Двоичный поиск
Двоичный (бинарный) поиск (также известен как метод деления пополам или дихотомия) — классический алгоритм поиска элемента в отсортированном массиве (векторе), использующий дробление массива на половины. Используется в информатике, вычислительной математике и математическом программировании.
Частным случаем двоичного поиска является метод бисекции, который применяется для поиска корней заданной непрерывной функции на заданном отрезке.
Поиск элемента в отсортированном массиве
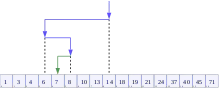
- Определение значения элемента в середине структуры данных. Полученное значение сравнивается с ключом.
- Если ключ меньше значения середины, то поиск осуществляется в первой половине элементов, иначе — во второй.
- Поиск сводится к тому, что вновь определяется значение серединного элемента в выбранной половине и сравнивается с ключом.
- Процесс продолжается до тех пор, пока не будет найден элемент со значением ключа или не станет пустым интервал для поиска.
Несмотря на то, что код достаточно прост, в нём есть несколько ловушек.
- Что будет, если
firstиlastпо отдельности умещаются в свой тип, аfirst+last— нет?[1] Если теоретически возможны массивы столь большого размера, приходится идти на ухищрения:- Использовать код
first + (last - first) / 2, который точно не приведёт к переполнениям (то и другое — неотрицательные целые числа).- Если
firstиlast— указатели или итераторы, такой код единственно правильный. Преобразование вuintptr_tи дальнейший расчёт в этом типе нарушает абстракцию, и нет гарантии, что результат останется корректным указателем. Разумеется, чтобы сохранялась сложность алгоритма, нужны быстрые операции «итератор+число → итератор», «итератор−итератор → число».
- Если
- Если
firstиlast— типы со знаком, провести расчёт в беззнаковом типе:((unsigned)first + (unsigned)last) / 2. В Java соответственно[уточнить]:(first + last) >>> 1. - Написать расчёт на ассемблере, с использованием флага переноса. Что-то наподобие
add eax, b; rcr eax, 1. А вот длинные типы использовать нецелесообразно,first + (last - first) / 2быстрее.
- Использовать код
- В двоичном поиске часты ошибки на единицу. Поэтому важно протестировать такие случаи: пустой массив (
n=0), ищем отсутствующее значение (слишком большое, слишком маленькое и где-то в середине), ищем первый и последний элемент. Не выходит ли алгоритм за границы массива? Не зацикливается ли? - Иногда требуется, чтобы, если
xв цепочке существует в нескольких экземплярах, находило не любой, а обязательно первый (как вариант: последний; либо вообще неx, а следующий за ним элемент).[2] Код на Си в такой ситуации находит первый из равных, более простой код на Си++ — какой попало.
Учёный Йон Бентли утверждает, что 90 % студентов, разрабатывая двоичный поиск, забывают учесть какое-либо из этих требований. И даже в код, написанный самим Йоном и ходивший из книги в книгу, вкралась ошибка: код не стоек к переполнениям[1].
Приложения
Практические приложения метода двоичного поиска разнообразны:
- Широкое распространение в информатике применительно к поиску в структурах данных. Например, поиск в массивах данных осуществляется по ключу, присвоенному каждому из элементов массива (в простейшем случае сам элемент является ключом).
- Также его применяют в качестве численного метода для нахождения приближённого решения уравнений (см. Метод бисекции).
- Метод используется для нахождения экстремума целевой функции и в этом случае является методом условной одномерной оптимизации. Когда функция имеет вещественный аргумент, найти решение с точностью до можно за время . Когда аргумент дискретен, и изначально лежит на отрезке длины N, поиск решения займёт времени. Наконец, для поиска экстремума, скажем, для определённости минимума, на очередном шаге отбрасывается тот из концов рассматриваемого отрезка, значение в котором максимально.



См. также
Примечания
- Extra, Extra — Read All About It: Nearly All Binary Searches and Mergesorts are Broken // Joshua Bloch, Google Research; перевод — Почти во всех реализациях двоичного поиска и сортировки слиянием есть ошибка
- В C++
std::lower_boundнаходит первое вхождениеx, аstd::upper_bound— элемент, следующий заx.
Литература
- Левитин А. В. Глава 4. Метод декомпозиции: Бинарный поиск // Алгоритмы. Введение в разработку и анализ — М.: Вильямс, 2006. — С. 180—183. — 576 с. — ISBN 978-5-8459-0987-9
- Амосов А. А., Дубинский Ю. А., Копченова Н. П. Вычислительные методы для инженеров. — М.: Мир, 1998.
- Бахвалов Н. С., Жидков Н. П., Кобельков Г. Г. Численные методы. — 8-е изд. — М.: Лаборатория Базовых Знаний, 2000.
- Вирт Н. Алгоритмы + структуры данных = программы. — М.: «Мир», 1985. — С. 28.
- Волков Е. А. Численные методы. — М.: Физматлит, 2003.
- Гилл Ф., Мюррей У., Райт М. Практическая оптимизация. Пер. с англ. — М.: Мир, 1985.
- Кормен, Т., Лейзерсон, Ч., Ривест, Р., Штайн, К. Алгоритмы: построение и анализ = Introduction to Algorithms / Под ред. И. В. Красикова. — 2-е изд. — М.: Вильямс, 2005. — 1296 с. — ISBN 5-8459-0857-4.
- Корн Г., Корн Т. Справочник по математике для научных работников и инженеров. — М.: Наука, 1970. — С. 575-576.
- Коршунов Ю. М., Коршунов Ю. М. Математические основы кибернетики. — Энергоатомиздат, 1972.
- Максимов Ю. А., Филлиповская Е. А. Алгоритмы решения задач нелинейного программирования. — М.: МИФИ, 1982.
- Роберт Седжвик. Фундаментальные алгоритмы на C. Анализ/Структуры данных/Сортировка/Поиск = Algorithms in C. Fundamentals/Data Structures/Sorting/Searching. — СПб.: ДиаСофтЮП, 2003. — С. 672. — ISBN 5-93772-081-4.
