Лексическое сходство
Лексическое сходство (в лингвистике) — мера того, до какой степени слова двух данных языков лексически сходны. Лексическое сходство, равное единице (или 100 %) означает полное совпадение двух данных языков, тогда как равенство 0 означает полное отсутствие в них общих слов.
Существуют разные способы определения лексического сходства и результаты, полученные разными способами, соответственно, будут различаться. Например, метод, принятый в Этнологии (энциклопедия), состоит в том, чтобы сравнивать стандартизированный список слов в разных языках и находить сходные среди них одновременно как по написанию, так и по смыслу. Используя этот метод, было найдено, что английский язык имеет лексическое сходство с немецким 60 % и с французским 27 %.
Лексическое сходство может быть использовано, чтобы оценить степень генетического родства между двумя данными языками. Лексическое сходство более 85 % означает, что два сравниваемые языка относятся друг к другу, вероятно, как связанные диалекты.
Лексическое сходство — это только один из индикаторов взаимнопонятности двух языков, так как последняя часто зависит от степени морфологического, фонетического и грамматического сходств языков. Стоит заметить, что лексическое сходство сильно зависит от того, какой стандартизованный список слов рассматривается. Например, лексическое сходство между английским и французским значительно в областях связанных с культурой, судебным производством, и гораздо меньше в области основных функциональных слов. В отличие от взаимнопонятности, лексическое сходство может быть только симметричным для двух языков.
В таблице ниже представлены (по данным справочника Ethnologue[1]) значения лексического сходства для пар германских, романских и славянских языков (прочерк означает отсутствие данных).
| Код языка | Язык 1 ↓ | Коэффициенты лексического сходства | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Каталанский | Английский | Французский | Немецкий | Итальянский | Португальский | Румынский | Романшский | Русский | Сардинский | Испанский | ||
| cat | Каталанский | 1 | - | - | - | 0.87 | 0.85 | 0.73 | 0.76 | - | 0.75 | 0.85 |
| eng | Английский | - | 1 | 0.27 | 0.60 | - | - | - | - | 0.24 | - | - |
| fra | Французский | - | 0.27 | 1 | 0.29 | 0.89 | 0.75 | 0.75 | 0.78 | - | 0.80 | 0.75 |
| deu | Немецкий | - | 0.60 | 0.29 | 1 | - | - | - | - | - | - | - |
| ita | Итальянский | 0.87 | - | 0.89 | - | 1 | - | 0.77 | 0.78 | - | 0.85 | 0.82 |
| por | Португальский | 0.85 | - | 0.75 | - | - | 1 | 0.72 | 0.74 | - | - | 0.89 |
| ron | Румынский | 0.73 | - | 0.75 | - | 0.77 | 0.72 | 1 | 0.72 | - | - | 0.71 |
| roh | Романшский | 0.76 | - | 0.78 | - | 0.78 | 0.74 | 0.72 | 1 | - | 0.74 | 0.74 |
| rus | Русский | - | 0.24 | - | - | - | - | - | - | 1 | - | - |
| srd | Сардинский | 0.75 | - | 0.80 | - | 0.85 | - | - | 0.74 | - | 1 | 0.76 |
| spa | Испанский | 0.85 | - | 0.75 | - | 0.82 | 0.89 | 0.71 | 0.74 | - | 0.76 | 1 |
| Каталанский | Английский | Французский | Немецкий | Итальянский | Португальский | Румынский | Романшский | Русский | Сардинский | Испанский | ||
| Язык 2 → | cat | eng | fra | deu | ita | por | ron | roh | rus | srd | spa | |
Использование списка Сводеша при сравнении русского языка с другими славянскими языками даёт следующую картину[2]:
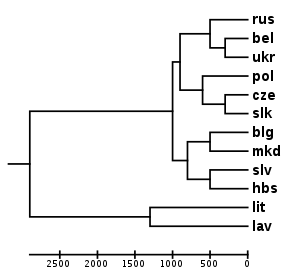
| Сопоставляемый язык | Процент общей лексики с русским языком |
|---|---|
| Белорусский | 86% |
| Украинский | 86% |
| Польский | 77% |
| Чешский / словацкий | 74% |
| Болгарский | 74% |
| Словенский | 74% |
| Сербский | 71% |
| Македонский | 70% |
Данные о сходстве могут быть использованы для исследования филогенетических связей с другими языками.
Примечания
- См., например, данные по лексическому сходству для французского, немецкого, английского
- Girdenis A., Maziulis V. Baltu kalbu divercencine chronologija // Baltistica. T. XXVII (2). - Vilnius, 1994. - P. 9.