WAKE
WAKE (англ. Word Auto Key Encryption, шифрование слов на автоматическом ключе) — алгоритм поточного шифрования на автоматическом ключе, разработанный Дэвидом Уилером в 1993 году. Изначально проектировался как среднескоростная система шифрования (скорость в поточных шифрах измеряется в циклах на байт шифруемого открытого текста) блоков (минимального количества информации, которое может быть обработано алгоритмом; в данном случае блок составляет 32 бита), обладающая высокой безопасностью. По мнению автора, является простым алгоритмом быстрого шифрования, подходящим для обработки больших массивов данных, а также коротких сообщений, где изменяется только секретный ключ. Подходит для использования хешей на секретных ключах, используемых при верификации. Одним из примеров возможного практического использования данного алгоритма является шифрование потока текстовых данных в SMS. Из-за большого размера блоков не может быть использован в коммуникациях в режиме реального времени[1][2][3][4][5].
Свойства
Алгоритм работает в режиме CFB — предыдущее слово шифрованной последовательности служит основанием генерации следующего. Однако существуют модификации алгоритма, связанные с изменением процесса генерации ключа и позволяющие работать в режимах OFB и ROFB (Reverse OFB)[6]. В гамме шифра используются 32-битовые слова, а длина стартового ключа составляет 128 бит[1]. Также в алгоритме используется S-блок замены, состоящий из 256 32-битных слов. В работе используются четыре переменные, для лучшей производительности в этом качестве нужно использовать регистры. При работе полагается повторное использование таблиц в кэше и наличие большого пространства состояний. Это означает, что кэш данных должен без проблем вмещать таблицу из 256 слов[2].
Алгоритм является достаточно быстрым — на 32-битовых процессорах VLIW архитектуры оценочная производительность составляет 6.38 циклов на байт, что превышает аналогичный показатель алгоритма SEAL, но уступает RC4 (3.5 и 10.6 циклов на байт, соответственно)[3].
Шифр поддается криптоанализу, а именно атакам по подобранному открытому тексту и подобранному шифротексту[7].
Структура алгоритма
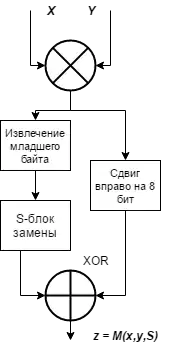 Функция смешения | 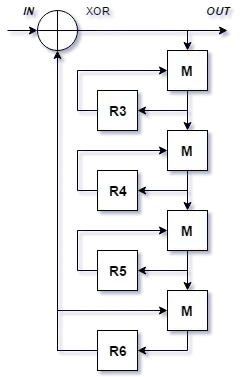 Блок-схема алгоритма WAKE в режиме CFB. — регистры |


Алгоритм строится на основе каскадного использования функции смешения ( — знак побитовой конъюнкции, — битовая операция исключающего «ИЛИ», битовый сдвиг является логическим)[7], которая при помощи -блока замены преобразует 32-битовые слова и , подаваемые на вход, в 32-битовое слово на выходе. Причем слова в -блоке составляются таким образом, что множество старших байтов этих слов представляет собой перестановку от 0 до 255 (первые байты каждого слова являются уникальными), тогда как оставшиеся 3 байта заполняются случайным образом[8]. Функция смешения сделана реверсивной из таких соображений, что знания одного из слов на входе и слова на выходе будет достаточно для восстановления второго неизвестного на входе[9].







WAKE состоит из четырёх каскадов функции с обратными связями по каждому и ещё одной на всю группу каскадов. Такое количество выбрано, как минимально возможное для полной диффузии данных в слове (то есть при изменении хотя бы одного бита ключа происходит полное изменение результата работы алгоритма шифрования), происходящей из-за того, что -блок осуществляет нелинейное преобразование, и использование побитового «И» и исключающего «ИЛИ» также вносит небольшую нелинейность[2].
Описание алгоритма
Процесс шифрования происходит в три этапа[1]:
- Процесс генерации S-блока;
- Процесс генерации автоключа;
- Непосредственно шифрование и расшифровывание.
Процесс генерации S-блока
В первую очередь происходит инициализация первых значений -блока (таблицы замены) секретным ключом. Даётся пример алгоритма заполнения данной таблицы[1]:
- Инициализировать вспомогательную таблицу , состоящую из 8 слов, имеющих между собой перестановку первых трех бит:
- Копировать ключ в первые 4 слова таким образом, что:
- , где — есть результат разбиения ключа на четыре равные части.
- Остальные слова образовать в цикле:
- Произвести суммирование:
- .
- Таким образом, даже первые несколько слов будут зависеть от всех бит .
- Определить вспомогательные переменные:
- Осуществить перестановку в первом байте слов таблицы:
- Инициализировать следующие переменные:
- Перемешать между собой слова в :































Метод построения может быть легко изменён, и вышеприведенный алгоритм является лишь примером. Главное, чтобы результат алгоритма обладал всеми свойствами, представленными из соображений криптографической стойкости -блока. Так, например, можно заполнить таблицу слов случайными числами, но в таком случае происходит утечка информации о повторяющихся и нулевых записях таблицы, не превышающая 1.5 бита на каждую запись. Тем не менее, создатель алгоритма утверждает, что процесс перестановки на старших байтах слов существенно помогает снизить утечку. А перестановка на всех четырёх байтах ещё больше нивелирует вероятность прочтения таблицы. Таким образом, алгоритм заполнения, приведенный выше, является компромиссом между безопасностью и скоростью, так как в нём осуществляется перестановка именно старших байт слов -блока[10].
Процесс генерации автоключа
Генерация производится согласно блок-схеме алгоритма[7]:
- Сначала необходимо инициализировать значения регистров ключом (возможно, другим):
- отвечают за то же разбиение ключа на равные части.
- Слова в ключевой последовательности вычисляются следующим образом:
- Очередное слово ключевой последовательности определяется значением крайнего регистра:









Ключ следует менять при наличии большого открытого текста (период изменения ключа составляет примерно 10000 слов — в таком случае замедление работы алгоритма составляет около 2-3 %)[11].
Шифрование и расшифровывание
Оба метода представляют собой гаммирование открытого текста (или шифротекста) с ключевой последовательностью. Шифрование и расшифровывание осуществляются по формуле[12]:
- , где — слово открытого текста или шифротекста в зависимости от того, осуществляется ли шифрование или расшифровывание.


Способы использования
Существует достаточно много способов использования данного шифра, однако автор формулирует только три основных метода[13]:
- Дополнение зашифрованных данных двумя словами на обоих концах и последующее заполнение всех бит этих слов одинаковыми случайными значениями. Таким образом, декодер сможет распознавать, когда необходимо использовать следующий ключ в ключевой последовательности для успешной расшифровки сообщения;
- Изменение стартового ключа для каждого нового блока данных;
- Шифрование последних четырёх слов открытого текста, дальнейшее гаммирование с помощью стартового ключа всей последовательности и осуществление того же самого в обратном порядке с помощью другого стартового ключа. Этот метод также может подразумевать использование какой-либо стандартной хеш-функции на секретном ключе, имеющей тот же стартовый ключ и таблицу замены для генерации хеша длиной в 128 бит. Этот хеш смешивается с первыми четырьмя словами открытого текста, собственно, в дальнейшем шифрование происходит тем же образом, как и ранее. Так, каждое новое сообщение образует новый результат на выходе алгоритма. Также в случае использования хеш-функции скорость выполнения повышается примерно в 5 раз в сравнении с обычным методом. Метод хорош тем, что хорошо подходит для коротких сообщений, где многократное вычисление таблицы замены заметно снижает эффективность применения. Так что использование одной и той же таблицы замены является оправданным шагом.
Пример работы
Пример работы данного алгоритма шифрования представлен следующим образом[1]:
- Инициализация стартового ключа :
- «legitosinarhusni».
- В шестнадцатеричной системе счисления он будет выглядеть так:
- Необходимо разбить ключ на четыре равные части и инициализировать стартовые значения регистров:
- Вычисление следующего слова ключевой последовательности (-блок уже сгенерирован на основе имеющегося стартового ключа):
-
-
-
-
- — новый ключ.
-
- Далее, пусть в роли открытого текста взят «ROBBI RAHIM». В HEX-представлении это будет . Необходимо произвести гаммирование данной числовой последовательности с ключом:
















| № | Символ открытого текста | Код ASCII | Процесс гаммирования | Результат ASCII | Выходной символ |
|---|---|---|---|---|---|
| 1 | R | 52 | 52 XOR C2 | 90 | • |
| 2 | O | 4F | 4F XOR 5D | 12 | _ (упр. символ) |
| 3 | B | 42 | 42 XOR 03 | 41 | A |
| 4 | B | 42 | 42 XOR 30 | 72 | r |
| 5 | I | 49 | 49 XOR C2 | 8B | ‹ |
| 6 | SPACE | 20 | 20 XOR 5D | 7D | } |
| 7 | R | 52 | 52 XOR 03 | 51 | Q |
| 8 | A | 41 | 41 XOR 30 | 71 | q |
| 9 | H | 48 | 48 XOR C2 | 8A | Š |
| 10 | I | 49 | 49 XOR 5D | 14 | _ (упр. символ) |
| 11 | M | 4D | 4D XOR 03 | 4E | N |
Итак, зашифрованной последовательностью слов является «•_Ar‹}QqŠ_N».
Криптоанализ
Алгоритм поточного шифрования поддается дешифрованию путём атак по подобранному открытому тексту и подобранному шифротексту[7]. В случае первого варианта атаки производится попытка восстановить таблицу замены, перебирая варианты открытого текста на входе, второй представляет собой подбор шифротекста для точного определения тех же неизвестных значений -блока. Известно, что вычислительная сложность атаки по подобранному открытому тексту составляет примерно или в зависимости от выбранной модификации атаки (в первом случае используется больше вариантов открытого текста). Вычислительная сложность атаки путем полного перебора составляет примерно , то есть относительная эффективность атаки по подобранному открытому тексту является очевидной[14]. Ещё одно преимущество атаки, предложенной в рассматриваемой статье[15], заключается в том, что она не зависит от смены ключа[16]. Тем не менее, алгоритмы, с помощью которых производится криптоанализ, становятся невыполнимы, если увеличить длину слова ( бит, где ). Таким образом, они могут быть значительно улучшены в перспективе[17][15].





Также, продолжительное изменение данных в каком-либо одном месте алгоритма шифрования в процессе работы может скомпрометировать таблицу замены. В случае, если -блок уже известен, то требуется всего 5 пар слов открытого-зашифрованного текста для того, чтобы точно определить значения регистров [11].
Примечания
- Legito, Robbi Rahim.
- Wheeler, 1993-12-09, p. 127.
- Craig, 1997-01-20, p. 276.
- Wheeler, 1993-12-09, p. 132.
- Hui-Mei Chao, p. 2.
- Craig, 1997-01-20, p. 279.
- Schneier, 1996, p. 336.
- Шамкин, 2006, p. 64.
- Craig, 1997-01-20, p. 278.
- Wheeler, 1993-12-09, p. 129.
- Wheeler, 1993-12-09, p. 130.
- Pudovkina, 2001-01-01, p. 2.
- Wheeler, 1993-12-09, p. 131.
- Pudovkina, 2001-01-01, p. 7.
- Pudovkina, 2001-01-01.
- Pudovkina, 2001-01-01, p. 2,7.
- Pudovkina, 2001-01-01, p. 1,7.
Литература
Книги
- Schneier, B. Applied Cryptography: Protocols, Algorthms, and Source Code in C. — 2nd edition. — John Wiley & Sons, Inc., 1996. — 784 с. — ISBN 0471128457.
- А.В. Яковлев, А.А. Безбогов, В.В. Родин, В.Н. Шамкин. Криптографическая защита информации : учебное пособие. — Тамбов: Изд-во Тамб. гос. техн. ун-та, 2006. — 140 с. — ISBN 5-8265-0503-6.
Статьи
- Wheeler, D. A bulk data encryption algorithm (англ.) // Fast Software Encryption. — Springer, Berlin, Heidelberg, 1993-12-09. — P. 127—134. — ISBN 3540581081. — doi:10.1007/3-540-58108-1_16.
- Craig S. K. Clapp. Optimizing a fast stream cipher for VLIW, SIMD, and superscalar processors (англ.) // Fast Software Encryption. — Springer, Berlin, Heidelberg, 1997-01-20. — P. 273—287. — doi:10.1007/bfb0052353.
- Legito, Robbi Rahim. SMS Encryption Using Word Auto Key Encryption | IJRTER (англ.). www.ijrter.com (2017). Дата обращения: 8 февраля 2017.
- Marina Pudovkina. Analysis of chosen plaintext attacks on the WAKE Stream Cipher. — 2001-01-01. — № 065.
- An Efficient Stream Cipher Using Variable Sizes of Key-Stream (англ.). ResearchGate. Дата обращения: 18 февраля 2017.