Генная онтология
«Генная онтология» (англ. Gene Ontology, или GO) — биоинформатический проект, посвященный созданию унифицированной терминологии для аннотации генов и генных продуктов всех биологических видов[1].
Целью проекта является поддержание и пополнение определённого списка атрибутов генов и их продуктов, составление аннотаций генов и продуктов, разработка инструментов для работы с базой данных проекта, а также для анализа новых экспериментальных данных, в частности, анализ представленности функциональных групп генов. Стоит отметить, что в проекте GO был создан язык разметки для классификации данных (информации о генах и их продуктах, то есть РНК и белках, а также их функцях), который позволяет быстро находить систематизированную информацию о продуктах генов[2][3][4].
«Генная онтология» является частью более масштабного проекта по классификации — «Открытые биомедицинские онтологии» (OBO)[5].
История и текущее состояние
Онтологии в информатике используются для формализации определенных областей знаний с помощью системы данных об объектах реального мира и связях между ними (т. н. база знаний). В биологии и смежных дисциплинах возникла проблема отсутствия универсального стандарта терминологии. Термины, выражающие сходные понятия, но применяемые для разных биологических видов, разных областей исследований или даже внутри разных групп учёных, могут иметь принципиально разное значение, что затрудняет обмен данными. В связи с этим задачей проекта «Генная онтология» стало создание онтологии терминов, отражающих свойства генов и их продуктов и применимых к любым организмам[2][3][4].
«Генная онтология» была создана в 1998 году консорциумом ученых, изучавших геномы трех модельных организмов: Drosophila melanogaster (плодовая мушка), Mus musculus (мышь) и Saccharomyces cerevisiae (пекарские дрожжи)[6]. Затем многие базы данных для других модельных организмов присоединились к Консорциуму GO, тем самым способствуя не только расширению базы аннотаций, но и созданию сервисов для просмотра и применения данных.
Консорциум GO (GOC) — это множество биологических баз данных и исследовательских групп, активно участвующих в проекте «Генная онтология»[7]. К нему относятся несколько баз данных для различных модельных организмов, общие белковые базы данных, группы разработчиков программного обеспечения и редакторы «Генной онтологии».
«Генная онтология» является масштабным и быстро развивающимся проектом. По состоянию на сентябрь 2011 года «Генная онтология» содержала более 33 тысяч терминов и около 12 млн аннотаций генных продуктов, применимых к более 360 тыс. живых организмов[2]. По истечении 2016 года количество терминов превысило 44 тысячи экземпляров, в то время как количество организмов, аннотированных в данной базе знаний, превзошло отметку в 460 тысяч особей[3]
В течение нескольких последних лет Консорциум GO внедрил ряд изменений онтологии для увеличения количества, качества и специфичности аннотаций GO. К 2013 году число аннотаций превысило 96 млн. Качество аннотаций было улучшено посредством автоматизированной проверки качества. Также улучшилась аннотация данных, представленных в базе GO, были добавлены новые термины. [4]. В 2007 году был создан новый сервис InterMine[8], целью которого является интеграция геномных данных из большого количества разрозненных источников, и облегчение вычислительных задач, таких как поиск конкретных геномных областей и осуществление статистических тестов. Изначально проект был создан для интеграции данных для Drosophila, но на данный момент включает большое количество модельных организмов. В последние годы ведется разработка сервиса LEGO (Linked Expressions using the Gene Ontology), позволяющего исследовать взаимодействие различных аннотаций в базе GO,объединяя их в более общие модели генов и их функций [3].
Структура и термины
Следует понимать, что «Генная онтология» описывает комплексные биологические феномены, а не конкретные биологические объекты. База данных «Генной онтологии» включает три независимых словаря[1][9]:
- Молекулярные функции (англ. molecular function) — классификация по специфической функции продукта гена (белка или РНК) на молекулярном уровне, например, связывание углеводов или АТФазная активность.
- Биологические процессы (англ. biological process) — классификация по комплексному процессу, обычно необходимому для жизнедеятельности организмов и происходящему благодаря осуществлению последовательности молекулярных реакций, например, митоз или биосинтез пуринов.
- Клеточные компоненты (англ. cellular component) — классификация по части клетки или внеклеточного пространства, где осуществляется функция продукта гена, например, ядро или рибосома.
Каждый термин в «Генной онтологии» имеет ряд атрибутов: уникальный цифровой идентификатор, название, словарь, к которому термин принадлежит, и определение. Термины могут иметь синонимы, которые делятся на точно соответствующие значению термина, более широкие, более узкие и имеющие некоторое отношение к термину. Также могут присутствовать такие атрибуты, как ссылки на источники, на другие базы данных и комментарии по значению и использованию термина[1][9].
Онтология построена по принципу ориентированного ациклического графа: каждый термин связан с одним или несколькими другими терминами через различного типа отношения. Выделяют следующие типы отношений[1]:
- «A is a B» — A является частным случаем B,
- «A part of B» — A является частью B,
- «B has part A» — B включает A,
- «A regulates B» — А регулирует В,
- «A positively regulates B» — А положительно регулирует В,
- «A negatively regulates B» — А отрицательно регулирует В,
- «A occurs in B» — А встречается при В.
Пример одного из терминов проекта GO[10]:
id: GO:0043417 name: negative regulation of skeletal muscle tissue regeneration namespace: biological_process def: "Any process that stops, prevents, or reduces the frequency, rate or extent of skeletal muscle regeneration." [GOC:jl] synonym: "down regulation of skeletal muscle regeneration" EXACT [] synonym: "down-regulation of skeletal muscle regeneration" EXACT [] synonym: "downregulation of skeletal muscle regeneration" EXACT [] synonym: "inhibition of skeletal muscle regeneration" NARROW [] is_a: GO:0043416 ! regulation of skeletal muscle tissue regeneration is_a: GO:0048640 ! negative regulation of developmental growth relationship: negatively_regulates GO:0043403 ! skeletal muscle tissue regeneration
В базу данных «Генной онтологии» постоянно вносятся изменения и дополнения как кураторами проекта GO, так и другими исследователями. Предлагаемые поправки пользователей проверяются редакторами проекта и применяются в случае одобрения поправок[9].
Файл, содержащий всю базу данных[10], может быть получен в различных форматах на официальном сайте «Генной онтологии», а также термины доступны онлайн с помощью браузера «Генной онтологии» AmiGO. Кроме того, с его помощью возможно извлечение массива данных генных продуктов, относящихся к тому или иному термину. Также на сайте можно скачать карты соответствия терминов GO другим системам классификации[11].
Аннотации
Аннотирование геномов нацелено на получение информации о свойствах генных продуктов. В аннотациях GO для этого используются термины «Генной онтологии». Члены Консорциума GO выкладывают свои аннотации на сайте «Генной онтологии», где аннотации доступны для прямого скачивания, либо для просмотра в браузере AmiGO[12].
В аннотации гена содержатся следующие данные: название и идентификатор генного продукта; соответствующий термин GO; тип данных, на которых основана аннотация (англ. evidence code); ссылка на источник; а также создатель и дата создания аннотации. Для типов данных, указывающих на достоверность аннотации (evidence code), существует особая онтология, относящаяся к проекту ОВО[13]. Она включает различные методы аннотирования: как осуществляемые вручную, так и автоматические. Например[1]:
- IDA (Inferred from Direct Assay) — экспериментальные данные.
- TAS (Traceable Author Statement) — данные из научной публикации.
- IMP (Inferred from Mutant Phenotype) — данные получены на основе мутантного фенотипа.
- IGI (Inferred from Genetic Interaction) — на основе взаимодействия генов.
- IPI (Inferred from Physical Interaction) — на основе физического взаимодействия.
- RCA (Inferred from Reviewed Computational Analysis) — на основе достоверного вычислительного анализа.
- ISS (Inferred from Sequence Similarity) — на основе сходства последовательностей.
- IGC (Inferred from Genomic Context) — на основе геномного контекста.
- IEP (Inferred from Expression Pattern) — на основе характера экспрессии.
- NAS (Non-traceable Author Statement) — на основе неопубликованных данных.
- IEA (Inferred from Electronic Annotation) — на основе автоматического извлечения из других баз аннотаций.
- IC (Inferred by Curator) — данные приписаны куратором.
- ND (No biological Data available) — достоверные данные отсутствуют.
По данным на сентябрь 2012 года более 99 % всех аннотаций «Генной онтологии» были получены автоматическим путём[4]. Поскольку такие аннотации не проверяются вручную, то Консорциум GO рассматривает их как менее достоверные, и лишь часть из них доступна в браузере AmiGO. Полную базу аннотаций можно скачать на сайте «Генной онтологии».
AmiGO
AmiGO[9] — это веб-приложение (сервис GO), которое позволяет пользователям запрашивать, находить и визуализировать термины GO и аннотации генных продуктов. Кроме того, приложение содержит инструмент BLAST (есть в AmiGO 1, был убран в AmiGO 2), сервисы, позволяющие анализировать большие массивы данных и интерфейс для поиска непосредственно в базе данных GO[14]. AmiGO может быть использован онлайн на сайте «Генной онтологии» для доступа к данным, предоставляемых Консорциумом GO, либо может быть загружен и установлен для локального применения к любой базе данных, построенной по принципу GO. AmiGO 2 является открытым и свободным ПО.
Визуализация
Визуализация представляет возможность пользователю строить граф, характеризующий генную онтологию для конкретного GO термина. Существует два формата ввода данных [15]:
- Стандартный формат — список id GO терминов (например, GO:1234567), разделенных пробелом.
- Продвинутый формат — описание узлов в графе в формате JSON (JavaScript Object Notation). В зависимости от предписанного формата может меняться содержимое узла (добавление дополнительных аннотаций, изменение цветов и т.д.)
Пример JSON ввода:
{"GO:0002244":{"title": "foo",
"body": "bar",
"fill": "#ccccff",
"font": "#0000ff",
"border":"red"},
"GO:0005575":{"title":"alone",
"body":""},
"GO:0033060":{}}
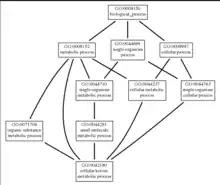
Кодирование отношения с помощью цвета:
| Отношение | Цвет |
|---|---|
| is_a | blue |
| part_of | lightblue |
| develops_from | brown |
| regulates | black |
| negatively_regulates | red |
| positively_regulates | green |
Визуализация термина состоит в построении графа от вершины, представляющей исходный GO термин, до корневой вершины, которая представлена названием одного из трех главных словарей: биологические процессы, молекулярные функции и клеточные компоненты[1][9].
Обзор данных
Помимо возможности создания графов, отображающих генную онтологию GO термина, в AmiGO также реализованы несколько инструментов, способных дать пользователю представление о данных GO проекта. Среди них[14]:
- Базовая статистика — информация о данных GO в виде различных гистограмм (например, распределение аннотаций и их характера (экспериментальные/не экспериментальные) относительно различных видов живых организмов). Реализовано с помощью сервиса Plotly.
- Развернутый браузер (drill-down browser) — позволяет исследовать онтологии и аннотации, двигаясь по иерархии, начиная от высокого уровня. В данном инструменте возможно использование различных фильтров.
- Поисковые шаблоны — интерфейс, представляющий из себя боксы для ввода данных и выполнения для них типичных запросов к базе GO.
GOOSE
GOOSE[16]— среда запросов SQL, реализованная в онлайн режиме и доступная пользователям AmiGO сервиса, для создания наборов данных. Данный сервис использует синтаксис SQL для составления различных запросов в базу GO. Также для снижения нагрузки на систему доступны зеркала EBI (Великобритания, Кембридж), Berkeley BOP и Berkeley BOP (lite) (оба находятся в городе Беркли, штат Калифорния).
Кроме непосредственного написания запроса вручную возможно использование шаблонов для частичного упрощения данной задачи. Типичный запрос в базу данных представлен ниже (поиск максимальной глубины дерева для клеточной компоненты)[16]:
SELECT distance as max from graph_path, term WHERE graph_path.term2_id =term.id and term.term_type = 'cellular_component' ORDER BY distance desc limit 1;
База данных в GO имеет сложную структуру и состоит из множества таблиц. Основные базы данных[16] :
- termdb — база данных, содержащая информацию о GO терминах и отношениях между ними.
- assocdb — база данных, содержащая GO лексику и аннотации между GO терминами и генными продуктами. Данная БД находится в зависимости от termdb.
- seqdb — база данных, содержащая GO термины, генные продукты и последовательности, которые аннотированы с этими генными продуктами. Находится в зависимости от termdb и assocdb. Кроме того, реализована БД seqbdlite, в которой отсутствуют IEA аннотации.
Возможны следующие форматы экспорта данных в результате запроса[16]:
- .rdf — xml
- .obo — xml
- .owl — OWL
- .tables
- .sql
PANTHER
PANTHER (англ. Protein Analysis THrough Evolutionary Relationships) — это огромная база данных генов/белковых семейств и функционально похожих на них подсемейств, которые могут быть использованы для классификации функционального спектра генных продуктов[17]. PANTHER — это часть GO проекта, главной целью которой является классификация белков и их генов.
В PANTHER база данных редактируется не только персоналом проекта, но также и за счет классификационных алгоритмов. Протеины классифицируются в соответствии с их принадлежностью к семействам (и подсемействам), молекулярной функции или биологическому процессу[17].
Главное применение PANTHER состоит в выяснении функций необъясненных генов любого организма, основанном на их эволюционных взаимоотношениях с генами, о функциях которых есть информация в БД. Используя генные функции, онтологию и статистико-аналитические методы, PANTHER позволяет биологам анализировать большие данные, целые геномы, получаемые с помощью секвенирования или исследования генной экспрессии[18].
Основные инструменты, доступные на веб-сайте PANTHER[18]:
- Анализ списка генов:
- Функциональный анализ генов и их классификация — включает информацию о семействе и подсемействе генов, их молекулярной функции, биологических процессах, в которые они вовлечены, о клеточных компонентах, где их можно обнаружить. Эти данные могут быть представлены как в виде списка, так и в виде круговой диаграммы.
- Статистические тесты (Overrepresentation test и enrichment test) предназначены для нахождения общих биологических функций генов, поданных на вход пользователем.
- Исследование онтологии данных, аннотаций между терминами и семействами, подсемействами PANTHER.
- Поиск белковых последовательностей в библиотеках PANTHER
- Анализ однонуклеотидных полиморфизмов (cSNP) — оценка вероятности несинонимичной однонуклеотидной мутации к изменению функциональной деятельности гена.
GO Slimmer
GO Slimmer[19] — инструмент, позволяющий сопоставить подробные аннотации набора генов с одним или несколькими родительскими терминами более высокого уровня (GO slim терминами). GO slim термин — это урезанные версии GO онтологии, содержащие подмножество терминов всего GO без подробного описания специфичных низкоуровневых терминов.
Использование GO Slimmer позволяет представлять аннотации GO генома, анализировать результаты микромассивов экспрессий или коллекций комплементарных ДНК, когда необходима обширная классификация функций генных продуктов[19].
Результат работы данного алгоритма представлен тремя колонками[19]:
- GO Slim термин
- Количество найденных генных продуктов в запросе, соответствующих заданному slim термину.
- Расположение термина в трех основных частях GO онтологии: биологический процесс (P), клеточная компонента (C), и молекулярная функция (F).
AmiGO версия данного инструмента написана на Perl скрипте map2slim[19]. Кураторы проекта отмечают, что в настоящее время GO slimmer сервис загружен, и входные данные внушительных размеров могут негативно сказаться на его работе. Время работы сервиса для обработки входных последовательностей ограничено.
BLAST
BLAST (англ. Basic Local Alignment Search Tool) — семейство компьютерных программ, служащих для поиска гомологов белков или нуклеиновых кислот, для которых известна последовательность, при помощи выравнивания. Используя BLAST, исследователь может сравнить имеющуюся у него последовательность с последовательностями из базы данных и найти наиболее сходные с данной, которые будут являться предполагаемыми гомологами.
Реализация данного инструмента в AmiGO 1 представлена в виде пакета WU-BLAST, разработанного Вашингтонским университетом в Сент-Луисе (Washington University in St. Louis).[20]
В AmiGO 2 данный инструмент (GO BLAST) был убран, однако можно воспользоваться поиском в AmiGO 1. Инструмент позволяет фильтровать результаты поиска по генному продукту, базе данных, таксономической принадлежности, словарю GO, OBO аннотации.
Term Matrix
Term Matrix [21](матрица терминов) — инструмент AmiGO для изучения информации о схожести генной продукции терминов. Результатом его работы является матрица, элементами которой является количество генных продуктов, аннотированных для конкретной пары GO терминов. Для использования функции [21]необходимо ввести список идентификаторов GO, чтобы увидеть совместные аннотации - количество общих генных продуктов, аннотированных по парам терминов. Есть возможность задавать конкретные виды или таксоны. Подцветка тепловой карты может быть осуществлена в виде градации от чёрного к белому, либо используя стандартную палитру карты.
OBO-Edit
OBO-Edit[22] — это находящийся в открытом доступе редактор онтологий, разработанный и поддерживаемый Консорциумом GO. Он реализован на языке Java и использует подход, основанный на работе с графами, для визуализации и редактирования онтологий. OBO-Edit имеет удобный интерфейс поиска и фильтрации, позволяющий визуализировать и разделять подмножества терминов GO. Интерфейс можно настраивать в соответствии с предпочтениями пользователя. Также OBO-Edit позволяет автоматически создавать новые связи на основе существующих отношений и их свойств. Несмотря на то, что OBO-Edit был разработан для биомедицинских онтологий, он может быть использован для просмотра и редактирования любой онтологии.
PAINT
PAINT[23] (англ. Phylogenetic Annotation and INference Tool) — JAVA-приложение, являющееся частью проекта аннотации геномов (Reference Genome Annotation Project), базирующееся на принципе «транзитивной аннотации». Понятие транзитивной аннотации состоит в присваивании экспериментально установленной функции одного гена другому, ввиду схожести их нуклеотидных последовательностей.
С помощью PAINT пользователь может исследовать экспериментальные аннотации для генов из отдельного семейства и использовать данную информацию для заключения новых аннотаций для членов семейства генов, которые ещё не были достаточно изучены[3]. Инструментарий PAINT позволяет строить модель, которая объясняла бы наследование или потерю той или иной функциональности гена в пределах отдельных ветвей филогенетических деревьев. Новые аннотации, полученные с помощью данной модели, именуются как аннотации на основе биологического предка (IBA — Inferred from Biological Ancestry)[1].
Данное приложение бесплатно доступно для загрузки на Github.
См. также
- Онтология в информатике
- «Открытые биомедицинские онтологии»
Примечания
- du Plessis L., Skunca N., Dessimoz C. The what, where, how and why of gene ontology — a primer for bioinformaticians (англ.) // Brief Bioinform. : journal. — 2011. — November (vol. 12, no. 6). — P. 723—735. — doi:10.1093/bib/bbr002. — PMID 21330331.
- The Gene Ontology Consortium. The Gene Ontology: enhancements for 2011. (англ.) // Nucleic Acids Res. : journal. — 2012. — January (vol. 40, no. Database issue). — P. D559—64. — doi:10.1093/nar/gkr1028. — PMID 22102568.
- The Gene Ontology Consortium. Expansion of the Gene Ontology knowledgebase and resources (англ.) // Nucleic Acids Res. : journal. — 2017. — January (vol. 45, no. D1). — P. D331—D338. — doi:10.1093/nar/gkw1108.
- The Gene Ontology Consortium. Gene Ontology annotations and resources (англ.) // Nucleic Acids Res. : journal. — 2013. — January (vol. 41, no. Database issue). — P. D530—5. — doi:10.1093/nar/gks1050. — PMID 23161678.
- Smith B., Ashburner M., Rosse C., Bard J., Bug W., Ceusters W., Goldberg L.J., Eilbeck K., Ireland A., Mungall C.J., Leontis N., Rocca-Serra P., Ruttenberg A., Sansone S.A., Scheuermann R.H., Shah N., Whetzel P.L., Lewis S. The OBO Foundry: coordinated evolution of ontologies to support biomedical data integration (англ.) // Nature Biotechnology : journal. — Nature Publishing Group, 2007. — November (vol. 25, no. 11). — P. 1251—1255. — doi:10.1038/nbt1346. — PMID 17989687.
- Ashburner M., Ball C.A., Blake J.A., Botstein D., Butler H., Cherry J.M., Davis A.P., Dolinski K., Dwight S.S., Eppig J.T., Harris M.A., Hill D.P., Issel-Tarver L., Kasarskis A., Lewis S., Matese J.C., Richardson J.E., Ringwald M., Rubin G.M., Sherlock G. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium (англ.) // Nat. Genet. : journal. — 2000. — May (vol. 25, no. 1). — P. 25—9. — doi:10.1038/75556. — PMID 10802651.
- The GO Consortium.
- Richard N. Smith, Jelena Aleksic, Daniela Butano, Adrian Carr, Sergio Contrino. InterMine: a flexible data warehouse system for the integration and analysis of heterogeneous biological data (англ.) // Bioinformatics. — 2012-12-01. — Vol. 28, iss. 23. — P. 3163—3165. — ISSN 1367-4803. — doi:10.1093/bioinformatics/bts577.
- Carbon S., Ireland A., Mungall C.J., Shu S., Marshall B., Lewis S; AmiGO Hub; Web Presence Working Group. AmiGO: Online access to ontology and annotation data. (англ.) // Bioinformatics : journal. — 2008. — January (vol. 25, no. 2). — P. 288—289. — doi:10.1093/bioinformatics/btn615. — PMID 19033274.
- The GO Consortium. База данных «Генной онтологии» в формате .obo (OBO 1.2 flat file).
- The GO Consortium. Mappings of External Classification Systems to GO. (недоступная ссылка). Дата обращения: 9 мая 2014. Архивировано 25 июня 2014 года.
- The GO Consortium. Search annotations..
- The Open Biological and Biomedical Ontologies: Evidence Codes.. Архивировано 26 ноября 2009 года.
- Руководство по работе с AmiGO..
- The GO Consortium. Manual Visualization.
- The GO Consortium. Manual GOOSE (недоступная ссылка). Дата обращения: 15 марта 2017. Архивировано 6 июня 2017 года.
- Huaiyu Mi, Xiaosong Huang, Anushya Muruganujan, Haiming Tang, Caitlin Mills, Diane Kang, and Paul D. Thomas. PANTHER version 11: expanded annotation data from Gene Ontology and Reactome pathways, and data analysis tool enhancements (англ.) // Nucleic Acids Research : journal. — 2016. — 28 November (vol. 45, no. Database). — P. D183—D189. — doi:10.1093/nar/gkw1138.
- The GO Consortium. Manual PANTHER.
- The GO Consortium. Manual GO Slimmer.
- The GO Consortium. Manual GO BLAST.
- Gene Ontology Consortium. AmiGO 2: Matrix (англ.). amigo2.berkeleybop.org. Дата обращения: 4 апреля 2018.
- Day-Richter J., Harris M.A., Haendel M., Gene Ontology OBO-Edit Working Group, Lewis S. OBO-Edit – an ontology editor for biologists. (неопр.) // Bioinformatics. — 2007. — August (т. 23, № 16). — С. 2198—2200. — doi:10.1093/bioinformatics/btm112. — PMID 17545183.
- The GO Consortium. Manual PAINT.
Ссылки
- The Gene Ontology — официальный сайт проекта. (англ.)
- AmiGO — браузер «Генной онтологии». (англ.)
- PAINT — бесплатное приложение на Github. (англ.)
- Term Matrix — инструмент AmiGO. (англ.)
- BLAST — инструмент AmiGO. (англ.)
- GO slimmer — инструмент AmiGO. (англ.)
- map2slim — скрипт GO slimmer. (англ.)
- GO data scheme — схема базы данных GO. (англ.)
- Plotly — сервис инфорграфики. (англ.)
- Visualization — инструмент AmiGO. (англ.)
- Annotation Database — полная база данных аннотаций. (англ.)

{kind=link}