Глубокая сеть
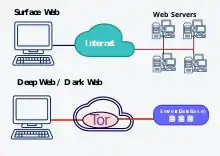
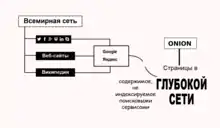
Глубокая сеть (также известна как «Невидимая сеть», «Глубокая паутина», «Глубокий интернет»; англ. deep web;) — множество веб-страниц Всемирной паутины, не индексируемых поисковыми системами.
Термин произошёл от соотв. англ. invisible web[1]. Наиболее значительной частью глубокой паутины является Глубинный веб (от англ. deep web, hidden web), состоящий из веб-страниц, динамически генерируемых по запросам к онлайн-базам данных[2].
Не следует смешивать понятие Глубокая паутина с понятием Тёмная паутина (от англ. dark web), под которым имеются в виду сетевые сегменты, хотя и подключённые к общей сети Интернет, но требующие для доступа определённые программные средства.
Суть проблемы
В глубокой паутине находятся веб-страницы, не связанные с другими гиперссылками (например, тупиковые веб-страницы, динамически создаваемые скриптами на самих сайтах, по запросу, на которые не ведут прямые ссылки), а также сайты, доступ к которым открыт только для зарегистрированных пользователей и интернет-страницы, доступные только по паролю.
Поисковые системы используют специальных поисковых роботов, которые переходят по гиперссылкам и индексируют содержимое веб-страниц, на которых они оказываются, занося их содержимое и гиперссылки на них в свои базы данных. Найдя на проиндексированной веб-странице ссылки на другие страницы, поисковый бот переходит по ним и индексирует содержимое каждой из найденных страниц, находит новые гиперссылки и переходит по ним для индексации; в результате переходов по ссылкам, ведущим за пределы индексируемых страниц, количество проиндексированных веб-страниц постоянно увеличивается. Попасть на веб-страницы, на которые нет ссылок с других страниц, поисковый бот не может, в силу чего содержимое этих страниц не индексируется. Как следствие, не зная URL сайта или веб-страницы «Глубокой сети», обычный пользователь попасть на них не сможет.
Также в «Глубокую сеть» попадают сайты, владельцы которых добровольно отказались от индексации поисковыми системами (например, с помощью файла «robots.txt»), а также сайты и веб-страницы, защищённые авторизацией от просмотра информации третьими лицами. В таком случае, не зная логин и (или) пароль к веб-странице, невозможно в полной мере просмотреть её содержимое или пользоваться веб-сайтом.
Масштаб
Размер глубокой паутины неизвестен. Существуют относительно достоверные оценки общего числа сайтов, ведущих к онлайн-базам данных: около 300 тысяч таких сайтов во всём Вебе в 2004 году и около 14 тысяч в Рунете в 2006 году[3][4].
Поиск по глубокой паутине
В 2005 году компания «Yahoo!» сделала серьёзный шаг к решению этой проблемы. Компания выпустила поисковый движок «Yahoo! Subscriptions», который производит поиск по сайтам (пока немногочисленным), доступ к которым открыт только зарегистрированным участникам этих сайтов. Это, однако, полностью не решило имеющейся проблемы. Эксперты поисковых систем по-прежнему пытаются найти технические возможности для индексации содержимого баз данных и доступа к закрытым веб-сайтам.
Одним из популярных сервисов, работающих с данными глубокой паутины, является UFOseek, изначально предназначенный для систематизации данных о паранормальных явлениях[5].
Виды содержимого
Хоть и не всегда возможно напрямую найти контент определенного веб-сервера, чтобы он мог быть проиндексирован, всё же можно получить доступ к такому сайту (из-за компьютерных уязвимостей).
Чтобы обнаружить контент в Интернете, поисковые системы используют веб-сканеры, которые следуют за гиперссылками через известные номера виртуальных портов протокола. Этот метод идеально подходит для обнаружения контента во всемирной сети, но зачастую неэффективен при поиске контента глубокой сети. Например, поисковые роботы не ищут динамические страницы, которые являются результатом запросов к базе данных из-за неопределенного количества этих самых запросов. Было отмечено, что это может быть (частично) преодолено путем предоставления ссылок на результаты запроса, но это может непреднамеренно раздуть популярность для члена глубокой сети.
Существует несколько поисковых систем, которые получили доступ к глубокой сети. У Intute прекратилось финансирование и теперь он является временным архивом по состоянию на июль 2011 года. Scirus закрылся в конце января 2013 года.
Исследователи изучали, как можно автоматически сканировать глубокую паутину, включая контент, доступ к которому можно получить только с помощью специального программного обеспечения, такого как Tor. В 2001 году Шрирам Рагхаван и Гектор Гарсия-Молина (Stanford Computer Science Department, Стэнфордский университет) представили архитектурную модель скрытой поисковой системы, которая использовала ключевые слова, предоставленные пользователями или собранные из интерфейсов запросов, для запроса и сканирования глубокого интернета.
Коммерческие поисковые системы начали изучать альтернативные методы для сканирования глубокого интернета. Протокол Sitemap (впервые разработанный и внедренный Google в 2005 году) и mod_oai — это механизмы, которые позволяют поисковым системам и другим заинтересованным сторонам обнаруживать ресурсы глубокого интернета на определенных веб-серверах. Оба механизма позволяют веб-серверам размещать на них доступные URL-адреса, что позволяет автоматически обнаруживать ресурсы, которые напрямую не связаны со всемирной сетью. Система навигации по глубокому интернету от Google вычисляет представления для каждой HTML-формы и добавляет полученные HTML-страницы в индекс поисковой системы Google. Полученные результаты учитывают тысячу запросов в секунду для глубокого веб-контента. В этой системе предварительное вычисление представлений выполняется с использованием трех алгоритмов:
- выбор входных значений для текстового поиска, которые принимают ключевые слова;
- определённые входные данные, которые принимают только значения определенного типа (например, даты);
- выбор небольшого количества комбинаций ввода, которые генерируют URL-адреса, подходящие для включения в индекс поиска в Интернете.
См. также
Примечания
- Gary Price, Chris Sherman. The Invisible Web: Uncovering Information Sources Search Engines Can’t See. — CyberAge Books, 2001, ISBN 0-910965-51-X.
- Денис Шестаков, Наталья Воронцова (2005). «Структура русскоязычной части глубинного Веба (недоступная ссылка)». Интернет-математика 2005, стр.320-341.
- Denis Shestakov (2011). «Sampling the National Deep Web (недоступная ссылка)». Proceedings of the 22nd International Conference on Database and Expert Systems Applications (DEXA), стр. 331-340.
- How big is the internet?.
- Игорь Райхман, 2013, с. 118.
Литература
- Игорь Райхман. Практика медиа измерений. Аудит. Отчётность. Оценка эффективности PR. — М.: Альпина Паблишер, 2013. — 432 с. — ISBN 978-5-9614-4499-5.