Спутывающая переменная
Спутывающая переменная, спутывающий фактор, конфаундер — переменная в статистике, которая влияет как на зависимую, так и на независимую переменные, результатом чего является ложная зависимость. Спутывание — это причинная концепция, элемент каузальной модели, и как таковая она не может быть описана в терминах корреляций или ассоциаций[1][2][3]. Конфаундеры являются одним из видов переменных в причинном анализе наряду с модераторами, медиаторами и коллайдерами[4][5][6].
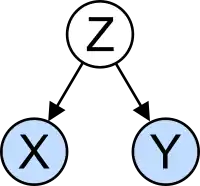
Определение
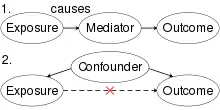
Спутывание можно определить в терминах генерации данных (как на рисунке выше). Пусть X — некоторая независимая переменная, а Y — некоторая зависимая переменная. Чтобы оценить влияние X на Y, статистик должен исключить влияние посторонних переменных, которые влияют как на X, так и на Y. Мы говорим, что X и Y спутываются с некоторой переменной Z всякий раз, когда Z причинно влияет как на X, так и на Y.
Пусть — вероятность события Y = y при гипотетическом вмешательстве X = x. X и Y не спутываются тогда и только тогда, когда выполняется следующее условие:


для всех значений вероятностей события X = x и события Y = y, где — это условная вероятность X = x. Интуитивно это равенство утверждает, что X и Y не спутываются, если наблюдаемая связь между ними такая же, как и связь, которую можно было бы измерить в контролируемом эксперименте с рандомизированным x.

В принципе, определяющее равенство можно проверить на основе модели генерации данных, предполагая, что у нас есть все уравнения и вероятности, связанные с моделью. Это делается путём моделирования вмешательства (см. Байесовская сеть) и проверки того, равна ли результирующая вероятность Y условной вероятности . При этом оказывается, что свойств графа достаточно для проверки равенства .

Контроль
Рассмотрим исследователя, пытающегося оценить эффективность лекарственного средства X на основе данных о населении, причём пациенты сами выбирали используемый препарат. Данные показывают, что пол (Z) влияет на выбор пациентом препарата, а также на его шансы на выздоровление (Y). В этом сценарии пол Z нарушает отношения между X и Y, поскольку Z является причиной как X, так и Y :
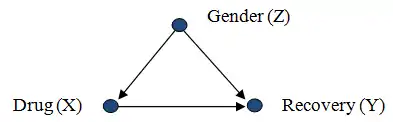
Имеем неравенство

поскольку наблюдаемая величина содержит информацию о корреляции между X и Z, а вмешивающаяся величина — нет (поскольку X не коррелирует с Z в рандомизированном эксперименте). Статистику нужна неискажённая оценка , но в случаях, когда доступны только данные наблюдений, неискажённая оценка может быть получена только путём учёта всех спутывающих факторов, а именно, учёта их различных значений и усреднённого результата. В случае единственного спутывающего фактора Z это приводит к «формуле корректировки»:

что даёт неискажённую оценку причинного воздействия X на Y. Та же формула работает при наличии нескольких спутывающих факторов, за исключением того, что в этом случае выбор набора Z, который гарантировал бы неискажённую оценку, должен производиться с осторожностью. Критерий правильного выбора спутывающих переменных называется бэкдор[7][8] и требует, чтобы выбранный набор Z «блокировал» (или перехватывал) каждый путь от X до Y, который заканчивается стрелкой в X. Такие множества называются «допустимый бэкдор» и могут включать в себя переменные, которые являются не общими причинами X и Y, а их заместителями.
Возвращаясь к примеру с лекарствами, поскольку Z соответствует требованию бэкдор (то есть перехватывает один путь ), то «формула корректировки» валидна:


Таким образом, исследователь может предсказать вероятный эффект от использования препарата на основе наблюдательных исследований, в которых условные вероятности, появляющиеся в правой части уравнения, можно оценить с помощью регрессии.
Вопреки распространённому мнению, добавление ковариат в набор Z может привести к искажению. Типичный контрпример возникает, когда Z является общим результатом X и Y,[9] в этом случае Z не является спутывающим фактором (то есть пустое множество является допустимым для бэкдора) и учёт Z создаст искажение, известное как коллайдер или парадокс Берксона.
В общем случае спутывание можно контролировать с помощью корректировки тогда и только тогда, когда существует набор наблюдаемых ковариат, удовлетворяющих условию бэкдор. Более того, если Z является таким набором, то формула настройки уравнения (3) действительно <4,5>. Do-исчисление Джуды Перла даёт дополнительные условия, при которых P (y | do (x)) можно оценить, не прибегая к корректировке[10].
История
Согласно Morabia (2011)[11] понятие конфаундер происходит от средневекового латинского глагола «confudere» (от латинского: con = с + fusus = складывать или сливать вместе), означающего «смешивать», и, вероятно, было выбрано для обозначения путаницы между причиной, которую нужно оценить, и другими причинами, которые могут повлиять на результат и, таким образом, запутать или помешать желаемой оценке. Фишер использовал слово «спутывание» в своей книге 1935 года «Планирование экспериментов»[12] для обозначения источника ошибки при описании идеального рандомизированного эксперимента. Согласно Vandenbroucke (2004)[13], Лесли Киш[14] впервые использовал слово «спутывание» в современном смысле этого слова для обозначения «несопоставимости» двух или более множеств (например, подвергшихся воздействию и не подвергавшихся воздействию) в ходе наблюдательного исследования.
Формальные условия, которые определяют, почему одни множества «сопоставимы», а другие «несопоставимы», были разработаны в эпидемиологии Гренландом и Робинсом (1986)[15] с использованием языка контрфактов Ежи Неймана (1935)[16] и Дональда Рубина (1974)[17]. Позже они были дополнены графическими критериями, такими как критерий бэкдор (Pearl 1993; Greenland, Pearl and Robins, 1999)[3][7]. Было показано, что графические критерии формально эквивалентны контрфактическому определению[18] но более прозрачны для исследователей, полагающихся на модели процессов.
Типы
В случае оценки риска того или иного фактора для здоровья человека, важно контролировать спутывание, чтобы выделить эффект от конкретной угрозы, такой как пищевая добавка, пестицид или новое лекарство. Для проспективных исследований сложно набирать и проверять добровольцев с одинаковой предысторией (возраст, диета, образование, география и т. д.). А при перекрёстных и повторных исследованиях зависимые переменные могут вести себя сходным образом по несхожим причинам. Из-за невозможности контролировать качества добровольцев, спутывание является особой проблемой для исследований на людях. По этим причинам эксперименты, в отличие от наблюдательных исследований, являются способом избежать большинства форм спутывания.
В некоторых дисциплинах спутывание подразделяется на разные типы. В эпидемиологии одним из типов является «спутывание по показаниям»[19], которое связано с искажением результатов наблюдательных исследований. Поскольку прогностические факторы могут влиять на решения о лечении (и искажать оценки эффектов лечения), контроль известных прогностических факторов может уменьшить эту проблему, но всегда остаётся вероятность того, что забытый или неизвестный фактор не был учтён или что факторы сложно взаимодействуют. Спутывание по показаниям считается наиболее важным ограничением наблюдательных исследований. На рандомизированные испытания не влияет спутывание по показаниям из-за случайного распределения.
Спутывающие переменные также можно разделить на категории в соответствии с их источником: выбор инструмента измерения (операционное спутывание), ситуационных характеристик (процедурное спутывание) или межличностных различий (личностное спутывание).
- Операционное спутывание может иметь место как в экспериментальных, так и в неэкспериментальных исследованиях. Этот тип спутывания возникает, когда мера, предназначенная для оценки конкретной конструкции, непреднамеренно измеряет и что-то ещё[20].
- Процедурное спутывание может иметь место в лабораторном эксперименте или квазиэксперименте. Этот тип спутывания возникает, когда исследователь по ошибке позволяет другой переменной изменяться вместе с управляемой независимой переменной[20].
- Личностное спутывание возникает, когда две или более группы анализируются вместе (например, работники из разных профессий), несмотря на то, что они различаются по одной или нескольким другим (наблюдаемым или ненаблюдаемым) характеристикам (например, по полу)[21].
Примеры
Допустим, что кто-то изучает связь между очерёдностью рождения (1-й ребёнок, 2-й ребёнок и т. д.) и наличием у ребёнка синдрома Дауна. В этом исследовании возраст матери будет спутывающей переменной:
- Более высокий возраст матери напрямую связан с синдромом Дауна у ребёнка
- Более высокий возраст матери напрямую связан с синдромом Дауна, независимо от очерёдности рождения (мать, имеющая первого или третьего ребёнка в возрасте 50 лет, представляет один и тот же риск)
- Возраст матери напрямую связан с очерёдностью рождения (2-й ребёнок, за исключением двойни, рождается, когда мать старше, чем она была на момент рождения 1-го ребёнка)
- Возраст матери не является следствием очерёдности рождения (наличие 2-го ребёнка не влияет на возраст матери)
При оценке риска такие факторы, как возраст, пол и уровень образования, часто влияют на состояние здоровья, поэтому их следует контролировать. Помимо этих факторов, исследователи могут не учитывать или не иметь доступа к данным о других причинных факторах. Примером может служить исследование влияния курения табака на здоровье человека. Курение, употребление алкоголя и диета связаны между собой. Оценка риска, которая учитывает последствия курения, но не учитывает потребление алкоголя или диету, может переоценить риск курения[22]. Курение и спутывание рассматриваются при оценке профессионального риска, например, при оценке безопасности угледобычи[23]. Когда нет большой выборки некурящих или непьющих, занимающихся определённой профессией, оценка риска может быть искажена в сторону выявления отрицательного воздействия профессии на здоровье.
Уменьшение возможности спутывания
Вероятность появления и влияния спутывающих факторов может быть уменьшена за счёт увеличения видов и количества сравнений, выполняемых в исследовании. Если измерения или манипуляции с основными переменными спутаны (то есть существуют операционные или процедурные конфаундеры), анализ подгрупп может не выявить проблем в исследовании. Однако необходимо учесть, что увеличение количества сравнений может создать другие проблемы (см. Множественные сравнения).
Рецензирование — это процесс, который может помочь в сокращении случаев спутывания либо до проведения исследования, либо после того, как был проведён анализ. Рецензирование опирается на коллективную экспертизу в рамках дисциплины для выявления потенциальных слабых мест в дизайне и анализе исследования, включая то, как результаты могут зависеть от спутывания. Точно так же репликация позволяет проверить надёжность результатов исследования при альтернативных условиях исследования или альтернативных подходах к анализу его результатов (например, с учётом возможных спутываний, не выявленных в первоначальном исследовании).
В зависимости от дизайна исследования существуют различные способы для исключения или контроля спутывающих переменных[24]:
- В исследованиях «случай-контроль» спутывающие факторы одинаково распределяются по обеим группам, исследуемой и контрольной. Например, если кто-то хочет изучить причину инфаркта миокарда и считает, что возраст является вероятной спутывающей переменной, то каждому 67-летнему пациенту с инфарктом будет сопоставлен здоровый 67-летний «контрольный» участник. В исследованиях случай-контроль наиболее часто совпадающими переменными являются возраст и пол. Недостаток: исследования случай-контроль возможны только тогда, когда легко найти «контрольных» участников, чей статус по отношению ко всем известным потенциальным спутывающим факторам такой же, как и у исследуемого участника: предположим, что исследование случай-контроль пытается найти причину данного заболевания у человека 1) 45 лет, 2) афроамериканца, 3) с Аляски, 4) заядлого футболиста, 5) вегетарианца и 6) работающего в сфере образования. Теоретически идеальным контролем был бы человек, который, помимо того, что у него нет исследуемой болезни, соответствует всем этим характеристикам и не имеет болезней, которых также не было бы у пациента, — но найти такой контроль является очень сложной задачей.
- При когортных исследованиях также возможна определённая степень соответствия, которая достигается путём включения в исследуемую популяцию только определённых возрастных или половых групп, так чтобы когорты были сопоставимы с точки зрения спутывающих переменных. Например, если можно полагать, что в исследовании риска инфаркта миокарда конфаундерами являются возраст и пол, то в когортном исследовании участвуют только мужчины в возрасте от 40 до 50 лет, которые различаются только по степени физической активности. Недостаток: в когортных исследованиях чрезмерное сужение видов входных данных может привести к тому, что исследователи будут слишком узко определять набор лиц, находящихся в аналогичном положении, для которых, по их мнению, исследование является полезным, так что другие люди, к которым причинно-следственная связь действительно применима, могут потерять возможность воспользоваться рекомендациями исследования. Чрезмерное сужение видов входных данных может так уменьшить размер выборки, что обобщения, сделанные путём наблюдения за членами этой выборки, не будут статистически значимыми.
- Двойной слепой метод скрывает и от исследуемой популяции, и от наблюдателей то, к какой группе относятся участники эксперимента. Поскольку участники не знают, получают они лечение или нет, эффект плацебо должен быть одинаковым и для исследуемой, и для контрольной группы. Поскольку наблюдатели также не знают, к какой группе относятся участники, то у них не должно возникать предвзятости к группам и склонности по-разному интерпретировать результаты.
- Рандомизированное контролируемое испытание — это метод, при котором исследуемая популяция делится случайным образом, чтобы снизить вероятность самостоятельного выбора участниками или предвзятости разработчиков исследования. Перед началом эксперимента исследователи распределяют участников между группами (контрольная, исследуемая, параллельная контрольная), используя процесс рандомизации, такой как использование генератора случайных чисел. Например, при исследовании воздействия физических упражнений выводы были бы менее достоверными, если бы участникам был предоставлен выбор, хотят ли они принадлежать к контрольной группе, которая не будет выполнять программу упражнений, или к группе, которая будет выполнять программу. В этом случае на исследование повлияли бы и другие переменные, помимо физических упражнений, такие как уровень здоровья до эксперимента и мотивация к здоровым занятиям. Экспериментатор, если бы выбор был предоставлен ему, также может выбрать кандидатов, которые с большей вероятностью продемонстрируют результаты, которые он хочет увидеть, или может интерпретировать субъективные результаты (более энергичный, позитивный настрой) в соответствии со своими желаниями.
- Стратификация. Как и в приведённом выше примере, считается, что физическая активность защищает от инфаркта миокарда; возраст при этом считается возможным спутывающим фактором. Собранные данные стратифицируются по возрастным группам — это означает, что связь между активностью и инфарктом будет анализироваться для каждой возрастной группы (страты). Если разные возрастные группы дают очень разные относительные риски, возраст следует рассматривать как спутывающую переменную. Существуют статистические инструменты, в том числе критерий Кохрена — Мантеля — Гензеля, которые учитывают стратификацию наборов данных.
- Контроль за спутыванием путём измерения известных спутывающих факторов и включения их в качестве ковариат — это пример многомерного анализа (см. регрессионный анализ). Многомерный анализ даёт гораздо меньше информации о силе или полярности спутывающей переменной, чем методы стратификации. Например, если многомерный анализ контролирует антидепрессант и не стратифицирует антидепрессанты на TCA и SSRI, то он будет игнорировать тот факт, что эти два класса антидепрессантов имеют противоположные эффекты на инфаркт миокарда, и один из них намного сильнее другого.
У всех этих методов есть свои недостатки:
- Наилучшая защита от получения ложных результатов из-за спутывания часто состоит в том, чтобы отказаться от усилий по стратификации и вместо этого провести рандомизированное исследование достаточно большой выборки, взятой в целом, так что все потенциальные спутывающие переменные (известные и неизвестные) будут случайно распределены по всем исследуемым группам и, следовательно, не будут коррелировать с бинарной переменной.
- Этические соображения: в двойных слепых и рандомизированных контролируемых испытаниях участники не знают, что они получают фиктивное лечение, то есть им может быть отказано в эффективном лечении[25]. Существует вероятность того, что пациенты соглашаются на инвазивную операцию (которая сопряжена с реальными медицинскими рисками) только при том условии, что они получают лечение.
См. также
- Анекдотическое свидетельство — доказательство, основанное на личном опыте
- Причинный вывод — раздел статистики, связанный с установлением причинно-следственных связей между переменными
- Эпидемиологический метод — научный метод в эпидемиологии
- Парадокс Симпсона — вероятностное и статистическое явление
Примечания
- Pearl, J., (2009). Simpson’s Paradox, Confounding, and Collapsibility In Causality: Models, Reasoning and Inference (2nd ed.). New York : Cambridge University Press.
- VanderWeele, T.J. (2013). “On the definition of a confounder”. Annals of Statistics. 41 (1): 196—220. arXiv:1304.0564. DOI:10.1214/12-aos1058. PMID 25544784.
- Greenland, S. (1999). “Confounding and Collapsibility in Causal Inference”. Statistical Science. 14 (1): 29—46. DOI:10.1214/ss/1009211805.
- Field-Fote, Edelle. Mediators and Moderators, Confounders and Covariates: Exploring the Variables That Illuminate or Obscure the “Active Ingredients” in Neurorehabilitation. Journal of Neurologic Physical Therapy, April 2019, Volume 43, Issue 2, P. 83-84, doi: 10.1097/NPT.0000000000000275.
- Adrian E. Bauman, PhD, James F. Sallis, PhD, David A. Dzewaltowski, PhD, Neville Owen, PhD. Toward a Better Understanding of the Influences on Physical Activity: The Role of Determinants, Correlates, Causal Variables, Mediators, Moderators, and Confounders. American Journal of Preventive Medicine, 2002, Volume 23, Number 2S.
- David P. MacKinnon. A Unification of Mediator, Confounder, and Collider Effects. Prevention Science. Volume 22, Pages 1185–1193 (2021).
- Pearl, J., (1993). "Aspects of Graphical Models Connected With Causality, " In Proceedings of the 49th Session of the International Statistical Science Institute, pp. 391—401.
- Pearl, J. (2009). Causal Diagrams and the Identification of Causal Effects In Causality: Models, Reasoning and Inference (2nd ed.). New York, NY, USA: Cambridge University Press.
- Lee, P. H. (2014). “Should We Adjust for a Confounder if Empirical and Theoretical Criteria Yield Contradictory Results? A Simulation Study”. Sci Rep. 4: 6085. Bibcode:2014NatSR...4E6085L. DOI:10.1038/srep06085. PMID 25124526.
- Shpitser, I. (2008). “Complete identification methods for the causal hierarchy”. The Journal of Machine Learning Research. 9: 1941—1979.
- Morabia, A (2011). “History of the modern epidemiological concept of confounding” (PDF). Journal of Epidemiology and Community Health. 65 (4): 297—300. DOI:10.1136/jech.2010.112565. PMID 20696848.
- Fisher, R. A. (1935). The design of experiments (pp. 114—145).
- Vandenbroucke, J. P. (2004). “The history of confounding”. Soz Praventivmed. 47 (4): 216—224. DOI:10.1007/BF01326402. PMID 12415925.
- Kish, L (1959). “Some statistical problems in research design”. Am Sociol. 26 (3): 328—338. DOI:10.2307/2089381.
- Greenland, S. (1986). “Identifiability, exchangeability, and epidemiological confounding”. International Journal of Epidemiology. 15 (3): 413—419. DOI:10.1093/ije/15.3.413. PMID 3771081.
- Neyman, J., with cooperation of K. Iwaskiewics and St. Kolodziejczyk (1935). Statistical problems in agricultural experimentation (with discussion). Suppl J Roy Statist Soc Ser B 2 107—180.
- Rubin, D. B. (1974). “Estimating causal effects of treatments in randomized and nonrandomized studies”. Journal of Educational Psychology. 66 (5): 688—701. DOI:10.1037/h0037350.
- Pearl, J., (2009). Causality: Models, Reasoning and Inference (2nd ed.). New York, NY, USA: Cambridge University Press.
- Johnston, S. C. (2001). “Identifying Confounding by Indication through Blinded Prospective Review”. American Journal of Epidemiology. 154 (3): 276—284. DOI:10.1093/aje/154.3.276. PMID 11479193.
- Pelham, Brett. Conducting Research in Psychology. — 2006. — ISBN 978-0-534-53294-9.
- Steg, L. Applied Social Psychology: Understanding and managing social problems / L. Steg, A. P. Buunk. — 2008.
- Tjønneland, Anne (January 1999). “Wine intake and diet in a random sample of 48763 Danish men and women”. The American Journal of Clinical Nutrition. 69 (1): 49—54. DOI:10.1093/ajcn/69.1.49. PMID 9925122.
- Axelson, O. (1989). “Confounding from smoking in occupational epidemiology”. British Journal of Industrial Medicine. 46 (8): 505—07. DOI:10.1136/oem.46.8.505. PMID 2673334.
- Mayrent, Sherry L. Epidemiology in Medicine. — Lippincott Williams & Wilkins, 1987. — ISBN 978-0-316-35636-7.
- Emanuel, Ezekiel J (Sep 20, 2001). “The Ethics of Placebo-Controlled Trials—A Middle Ground”. New England Journal of Medicine. 345 (12): 915—9. DOI:10.1056/nejm200109203451211. PMID 11565527.
Литература
- Pearl, J. (January 1998). “Why there is no statistical test for confounding, why many think there is, and why they are almost right” (PDF). UCLA Computer Science Department, Technical Report R-256.
- Montgomery, D. C. Design and Analysis of Experiments. — P. 287–302.