Оценки качества сборки генома
В вычислительной биологии для оценки качества сборки генома используются различные показатели, наиболее известными из которых являются статистики длин набора контигов (или скэффолдов) N50 и L50. Эти статистики являются мерами качества сборки генома. N50 — максимальная длина контига такая, что суммарная длина всех контигов не короче данного составляет не менее половины общей дины всех контигов сборки.[1] N50 сходна с медианой или средним значением длин, но в её расчете больший вес имеют длинные контиги. L50 — минимальное число контигов, чья суммарная длина не менее половины суммарной длины сборки. Существуют также сходные с N50 и L50 статистики N90, NG50[2] и D50[3].
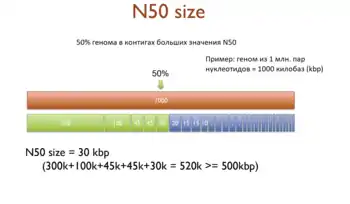
Определения
N50
Статистика N50 характеризует качество сборки с точки зрения её непрерывности. N50 определяется как самый короткий контиг при суммировании длин минимального числа контигов для получения суммы, большей или равной половине длины сборки генома. Можно воспринимать N50 как центр масс распределения длин контигов. Суммарная длина последовательностей контигов длиннее, чем N50, примерно равна суммарной длине последовательностей короче N50.
Сравнение значений N50 разных сборок имеет смысл лишь тогда, когда длины сборок равны.
N50 можно описать как взвешенную медиану: 50 % сборки содержится в контигах, длина которых меньше или равна значению N50.
L50
L50 — это минимальное количество контигов, которые при суммировании их длин дают число, большее или равное половине длины сборки. Также это номер длины контига, соответствующего статистике N50, в упорядоченном по убыванию списке длин всех контигов сборки.
N90
По аналогии с N50, N90 — это самый короткий контиг при суммировании длин минимального числа контигов для получения суммы, большей или равной 90 % от длины сборки. Иначе: это такое число, что сумма длин контигов такой или большей длины — 90 % от длины сборки (или сумма длин контигов такой или меньшей длины — 10 % от длины сборки). Для примера выше N90 равна 4. N90 всегда меньше или равна N50.
NG50
Как уже упоминалось выше, сравнение значений N50 сборок значимо разных длин обычно неинформативно, даже если речь идет о разных сборках одного и того же генома. Для решения этой проблемы придумана модификация N50 — статистика NG50. Вычисляются эти статистики одинаково, кроме того что вместо суммарной длины всех контигов для расчета NG50 используется длина генома (известная или предполагаемая).
Чаще всего NG50 не превосходит N50 (так как обычно длина сборки больше длины генома).
D50
Статистика D50 (также называется D50-тест) похожа на N50, но для описания сборок генома используется значительно реже. Это наименьшее число d, такое что половина сборки состоит из контигов, длина которых не превосходит d.[3]
Примеры расчета
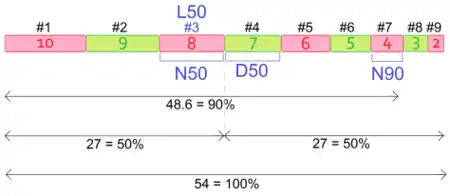
- Пусть длины девяти контигов равны 2, 3, 4, 5, 6, 7, 8, 9, 10. Сумма их длин 54. Чтобы узнать N50, получим число, большее или равное половине длины сборки, сложив длины как можно меньшего числа контигов (по определению N50). Для этого упорядочиваем контиги в порядке убывания их длин: 10, 9, 8, 7, 6, 5, 4, 3, 2. Затем начинаем в этом порядке суммировать длины, пока не получим число, большее или равное 27 (54, деленное на 2). 10 + 9 + 8 = 27. Значит, нам необходимо как минимум 3 контига, длина самого короткого из них 8. Следовательно, N50 равна 8, а L50 равна 3. По аналогии N90 равна 4: 10 + 9 + 8 + 7 + 6 + 5 + 4 = 49 > 48.6 = 54 * 0.9. Для расчета NG50 необходимо ввести известную (или предполагаемую) длину генома, пусть 30. Тогда NG50 равна 9: 10 + 9 = 19 > 15 = 30 * 0.5. При расчете D50 располагаем контиги уже не по убыванию, а по возрастанию их длин, далее в этом порядке производим сложение длин до тех пор, пока не получим число, большее или равное половине длины сборки: 2 + 3 + 4 + 5 + 6 + 7 = 27. 7 — минимальное число, которое не превосходят длин всех сложенных контигов, то есть D50 равна 7. Те же рассуждения, но в виде иллюстрации, можно проследить на рисунке справа.
- Пусть есть две сборки генома А и В, соответствующие геномам двух разных видов. А состоит из 6 контигов с длинами: 80 кб, 70 кб, 50 кб, 40 кб, 30 кб, 20 кб. Длина сборки 290 кб. N50 равна 70 кб (80 + 70 = 160 кб, что больше 290 / 2 = 145 кб). L50 равна 2. B состоит из контигов тех же длин, что и А, с добавлением ещё двух с длинами: 10 кб, 5 кб. Длина сборки 305 кб. N50 равна 50 кб (80 + 70 + 50 = 200 кб, что больше 305 / 2 = 152.5 кб). L50 равна 3. Если известный или предполагаемый размер генома для сборки A равен 500 кб, то NG50 равна 30 кб (80 + 70 + 50 + 40 + 30 = 270, что больше 500 / 2 = 250). В то же время если размер генома для сборки B равен 350 кб, то NG50 равна 50 кб (80 + 70 + 50 = 200 кб, что больше 350 / 2 = 175 кб). На этом примере видно, что можно значимо увеличить N50 и уменьшить L50, если просто убрать из сборки самые короткие контиги.
Альтернативное вычисление
Для списка L положительных целых чисел можно математически вычислить N50 следующим образом:
- Создать другой список L' , идентичный L за исключением того, что n-ный элемент в L заменен на n собственных копий.
- Медиана L' — это N50 для L. (10 % квантиль L' является статистикой N90).
Например: если L = (2, 2, 2, 3, 3, 4, 8, 8), тогда L' состоит из шести двоек, шести троек, четырёх четверок и шестнадцати восьмёрок. То есть, L' содержит в 2 раза больше двоек, чем L, в 3 раза больше троек, в 4 раза больше четверок и так далее. Медиана множества L' , состоящего из 32 элементов, это среднее между шестнадцатым и семнадцатым элементами (4 и 8 соответственно), таким образом N50 = 6. Можно заметить, что сумма значений в списке L, которые меньше или равны полученного значения N50, равняется 16 = 2 + 2 + 2 + 3 + 3 + 4, и сумма значений в списке L, которые больше или равны 6, также 16 = 8 + 8.
Примечания
- Lander et al. International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. (англ.) // Nature. — 2001. — 1 February (no. 409(6822)). — P. 860—921.
- Dent Earl, Keith Bradnam, John St John, Aaron Darling, Dawei Lin. Assemblathon 1: A competitive assessment of de novo short read assembly methods (англ.) // Genome Research. — 2011-12-01. — Vol. 21, iss. 12. — P. 2224—2241. — ISSN 1549-5469 1088-9051, 1549-5469. — doi:10.1101/gr.126599.111.
- Han, J.; Sanders, C. M.; Wang, C.; Yang, Q.; Wimbish, J.; Boone, B. E.; Thomas, S. J.; Levy, S.E. Measurement of T cell repertoire diversity in the peripheral blood by novel multiplex PCR and high-performance sequencing methods (англ.) // Basel Switzerland. — 2012. — 2 September. Архивировано 5 октября 2015 года.
Литература
- JR; Miller; Koren, S; Sutton, G. Assembly algorithms for next-generation sequencing data (англ.) // Genomics : journal. — Academic Press, 2010. — Vol. 95, no. 6. — P. 315—327. — doi:10.1016/j.ygeno.2010.03.001. — PMID 20211242.
- Earl, D; Bradnam, K; St. John, J; Darling, A; Lin, D; Fass, J; Yu, HOK; Buffalo, V; Zerbino, DR; Diekhans, M; Nguyen, N; Ariyaratne, PN; Sung, W-K; Ning, Z; Haimel, M; Simpson, JT; Fonseca, NA; Birol, I; Docking, TR; Ho, IY; Rokhsar, DS; Chikhi, R; Lavenier, D; Chapuis, G; Naquin, D; Maillet, N; Schatz, MC; Kelley, DR; Phillippy, AM; Koren, S. Assemblathon 1: A competitive assessment of de novo short read assembly methods (англ.) // Genome Research : journal. — 2011. — Vol. 21, no. 12. — P. 2224—2241. — doi:10.1101/gr.126599.111. — PMID 21926179.
Ссылки
- Arachne wiki at Broad Institute
- L50-vs-N50 blog post (07-Oct-2015)