-06-14. — Т. 447, вып. 7146. — С. 799–816. — ISSN 1476-4687. — doi:10.1038/nature05874.
- The GENCODE Project: Encyclopædia of genes and gene variants (англ.) (недоступная ссылка). Wellcome Trust Sanger Institute. — Описание проекта GENCODE на официальном сайте проекта. Дата обращения: 12 мая 2018. Архивировано 29 апреля 2018 года.
- GENCODE current release (англ.) (недоступная ссылка). Wellcome Trust Sanger Institute. — Выпуск GENCODE 28 (апрель 2018). Дата обращения: 12 мая 2018. Архивировано 12 апреля 2018 года.
- Mark B. Gerstein, Can Bruce, Joel S. Rozowsky, Deyou Zheng, Jiang Du. What is a gene, post-ENCODE? History and updated definition // Genome Research. — June 2007. — Т. 17, вып. 6. — С. 669–681. — ISSN 1088-9051. — doi:10.1101/gr.6339607.
- E. F. Vanin. Processed pseudogenes: characteristics and evolution // Annual Review of Genetics. — 1985. — Т. 19. — С. 253–272. — ISSN 0066-4197. — doi:10.1146/annurev.ge.19.120185.001345.
- Jinrui Xu, Jianzhi Zhang. Are Human Translated Pseudogenes Functional? (англ.) // Molecular Biology and Evolution. — 2016-03-01. — Vol. 33, iss. 3. — P. 755–760. — ISSN 0737-4038. — doi:10.1093/molbev/msv268.
- GENCODE Custom lncRNA Expression Microarray Design (англ.) (недоступная ссылка). GENCODE. Wellcome Trust Sanger Institute. — Дизайн микрочипов экспрессии длинных некодирующих РНК для проекта GENCODE. Дата обращения: 13 мая 2018. Архивировано 8 апреля 2018 года.
- Igor Ulitsky, David P. Bartel. lincRNAs: Genomics, Evolution, and Mechanisms // Cell. — 2013-07-03. — Т. 154, вып. 1. — С. 26–46. — ISSN 0092-8674. — doi:10.1016/j.cell.2013.06.020.
- Participants, all funded personnel (англ.) (недоступная ссылка). Wellcome Sanger Institute. — Список участников проекта GENCODE на официальном сайте проекта. Дата обращения: 13 мая 2018. Архивировано 11 мая 2018 года.
- Statistics about all Human GENCODE releases (англ.) (недоступная ссылка). GENCODE. Wellcome Sanger Institute (апрель 2018). — Все выпуски аннотаций человеческого генома на официальном сайте GENCODE. Дата обращения: 13 мая 2018. Архивировано 14 апреля 2018 года.
- Statistics about the current GENCODE freeze (version 21) (англ.). GENCODE. Wellcome Trust Sanger Institute. — Статистика выпуска GENCODE 21. Дата обращения: 13 мая 2018.
- Phase 2 GENCODE Goals (англ.). GENCODE. Wellcome Trust Sanger Institute. — Описание задач проекта GENCODE на официальном сайте проекта. Дата обращения: 13 мая 2018.
- Ensembl Gene Set (англ.). Archive!Ensembl. EMBL-EBI. — Описание данных Ensembl на официальном сайте проекта. Дата обращения: 13 мая 2018.
- Mudge J. M., Harrow J. Creating reference gene annotation for the mouse C57BL6/J genome assembly. (англ.) // Mammalian Genome : Official Journal Of The International Mammalian Genome Society. — 2015. — October (vol. 26, no. 9-10). — P. 366—378. — doi:10.1007/s00335-015-9583-x. — PMID 26187010.
- Kokocinski F., Harrow J., Hubbard T. AnnoTrack--a tracking system for genome annotation. (англ.) // BMC Genomics. — 2010. — 5 October (vol. 11). — P. 538—538. — doi:10.1186/1471-2164-11-538. — PMID 20923551.
- S. Searle, A. Frankish, A. Bignell, B. Aken, T. Derrien. The GENCODE human gene set // Genome Biology. — 2010-10-11. — Т. 11, вып. 1. — С. P36. — ISSN 1474-760X. — doi:10.1186/gb-2010-11-s1-p36.
- Wright J. C., Mudge J., Weisser H., Barzine M. P., Gonzalez J. M., Brazma A., Choudhary J. S., Harrow J. Improving GENCODE reference gene annotation using a high-stringency proteogenomics workflow. (англ.) // Nature Communications. — 2016. — 2 June (vol. 7). — P. 11778—11778. — doi:10.1038/ncomms11778. — PMID 27250503.
- Jose Manuel Rodriguez, Juan Rodriguez-Rivas, Tomás Di Domenico, Jesús Vázquez, Alfonso Valencia. APPRIS 2017: principal isoforms for multiple gene sets (англ.) // Nucleic Acids Research. — 2017-10-23. — Vol. 46, iss. D1. — P. D213–D217. — ISSN 1362-4962 0305-1048, 1362-4962. — doi:10.1093/nar/gkx997.
- ENCODE data in Ensembl (англ.). Ensembl. EMBL-EBI. — Описание использования данных проекта ENCODE на сайте Ensembl. Дата обращения: 12 мая 2018.
- RGASP. RNA-seq Genome Annotation Assessment Project (англ.) (недоступная ссылка). GENCODE. Wellcome Sanger Institute. — Описание проекта RGASP на официальном сайте GENCODE. Дата обращения: 13 мая 2018. Архивировано 8 апреля 2018 года.
