Код Боуза — Чоудхури — Хоквингема
Коды Бозе — Чёдхури — Хокуингхема (БЧХ-коды) — в теории кодирования это широкий класс циклических кодов, применяемых для защиты информации от ошибок (см. Обнаружение и исправление ошибок). Отличается возможностью построения кода с заранее определёнными корректирующими свойствами, а именно, минимальным кодовым расстоянием. Частным случаем БЧХ-кодов является код Рида — Соломона.
Формальное описание
БЧХ-код является циклическим кодом, который можно задать порождающим полиномом. Для его нахождения в случае БЧХ-кода необходимо заранее определить длину кода (она не может быть произвольной) и требуемое минимальное расстояние . Найти порождающий полином можно следующим образом.


Пусть — примитивный элемент поля (то есть ), пусть , — элемент поля порядка , . Тогда нормированный полином минимальной степени над полем , корнями которого являются подряд идущих степеней элемента для некоторого целого (в том числе 0 и 1), является порождающим полиномом БЧХ-кода над полем с длиной и минимальный расстоянием .












Поясним, почему у получившегося кода будут именно такие характеристики (длина кода , минимальное расстояние ). Действительно, как показано у Сагаловича[1], длина БЧХ-кода равна порядку элемента , если , и равна порядку элемента , если . Так как случай нам не интересен (такой код не может исправлять ошибки, только обнаруживать), то длина кода будет равна порядку элемента , то есть равна . Минимальное расстояние может быть больше , когда корнями минимальных функций[2] от элементов будут элементы, расширяющие последовательность, то есть элементы .






Число проверочных символов равно степени , число информационных символов , величина называется конструктивным расстоянием БЧХ-кода. Если , то код называется примитивным, иначе — непримитивным.



Так же, как и для циклического кода, кодовый полином может быть получен из информационного полинома степени не больше , путём перемножения и :




Построение
Для нахождения порождающего полинома необходимо выполнить несколько этапов[3]:
- выбрать , то есть поле , над которым будет построен код;
- выбрать длину кода из условия , где — целые положительные числа;
- задать величину конструктивного расстояния;
- построить циклотомические классы элемента поля над полем , где — примитивный элемент ;
- поскольку каждому такому циклотомическому классу соответствует неприводимый полином над , корнями которого являются элементы этого и только этого класса, со степенью равной количеству элементов в классе, то выбрать таким образом, чтобы суммарная длина циклотомических классов была минимальна; это делается для того, чтобы при заданных характеристиках кода и минимизировать количество проверочных символов ;
- вычислить порождающий полином , где — полином, соответствующий -му циклотомическому классу; или вычислить , как НОК минимальных функций от элементов .







Примеры кодов
Примитивный двоичный (15, 7, 5) код
Пусть , требуемая длина кода , и минимальное расстояние . Возьмем — примитивный элемент поля , и — четыре подряд идущих степеней элемента . Они принадлежат двум циклотомическим классам над полем , которым соответствуют неприводимые полиномы и . Тогда полином









имеет в качестве корней элементы и является порождающим полиномом БЧХ-кода с параметрами .

16-ричный (15, 11, 5) код (код Рида — Соломона)
Пусть , и — примитивный элемент . Тогда


Каждый элемент поля можно сопоставить 4 битам, поэтому одно кодовое слово эквивалентно 60 = 15 × 4 битам, таким образом набору из 44 битов ставится в соответствие набор из 60 битов. Можно сказать, что такой код работает с полубайтами информации.
Кодирование
Для кодирования кодами БЧХ применяются те же методы, что и для кодирования циклическими кодами.
Методы декодирования
Коды БЧХ являются циклическими кодами, поэтому к ним применимы все методы, используемые для декодирования циклических кодов. Однако существуют гораздо лучшие алгоритмы, разработанные именно для БЧХ-кодов[4].
Главной идеей в декодировании БЧХ-кодов является использование элементов конечного поля для нумерации позиций кодового слова (или, эквивалентно, в порядке коэффициентов ассоциированного многочлена). Ниже приведена такая нумерация для вектора , соответствующего многочлену .


значения локаторы позиций






Пусть принятое слово ассоциировано с полиномом , где многочлен ошибок определён как: , где — число ошибок в принятом слове. Множества и называют значениями ошибок и локаторами ошибок соответственно, где , и .







Синдромы определены как значения принятого полинома в нулях порождающего многочлена кода:




где .

Для нахождения множества локаторов ошибок введём в рассмотрение многочлен локаторов ошибок

корни которого равны обратным величинам локаторов ошибок. Тогда справедливо следующее соотношение между коэффициентами многочлена локаторов ошибок и синдромами[5]:



Известны следующие методы для решения этой системы уравнений относительно коэффициентов многочлена локаторов ошибок (ключевая система уравнений).

- Алгоритм Берлекемпа — Мэсси (BMA). По числу операций в конечном поле этот алгоритм обладает высокой эффективностью. BMA обычно используется для программной реализации или моделирования кодов БЧХ и кодов Рида — Соломона.
- Евклидов алгоритм (ЕА). Из-за высокой регулярности структуры этого алгоритма его широко используют для аппаратной реализации декодеров БЧХ и кодов Рида — Соломона.
- Прямое решение (алгоритм Питерсона — Горенстейна — Цирлера, ПГЦ). Исторически это первый метод декодирования, найденный Питерсоном для двоичного случая (), затем Горенстейном и Цирлером для общего случая. Этот алгоритм находит коэффициенты многочлена локаторов ошибок прямым решением соответствующей системы линейных уравнений. В действительности, так как сложность этого алгоритма растет как куб минимального расстояния , прямой алгоритм может быть использован только для малых значений , однако именно этот алгоритм лучше всего проясняет алгебраическую идею процесса декодирования.
Алгоритм Берлекемпа — Мэсси
Этот алгоритм лучше всего рассматривать как итеративный процесс построения минимального регистра (сдвига) с обратной связью, генерирующего известную последовательность синдромов . Его фактическая цель — построить полином наименьшей степени, удовлетворяющему уравнению



Решение этого уравнения эквивалентно условию

Итеративный процесс построения такого многочлена и есть Алгоритм Берлекемпа — Мэсси.
Евклидов алгоритм
В основе этого метода лежит широко известный алгоритм Евклида по нахождению наибольшего общего делителя двух чисел (НОД), только в данном случае ищем НОД не двух чисел, а двух полиномов. Обозначим полином значений ошибок как , где синдромный полином равен . Из системы уравнений следует, что . Задача по сути сводится к тому чтобы определить , удовлетворяющий последнему уравнению и при этом степени не выше . По сути такое решение и будет давать расширенный алгоритм Евклида, примененный к многочленам и , где . Если на -м шаге расширенный алгоритм Евклида выдает решение , такое что , то , и . При этом найденный полином дальше не принимает участия в декодировании (он ищется только как вспомогательный). Таким образом будет найден полином локаторов ошибок .















Прямое решение (алгоритм Питерсона — Горенстейна — Цирлера, ПГЦ)
Пусть БЧХ-код над полем длины и с конструктивным расстоянием задаётся порождающим полиномом , который имеет среди своих корней элементы — целое число (например, 0 или 1). Тогда каждое кодовое слово обладает тем свойством, что . Принятое слово можно записать как , где — полином ошибок. Пусть произошло ошибок на позициях ( — максимальное число исправляемых ошибок), значит , а — величины ошибок.









Можно составить -й синдром принятого слова :


Задача состоит в нахождении числа ошибок , их позиций и их значений при известных синдромах .

Предположим для начала, что в точности равно . Запишем синдромы в виде системы нелинейных уравнений в явном виде:

Обозначим через локатор -й ошибки, а через — величину ошибки, . При этом все различны, так как порядок элемента равен , и поэтому при известном можно определить как .







Составим полином локаторов ошибок:

Корнями этого полинома являются элементы, обратные локаторам ошибок. Помножим обе части этого полинома на . Полученное равенство будет справедливо для :



Если подставить сюда , то получится равенство, справедливое для каждого и при всех :




Таким образом для каждого можно записать своё равенство. Если их просуммировать по , то получится равенство, справедливое для каждого :


Поскольку (то есть, меняется в тех же пределах, что и ранее), система уравнений для синдромов преобразуется в систему линейных уравнений:



или, в матричной форме,

где

Если число ошибок и в самом деле равно , то эта система разрешима, и можно найти значения коэффициентов . Если же число , то определитель матрицы будет равен . Это есть признак того, что количество ошибок меньше . Поэтому необходимо составить систему, предполагая число ошибок равным , вычислить определитель новой матрицы и т. д. до тех пор, пока не установим истинное число ошибок.






Поиск Ченя
После того как ключевая система уравнений решена, получаются коэффициенты полинома локаторов ошибок. Его корни (элементы, обратные локаторам ошибок) можно найти простым перебором по всем элементам поля . К ним найти элементы, обратные по умножению, — это локаторы ошибок . Этот процесс легко реализовать аппаратно.

Алгоритм Форни
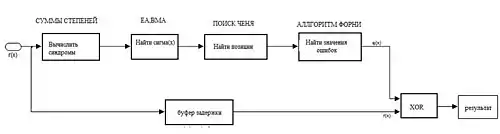
По локаторам можно найти позиции ошибок (), а значения ошибок из системы для синдромов, приняв . Декодирование завершено.


См. также
Примечания
- Сагалович, 2007, с. 175—176.
- Сагалович, 2007, с. 176.
- Сагалович, 2007, с. 168.
- Искусство помехоустойчивого кодирования, с. 91.
- Сагалович, 2007, с. 200.
Литература
- Блейхут Р. Теория и практика кодов, контролирующих ошибки = Theory and Practice of Error Control Codes. — М.: Мир, 1986. — 576 с.
- Питерсон У., Уэлдон Э. Коды, исправляющие ошибки. — М.: Мир, 1976. — С. 596.
- Сагалович Ю. Л. Введение в алгебраические коды — М.: МФТИ, 2007. — 262 с. — ISBN 978-5-7417-0191-1
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. — М.: Техносфера, 2005. — 320 с. — ISBN 5-94836-035-0.