Information Protection and Control
Information Protection and Control (IPC) — технология защиты конфиденциальной информации от внутренних угроз. Решения класса IPC предназначены для защиты информации от внутренних угроз, предотвращения различных видов утечек информации, корпоративного шпионажа и бизнес-разведки. Термин IPC соединяет в себе две основные технологии: шифрование носителей информации на всех точках сети и контроль технических каналов утечки информации с помощью технологий Data Loss Prevention (DLP). Контроль доступа к сети, приложениям и данным является возможной третьей технологией в системах класса IPC. IPC включает в себя решения класса Data Loss Prevention (DLP), системы шифрования корпоративной информации и контроля доступа к ней. Термин IPC одним из первых использовал аналитик IDC Brian Burke в своём отчёте «Information Protection and Control Survey: Data Loss Prevention and Encryption Trends».

Идеология IPC
Технология IPC является логическим продолжением технологии DLP и позволяет защищать данные не только от утечек по техническим каналам, то есть инсайдеров, но и от несанкционированного доступа пользователей к сети, информации, приложениям и в тех случаях, когда непосредственный носитель информации попадает в руки третьих лиц. Это позволяет не допускать утечки и в тех случаях, когда инсайдер или не имеющий легального доступа к данным человек получает доступ к непосредственному носителю информации. Например, достав жесткий диск из персонального компьютера, инсайдер не сможет прочитать имеющуюся на нем информацию. Это позволяет не допустить компрометацию конфиденциальных данных даже в случае потери, кражи или изъятия (например, при организации оперативных мероприятий специалистами спецслужб, недобросовестными конкурентами или рейдерами).
Задачи IPC
Основной задачей IPC-систем является предотвращение передачи конфиденциальной информации за пределы корпоративной информационной системы. Такая передача (утечка) может быть намеренной или ненамеренной. Практика показывает, что большая часть (более 75 %) утечек происходит не по злому умыслу, а из-за ошибок, невнимательности, безалаберности, небрежности работников — выявлять подобные случаи намного проще. Остальная часть связана со злым умыслом операторов и пользователей информационных систем предприятия, в частности промышленным шпионажем, конкурентной разведкой. Очевидно, что злонамеренные инсайдеры, как правило, стараются обмануть анализаторы IPC и прочие системы контроля.
Дополнительные задачи систем класса IPC
- предотвращение передачи вовне не только конфиденциальной, но и другой нежелательной информации (обидных выражений, спама, эротики, излишних объёмов данных и т.п.);
- предотвращение передачи нежелательной информации не только изнутри наружу, но и снаружи внутрь информационной системы организации;
- предотвращение использования работниками Интернет-ресурсов и ресурсов сети в личных целях;
- защита от спама;
- защита от вирусов;
- оптимизация загрузки каналов, уменьшения нецелевого трафика;
- учет рабочего времени и присутствия на рабочем месте;
- отслеживание благонадёжности сотрудников, их политических взглядов, убеждений, сбор компромата;
- архивирование информации на случай случайного удаления или порчи оригинала;
- защита от случайного или намеренного нарушения внутренних нормативов;
- обеспечение соответствия стандартов в области информационной безопасности и действующего Законодательства.
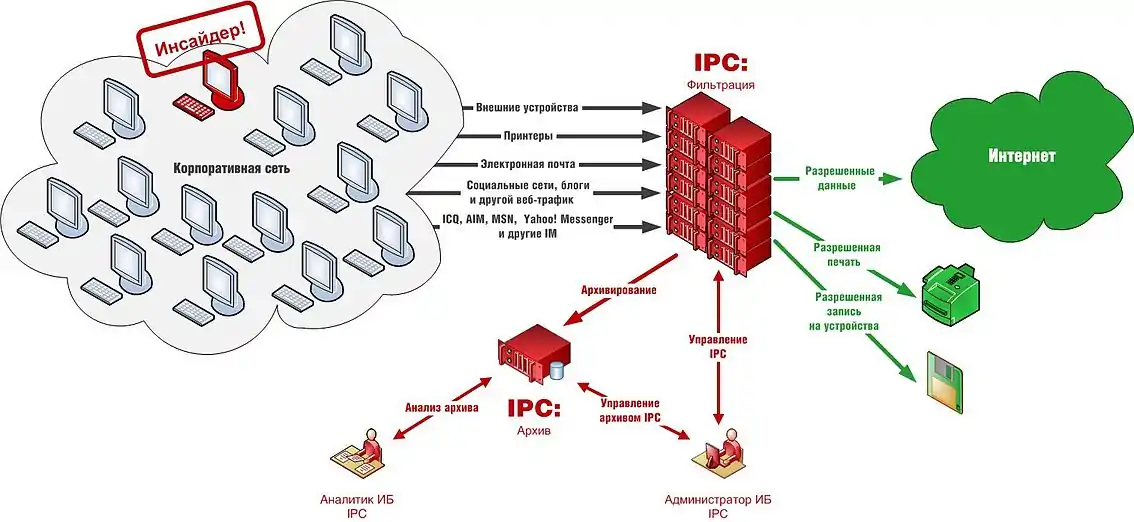
Контроль каналов утечки информации (Data Loss Prevention)
Технология DLP в IPC поддерживает контроль следующих технических каналов утечки конфиденциальной информации:
- корпоративная электронная почта,
- веб-почта,
- социальные сети и блоги,
- файлообменные сети,
- форумы и другие интернет-ресурсы, в том числе выполненные на AJAX-технологии,
- средства мгновенного обмена сообщениями (ICQ, Mail.Ru Агент, Skype, AOL AIM, Google Talk, Yahoo Messenger, MSN Messenger и прочее),
- p2p-клиенты,
- периферийные устройства (USB, LPT, COM, WiFi, Bluetooth и прочее),
- локальные и сетевые принтеры.
Технологии DLP в IPC поддерживают контроль в том числе следующих протоколов обмена данными:
Технологии детектирования конфиденциальной информации
Сигнатуры
Самый простой метод контроля — поиск в потоке данных некоторой последовательности символов. Иногда запрещенную последовательность символов называют «стоп-выражением», но в более общем случае она может быть представлена не словом, а произвольным набором символов, например, определенной меткой. Если система настроена только на одно слово, то результат её работы — определение 100%-го совпадения, т.е. метод можно отнести к детерминистским. Однако чаще поиск определенной последовательности символов все же применяют при анализе текста. В подавляющем большинстве случаев сигнатурные системы настроены на поиск нескольких слов и частоту встречаемости терминов.
К достоинствам этого метода можно отнести простоту пополнения словаря запрещенных терминов и очевидность принципа работы, а также то, что это самый верный способ, если необходимо найти соответствие слова или выражения на 100 %. Недостатки же становятся очевидными после начала промышленного использования такой технологии при отлове утечек и настройке правил фильтрации. Большинство производителей DLP-систем работают для Западных рынков, а английский язык очень «сигнатурен» — формы слов чаще всего образуются с помощью предлогов без изменения самого слова. В русском языке все гораздо сложнее, так как у нас есть приставки, окончания, суффиксы. Для примера можно взять слово «ключ», которое может означать как «ключ шифрования», «ключ от квартиры», «родник», «ключ или PIN-код от кредитной карты», так и множество других значений. В русском языке из корня «ключ» можно образовать несколько десятков различных слов. Это означает, что если на Западе специалисту по защите информации от инсайдеров достаточно ввести одно слово, в России специалисту придется вводить пару десятков слов и затем еще изменять их в шести различных кодировках. Реальное применение этого метода требует наличие лингвиста или команды лингвистов как на этапе внедрения, так и в процессе эксплуатации и обновления базы. Несомненным недостатком является и то, что «сигнатуры» неустойчивы к примитивному кодированию, например, заменой символов на похожие по начертанию.
«Цифровые отпечатки» (Digital Fingerprints или DG)
Различного типа хеш-функции образцов конфиденциальных документов позиционируются западными разработчиками DLP-систем как новое слово на рынке защиты от утечек, хотя сама технология существует с 70-х годов. На Западе этот метод иногда называется «digital fingerprints». Суть всех методов одна и та же, хотя конкретные алгоритмы у каждого производителя могут отличаться. Некоторые алгоритмы даже патентуются, что помогает в продвижении «новой патентованной технологии DG». Общий сценарий действия такой: набирается база образцов конфиденциальных документов. Суть работы DG довольно проста и часто этим и привлекает: DLP/IPC-системе передается некий стандартный документ-шаблон, из него создается цифровой отпечаток и записывается в базу данных DF. Далее в правилах контентной фильтрации настраивается процентное соответствие шаблону из базы. Например, если настроить 75 % соответствие «цифровому отпечатку» договору поставки, то при контентной фильтрации DLP обнаружит практически все договоры этой формы. Иногда, к этой технологии относят и системы вроде «Антиплагиата», однако последняя работает только с текстовой информацией, в то время как технология «цифровых отпечатков», в зависимости от реализации, может работать и различным медийным контентом и применяться для защиты авторских прав и препятствию случайному или намеренному нарушению законов и нормативов информационной безопасности.
К достоинствам технологии «цифровых отпечатков» (Digital Fingerprints) можно отнести простоту добавления новых шаблонов, довольно высокую степень детектирования и прозрачность алгоритма технологии для сотрудников подразделений по защите информации. Специалистам СБ и ИБ не надо думать о «стоп-выражениях» и прочей лингвистике, тратить много времени на анализ потенциально опасных словоформ и вбивать их в базу, тратить ресурсы на внедрение и поддержку лингвистической базы. Основным недостатком, который на первый взгляд неочевиден и скрыт за «патентованными технологиями», является то, что, несмотря на всю простоту и фактическое отсутствие лингвистических методов, необходимо постоянно обновлять базу данных «цифровых отпечатков». И если в случае с «сигнатурами», такой метод не требует постоянного обновления базы словами, то он требует обновления базы «цифровых отпечатков». К недостаткам «цифровых отпечатков» можно отнести то, что фактически от «дополнения базы словами» поддержка DLP в эффективном состоянии переходит «поиск и индексирование новых и измененных файлов», что является более сложной задачей, даже если это делается DLP-системой полуавтоматически. Крупные компании, в которых появляется до десятка тысяч новых и обновленных документов каждый рабочий день только на серверных хранилищах зачастую просто не в состоянии отслеживать всё это в режиме реального времени, не говоря уже об персональных компьютерах. В таком случае применение DG малоэффективно, поэтому «цифровые отпечатки» в большинстве DLP рассчитаны на компании SMB-сектора (менее 500 пользователей). В дополнение к этому цифровые отпечатки занимают примерно 10—15 % от размера конфиденциальных документов, и база постоянно разрастается, что требует дополнительных инвестиций в увеличение систем хранения информации и производительность DLP-серверов. Кроме того, низкоуровневые хеш-функции (в том числе и DG) неустойчивы к примитивному кодированию, которое рассматривалось применительно к «сигнатурам».
«Метки»
Суть этого метода заключается в расстановке специальных «меток» внутри файлов, содержащих конфиденциальную информацию. С одной стороны, такой метод дает стабильные и максимально точные сведения для DLP-системы, с другой стороны требуется много довольно сильных изменений в инфраструктуре сети. У лидеров DLP- и IPC-рынка реализация данного метода не встречается, поэтому рассматривать её подробно не имеет особого смысла. Можно лишь заметить, что, несмотря на явное достоинство «меток» — качество детектирования, есть множество существенных недостатков: от необходимости значительной перестройки инфраструктуры внутри сети до введения множества новых правил и форматов файлов для пользователей. Фактически внедрение такой технологии превращается во внедрение упрощенной системы документооборота.
Регулярные выражения
Поиск по регулярным выражениям («маскам) является также давно известным способом детектирования необходимого содержимого, однако в DLP стал применяться относительно недавно. Часто этот метод называют «текстовыми идентификаторами». Регулярные выражения позволяют находить совпадения по форме данных, в нем нельзя точно указать точное значение данных, в отличие от «сигнатур». Такой метод детектирования эффективен для поиска:
- ИНН,
- КПП,
- номеров счетов,
- номеров кредитных карт,
- номеров телефонов,
- номеров паспортов,
- клиентских номеров.
Поиск по «маскам» позволяет DLP- или IPC-системе обеспечивать соответствие требованиям все более популярного стандарта PCI DSS, разработанного международными платежными системами Visa и MasterCard для финансовых организаций.
К достоинствам технологии регулярных выражений в первую очередь стоит отнести то, что они позволяют детектировать специфичный для каждой организации тип контента, начиная от кредитных карт и заканчивая названиям схем оборудования, специфичных для каждой компании. Кроме того, формы основных конфиденциальных данных меняются крайне редко, поэтому их поддержка практически не будет требовать временных ресурсов. К недостаткам регулярных выражений можно отнести их ограниченную сферу применения в рамках DLP- и IPC-систем, так как найти с помощью них можно только конфиденциальную информацию лишь определенной формы. Регулярные выражения не могут применяться независимо от других технологий, однако могут эффективно дополнять их возможности.
Лингвистические методы (морфология, стемминг)
Самым распространенным на сегодняшний день методом анализа в DLP/IPC-системах является лингвистический анализ текста. Он настолько популярен, что часто именно он в просторечье именуется «контентной фильтрацией», то есть несет на себе характеристику всего класса методов анализа содержимого. Лингвистика как наука состоит из многих дисциплин — от морфологии до семантики, и лингвистические методы анализа различаются между собой. Есть технологии, использующие лишь «стоп-выражения», вводящиеся только на уровне корней, а сама система уже составляет полный словарь; есть базирующиеся на расставлении весов встречающихся в тексте терминов. Есть в лингвистических методах и свои отпечатки, базирующиеся на статистике; например, берется документ, считаются пятьдесят самых употребляемых слов, затем выбирается по 10 самых употребляемых из них в каждом абзаце. Такой «словарь» представляет собой практически уникальную характеристику текста и позволяет находить в «клонах» значащие цитаты. Разбор всех тонкостей лингвистического анализа не входит в рамки этой статьи, однако необходимо заметить ширину возможностей данной технологии в рамках IPC-систем.
К достоинствам лингвистических методов в DLP можно отнести то, что в морфологии и других лингвистических методах высокая степень эффективности, сравнимая с сигнатурами, при намного меньших трудозатратах на внедрение и поддержку (снижение трудозатрат на 95 % по отношению к «сигнатурам»). При этом в случае с использованием лингвистических методов детектирования нет необходимости отслеживать появление новых документов и направлять их на анализ в IPC-систему, так как эффективность лингвистических методов определения конфиденциальной информации не зависит от количества конфиденциальных документов, частоты их появления и производительности системы фильтрации содержимого. Недостатки лингвистических методов также довольно очевидны, первый из них — зависимость от языка — если организация представлена в нескольких странах, базы конфиденциальных слов и выражений придется создавать отдельно для каждого языка и страны, учитывая всю специфику. При этом обычная эффективность такого метода составит в среднем 85 %. Если привлекать профессиональных лингвистов, то эффективность может возрасти до 95 % — больше может обеспечить лишь ручная проверка или «сигнатуры», однако по отношению эффективности и трудозатрат равных лингвистическим методам пока не нашли.
Ручное детектирование («Карантин»)
Ручная проверка конфиденциальной информации иногда называется «Карантином». Любая информация, которая попадает под правила ручной проверки, например, в ней встречается слово «ключ», попадает в консоль специалиста информационной безопасности. Последний по очереди вручную просматривает такую информацию и принимает решение о пропуске, блокировке или задержке данных. Если данные блокируются или задерживаются, отправителю посылается соответствующее сообщение. Несомненным достоинством такого метода можно считать наибольшую эффективность. Однако, такой метод в реальном бизнесе применим лишь для ограниченного объема данных, так как требуется большого количества человеческих ресурсов, так как для качественного анализа всей информации, выходящий за пределы компании, количество сотрудников информационной безопасности должно примерно совпадать с количеством остальных офисных сотрудников. А это невозможно даже в силовых и военных структурах. Реальное применение для такого метода — анализ данных выбранных сотрудников, где требуется более тонкая работа, чем автоматический поиск по шаблонам, «цифровых отпечатков» или совпадений со словами из базы.
Архивирование информации, проходящей через технические каналы утечки
Обязательной компонентой IPC является архив, который ведется для выбранных потоков информации (пакетов, сообщений). Вся информация о действиях сотрудников хранится в одной и нескольких связанных базах данных. Лидирующие IPC-системы позволяют архивировать все каналы утечки, которые они могут контролировать. В архиве IPC хранятся копии закачанных в интернет документов и текста, электронных писем, распечатанных документов и файлов, записанных на периферийные устройства. В любой момент администратор ИБ может получить доступ к любому документу или тексту в архиве, используя лингвистический поиск информации по единому архиву (или всем распределенным архивам единовременно). Любое письмо при необходимости можно посмотреть или переслать, а любой закачанный в Интернет, записанный на внешнее устройство или распечатанный файл или документ просмотреть или скопировать. Это позволяет проводить ретроспективный анализ возможных утечек и, в ряде случаев, соответствовать регулирующим деятельность документам, например, Стандарту Банка России СТО БР ИББС-1.0-2008 (недоступная ссылка).
Шифрование информации на всех точках сети
Технология IPC включает в себя возможности по шифрованию информации на всех ключевых точках сети. Объектами защиты информации являются:
- Жесткие диски серверов,
- SAN,
- NAS,
- Магнитных лентах,
- Диски CD/DVD/Blue-ray,
- Персональные компьютеры (в том числе ноутбуки),
- Внешние устройства.
Технологии IPC используют различные подключаемые криптографические модули, в том числе наиболее эффективные алгоритмы DES, Triple DES, RC5, RC6, AES, XTS-AES. Наиболее используемыми алгоритмами в IPC-решениях являются RC5 и AES, эффективность которых можно проверить на проекте [distributed.net]. Они наиболее эффективны для решения задач шифрования данных больших объемов данных на серверных хранилищах и резервных копиях. В решениях IPC поддерживается интеграция с российским алгоритмом ГОСТ 28147-89, что позволяет применять модулей шифрования IPC в государственных организациях
Контроль доступа к сети, приложениям и информации
Двухфакторная аутентификация — это реализация контроля доступа, представляющая собой идентификацию пользователя на основе того, что он знает и того, чем он владеет. Наиболее распространенная форма аутентификации часто — это обычные пароли, которые пользователь держит у себя в памяти. Пароли создают слабую защиту, так как они могут быть легко раскрыты или разгаданы (один из самых распространенных паролей — «password»). Политика безопасности, основанная на одних паролях, делает организацию уязвимой, поэтому в IPC применяется двухфакторная аутентификация с использованием распространенных USB-токенов.
Информационная сеть современных организаций гетерогенна в большинстве случаев. Это означает, что в одной сети совместно существуют сервера под управлением разных операционных систем и большое количество прикладных программ. В зависимости от рода деятельности предприятия, это могут быть приложения электронной почты и групповой работы, CRM-, ERP-, Sharepoint-системы, системы электронного документооборота, финансового и бухгалтерского учета и так далее. Количество паролей, которые необходимо помнить обычному пользователю, может в среднем по организации достигать от 3 до 7. Пользователи пишут пароли на бумажках и приклеивают на видных местах, сводя тем самым на нет все усилия по защите информации, либо постоянно путают и забывают пароли, вызывая повышенную нагрузку на внутреннюю службу ИТ. Применение IPC в данном случае позволяет решить и вторичную задачу — упрощение жизни обычным сотрудникам совместно с повышением уровня защищенности.
Архитектура
IPC-системы обладают агентами на всех ключевых точках сети: сервера, хранилища, шлюзы, ПК (десктопы и ноутбуки), периферийные и сетевые пользовательские устройства. Технологии IPC реализованы для Windows, Linux, Sun Solaris, Novell. Поддерживается взаимодействие с Microsoft Active Directory, Novell eDirectory и другими LDAP. Большинство компонент может эффективно работать в рабочих группах.
См. также
Ссылки
- Публикации
- Статья в «Банковское обозрение»: Контролируйте конфиденциальные данные до того, как они попадут в чужие руки!
- Статья в BYTE/Россия: Как правильно внедрять DLP;
- Статья в BYTE/Россия: DLP для контроля почты, Александр Ковалев;
- Статья в «CIO: руководитель информационной службы»: Практика выбора IPC для защиты от внутренних угроз, Александр Ковалев;
- Статья на сайте Anti-Malware.ru: Сравнение систем защиты от утечек (DLP) - часть 1, Александр Панасенко, Илья Шабанов.
- Статья на сайте Bankir.ru: DLP для банков: особенности выбора, Вадим Станкевич.
- Нормативы ИБ
- Стандарт Банка России СТО БР ИББС-1.0-2014 (Россия, 2014). Рекомендации в области стандартизации ЦБ РФ
- PCI DSS — стандарт защиты информации в индустрии платежных карт, созданный сообществом PCI Security Standards Council.
- ФСФР — Кодекс корпоративного управления ФСФР (Россия).
- Basel II (Евросоюз).
- Закон SOX (США, Sarbanes-Oxley Act of 2002).
- Соглашение International Convergence of Capital Measurement and Capital Standards, Basel Committee on Banking Supervision.
- Директива Евросоюза о сохранении данных Data Retention Directive.
- Правило 17а-4 Комиссии по ценным бумагам США.
- HIPAA (Health Insurance Portability and Accountability Act of 1996, США).
- GLBA (США).
- Combined Code on Corporate Governance (Англия).
- Законодательство
- Техническая защита информации.
- Федеральный закон от 12 августа 1995 г. № 144-ФЗ «Об оперативно-розыскной деятельности»;
- ФЗ «Об архивном деле в Российской Федерации»;
- Федеральный закон Российской Федерации от 27 июля 2006 г. № 152-ФЗ «О персональных данных»;
- Постановление правительства № 687 от 15.09.2008
- Постановление правительства № 781 от 17.11.2007
- Приказ «Трёх». Приказ ФСТЭК России, ФСБ России и Мининформсвязи от 13.02.2008 № 55/86/20.
