Большие данные
Больши́е да́нные (англ. big data, [ˈbɪɡ ˈdeɪtə]) — обозначение структурированных и неструктурированных данных огромных объёмов и значительного многообразия, эффективно обрабатываемых горизонтально масштабируемыми программными инструментами, появившимися в конце 2000-х годов и альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence[1][2][3].
В широком смысле о «больших данных» говорят как о социально-экономическом феномене, связанном с появлением технологических возможностей анализировать огромные массивы данных, в некоторых проблемных областях — весь мировой объём данных, и вытекающих из этого трансформационных последствий[4].
В качестве определяющих характеристик для больших данных традиционно выделяют «три V»: объём (англ. volume, в смысле величины физического объёма), скорость (velocity в смыслах как скорости прироста, так и необходимости высокоскоростной обработки и получения результатов), многообразие (variety, в смысле возможности одновременной обработки различных типов структурированных и полуструктурированных данных)[5][6]; в дальнейшем возникли различные вариации и интерпретации этого признака.
С точки зрения информационных технологий, в совокупность подходов и инструментов изначально включались средства массово-параллельной обработки неопределённо структурированных данных, прежде всего, системами управления базами данных категории NoSQL, алгоритмами MapReduce и реализующими их программными каркасами и библиотеками проекта Hadoop[7]. В дальнейшем к серии технологий больших данных стали относить разнообразные информационно-технологические решения, в той или иной степени обеспечивающие сходные по характеристикам возможности по обработке сверхбольших массивов данных.
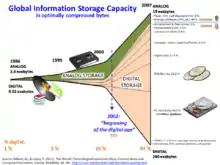
— 2002 год явился переломным в изменении соотношения мирового объёма аналоговых и цифровых данных в пользу последних, объём которых увеличивался в геометрической прогрессии (лавинообразно);
— к 2007 году объём цифровых данных превысил объём аналоговых почти в 15 раз, составив 280 эксабайт цифровых данных к 19 аналоговых.
История
Широкое введение термина «большие данные» связывают с Клиффордом Линчем, редактором журнала Nature, подготовившим к 3 сентября 2008 года специальный выпуск с темой «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объёмами данных?», в котором были собраны материалы о феномене взрывного роста объёмов и многообразия обрабатываемых данных и технологических перспективах в парадигме вероятного скачка «от количества к качеству»; термин был предложен по аналогии с расхожими в деловой англоязычной среде метафорами «большая нефть», «большая руда»[9][10].
Несмотря на то, что термин вводился в академической среде и прежде всего разбиралась проблема роста и многообразия научных данных, начиная с 2009 года термин широко распространился в деловой прессе, а к 2010 году относят появление первых продуктов и решений[обтекаемое выражение], относящихся исключительно и непосредственно к проблеме обработки больших данных. К 2011 году большинство крупнейших поставщиков информационных технологий для организаций в своих деловых стратегиях использует понятие о больших данных, в том числе IBM[11], Oracle[12], Microsoft[13], Hewlett-Packard[14], EMC[15], а основные аналитики рынка информационных технологий посвящают концепции выделенные исследования[5][16][17][18].
В 2011 году Gartner отметил большие данные как тренд номер два в информационно-технологической инфраструктуре (после виртуализации и как более существенный, чем энергосбережение и мониторинг)[19]. В это же время прогнозировалось, что внедрение технологий больших данных наибольшее влияние окажет на информационные технологии в производстве, здравоохранении, торговле, государственном управлении, а также в сферах и отраслях, где регистрируются индивидуальные перемещения ресурсов[20].
С 2013 года большие данные как академический предмет изучаются в появившихся вузовских программах по науке о данных[21] и вычислительным наукам и инженерии[22].
В 2015 году Gartner исключил большие данные из цикла зрелости новых технологий и прекратил выпускать выходивший в 2011—2014 годы отдельный цикл зрелости технологий больших данных, мотивировав это переходом от этапа шумихи к практическому применению. Технологии, фигурировавшие в выделенном цикле зрелости, по большей части перешли в специальные циклы по продвинутой аналитике и науке о данных, по BI и анализу данных, корпоративному управлению информацией, резидентным вычислениям, информационной инфраструктуре[23].
VVV
Набор признаков VVV (volume, velocity, variety) изначально выработан Meta Group в 2001 году вне контекста представлений о больших данных как об определённой серии информационно-технологических методов и инструментов, в нём, в связи с ростом популярности концепции центрального хранилища данных для организаций, отмечалась равнозначимость проблематик управления данными по всем трём аспектам[24]. В дальнейшем появились интерпретации с «четырьмя V» (добавлялась veracity — достоверность, использовалась в рекламных материалах IBM[25]), «пятью V» (в этом варианте прибавляли viability — жизнеспособность, и value — ценность[26]), и даже «семью V» (кроме всего, добавляли также variability — переменчивость, и visualization[27]). IDC интерпретирует «четвёртое V» как value c точки зрения важности экономической целесообразности обработки соответствующих объёмов в соответствующих условиях, что отражено также и в определении больших данных от IDC[28]. Во всех случаях в этих признаках подчёркивается, что определяющей характеристикой для больших данных является не только их физический объём, но другие категории, существенные для представления о сложности задачи обработки и анализа данных.
Источники
Классическими источниками больших данных признаются интернет вещей и социальные медиа, считается также, что большие данные могут происходить из внутренней информации предприятий и организаций (генерируемой в информационных средах, но ранее не сохранявшейся и не анализировавшейся), из сфер медицины и биоинформатики, из астрономических наблюдений[29].
В качестве примеров источников возникновения больших данных приводятся[30][31] непрерывно поступающие данные с измерительных устройств, события от радиочастотных идентификаторов, потоки сообщений из социальных сетей, метеорологические данные, данные дистанционного зондирования Земли, потоки данных о местонахождении абонентов сетей сотовой связи, устройств аудио- и видеорегистрации. Ожидается, что развитие и начало широкого использования этих источников инициирует проникновение технологий больших данных как в научно-исследовательскую деятельность, так и в коммерческий сектор и сферу государственного управления.
Методы анализа
Методы и техники анализа, применимые к большим данным, выделенные в отчёте McKinsey[32]:
- методы класса Data Mining: обучение ассоциативным правилам (англ. association rule learning), классификация (методы категоризации новых данных на основе принципов, ранее применённых к уже наличествующим данным), кластерный анализ, регрессионный анализ;
- краудсорсинг — категоризация и обогащение данных силами широкого, неопределённого круга лиц, привлечённых на основании публичной оферты, без вступления в трудовые отношения;
- смешение и интеграция данных (англ. data fusion and integration) — набор техник, позволяющих интегрировать разнородные данные из разнообразных источников для возможности глубинного анализа, в качестве примеров таких техник, составляющих этот класс методов приводятся цифровая обработка сигналов и обработка естественного языка (включая тональный анализ);
- машинное обучение, включая обучение с учителем и без учителя, а также Ensemble learning — использование моделей, построенных на базе статистического анализа или машинного обучения для получения комплексных прогнозов на основе базовых моделей (англ. constituent models, ср. со статистическим ансамблем в статистической механике);
- искусственные нейронные сети, сетевой анализ, оптимизация, в том числе генетические алгоритмы;
- распознавание образов;
- прогнозная аналитика;
- имитационное моделирование;
- пространственный анализ (англ. Spatial analysis) — класс методов, использующих топологическую, геометрическую и географическую информацию в данных;
- статистический анализ, в качестве примеров методов приводятся A/B-тестирование и анализ временных рядов;
- визуализация аналитических данных — представление информации в виде рисунков, диаграмм, с использованием интерактивных возможностей и анимации как для получения результатов, так и для использования в качестве исходных данных для дальнейшего анализа.
Технологии
Наиболее часто указывают в качестве базового принципа обработки больших данных горизонтальную масштабируемость, обеспечивающую обработку данных, распределённых на сотни и тысячи вычислительных узлов, без деградации производительности; в частности, этот принцип включён в определение больших данных от NIST[33]. При этом McKinsey, кроме рассматриваемых большинством аналитиков технологий NoSQL, MapReduce, Hadoop, R, включает в контекст применимости для обработки больших данных также технологии Business Intelligence и реляционные системы управления базами данных с поддержкой языка SQL[34].
NoSQL
MapReduce
Hadoop
R
Аппаратные решения
Существует ряд аппаратно-программных комплексов, предоставляющих предконфигурированные решения для обработки больших данных: Aster MapReduce appliance (корпорации Teradata), Oracle Big Data appliance, Greenplum appliance (корпорации EMC, на основе решений поглощённой компании Greenplum). Эти комплексы поставляются как готовые к установке в центры обработки данных телекоммуникационные шкафы, содержащие кластер серверов и управляющее программное обеспечение для массово-параллельной обработки.
Аппаратные решения для резидентных вычислений, прежде всего, для баз данных в оперативной памяти и аналитики в оперативной памяти, в частности, предлагаемой аппаратно-программными комплексами Hana (предконфигурированное аппаратно-программное решение компании SAP) и Exalytics (комплекс компании Oracle на основе реляционной системы Timesten и многомерной Essbase), также иногда относят к решениям из области больших данных[35][36], несмотря на то, что такая обработка изначально не является массово-параллельной, а объёмы оперативной памяти одного узла ограничиваются несколькими терабайтами.
Кроме того иногда к решениям для больших данных относят и аппаратно-программные комплексы на основе традиционных реляционных систем управления базами данных — Netezza, Teradata, Exadata, как способные эффективно обрабатывать терабайты и эксабайты структурированной информации, решая задачи быстрой поисковой и аналитической обработки огромных объёмов структурированных данных. Отмечается, что первыми массово-параллельными аппаратно-программными решениями для обработки сверхбольших объёмов данных были машины компаний Britton Lee, впервые выпущенные в 1983 году, и Teradata (начали выпускаться в 1984 году, притом в 1990 году Teradata поглотила Britton Lee)[37].
Аппаратные решения DAS — систем хранения данных, напрямую присоединённых к узлам — в условиях независимости узлов обработки в SN-архитектуре также иногда относят к технологиям больших данных. Именно с появлением концепции больших данных связывают всплеск интереса к DAS-решениям в начале 2010-х годов, после вытеснения их в 2000-е годы сетевыми решениями классов NAS и SAN[38].
Примечания
- Праймесбергер, 2011, “Big data refers to the volume, variety and velocity of structured and unstructured data pouring through networks into processors and storage devices, along with the conversion of such data into business advice for enterprises.”.
- PwC, 2010, Термин «большие данные» характеризует совокупности данных c возможным экспоненциальным ростом, которые слишком велики, слишком неформатированы или слишком неструктурированы для анализа традиционными методами., с. 42.
- McKinsey, 2011, “Big data” refers to datasets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyze, p. 1.
- Майер-Шенбергер, 2014.
- Gartner, 2011.
- Канаракус, Крис. Машина Больших Данных. Сети, № 04, 2011. Открытые системы (1 ноября 2011). — «…большие данные как «три V»: volume («объем» — петабайты хранимых данных), velocity («скорость» — получение данных, преобразование, загрузка, анализ и опрос в реальном времени) и variety («разнообразие» — обработка структурированных и полуструктурированных данных различных типов)». Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- PwC, 2010, К началу 2010 года Hadoop, MapReduce и ассоциированные с ними технологии с открытым кодом стали движущей силой целого нового явления, которое O’Reilly Media, The Economist и другие издания окрестили большими данными, с. 42.
- The World’s Technological Capacity to Store, Communicate, and Compute Information. MartinHilbert.net. Дата обращения: 13 апреля 2016.
- Черняк, 2011, Big Data относится к числу немногих названий, имеющих вполне достоверную дату своего рождения — 3 сентября 2008 года, когда вышел специальный номер старейшего британского научного журнала Nature, посвященный поиску ответа на вопрос «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объемами данных?» […] осознавая масштаб грядущих изменений, редактор номера Nature Клиффорд Линч предложил для новой парадигмы специальное название Большие Данные, выбранное им по аналогии с такими метафорами, как Большая Нефть, Большая Руда и т. п., отражающими не столько количество чего-то, сколько переход количества в качество.
- Пример употребления метафоры Big Oil (англ.), ср. также повесть «Большая руда», фильм «Большая нефть»
- Дубова, Наталья. Большая конференция о Больших Данных. Открытые системы (3 ноября 2011). — «На форуме IBM Information on Demand, собравшем более 10 тыс. участников, центральной темой стала аналитика Больших Данных». Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- Henschen, Doug. Oracle Releases NoSQL Database, Advances Big Data Plans (англ.). InformationWeek (24 октября 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- Finley, Klint. Steve Ballmer on Microsoft's Big Data Future and More in This Week's Business Intelligence Roundup (англ.). ReadWriteWeb (17 июля 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- Шах, Агам. HP меняет персональные компьютеры на Большие Данные. Открытые системы (19 августа 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- EMC Tries To Unify Big Data Analytics (англ.). InformationWeek (21 сентября 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- Woo, Benjamin et al. IDC's Worldwide Big Data Taxonomy (англ.). International Data Corporation (1 октября 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- Evelson, Boris and Hopkins, Brian. How Forrester Clients Are Using Big Data (англ.). Forrester Research (20 сентября 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- McKinsey, 2011.
- Thibodeau, Patrick. Gartner's Top 10 IT challenges include exiting baby boomers, Big Data (англ.). Computerworld (18 октября 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- Черняк, 2011, По оценкам экспертов, например McKinsey Institute, под влиянием Больших Данных наибольшей трансформации подвергнется сфера производства, здравоохранения, торговли, административного управления и наблюдения за индивидуальными перемещениями.
- MSc in Data Science (англ.). School of Computing. Dundee University (1 января 2013). — «A data scientist is a person who excels at manipulating and analysing data, particularly large data sets that don’t fit easily into tabular structures (so-called “Big Data”)». Дата обращения: 18 января 2013. Архивировано 22 января 2013 года.
- Master of Science degree. Harvard's first degree program in Computational Science and Engineering is an intensive year of coursework leading to the Master of Science (англ.). Institute for Applied Computational Science. Harvard University (1 января 2013). — «“…Many of the defining questions of this era in science and technology will be centered on ‘big data’ and machine learning. This master’s program will prepare students to answer those questions…”». Дата обращения: 18 января 2013. Архивировано 22 января 2013 года.
- Simon Sharwood. Forget Big Data hype, says Gartner as it cans its hype cycle (англ.). The Register (21 августа 2015). Дата обращения: 19 февраля 2017.
- Doug Laney. 3D Data Management: Controlling Data Volume, Velocity, and Variety (англ.). Meta Group (6 февраля 2001). Дата обращения: 19 февраля 2017.
- The Four V´s of Big Data (англ.). IBM (2011). Дата обращения: 19 февраля 2017.
- Neil Biehn. The Missing V’s in Big Data: Viability and Value (англ.). Wired (1 мая 2013). Дата обращения: 19 февраля 2017.
- Eileen McNulty. Understanding Big Data: The Seven V’s (англ.). Dataconomy (22 мая 2014). Дата обращения: 19 февраля 2017.
- Чэнь и др., 2014, “big data technologies describe a new generation of technologies and architectures, designed to economically extract value from very large volumes of a wide variety of data, by enabling the high-velocity capture, discovery, and/or analysis”, p. 4.
- Чэнь и др., 2014, p. 19—23.
- McKinsey, 2011, pp. 7—8.
- Черняк, 2011.
- McKinsey, 2011, pp. 27—31.
- Чэнь и др., 2014, “Big data shall mean the data of which the data volume, acquisition speed, or data representation limits the capacity of using traditional relational methods to conduct effective analysis or the data which may be effectively processed with important horizontal zoom technologies”, p. 4.
- McKinsey, 2011, pp. 31—33.
- Черняк, 2011, Следующим шагом может стать технология SAP HANA (High Performance Analytic Appliance), суть которой в размещении данных для анализа в оперативной памяти.
- Darrow, Barb. Oracle launches Exalytics, an appliance for big data (англ.). GigaOM (2 октября 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
- Черняк, 2011, …первой создать «машину баз данных» удалось компании Britton-Lee в 1983 году на базе мультипроцессорной конфигурации процессоров семейства Zilog Z80. В последующем Britton-Lee была куплена Teradata, с 1984 года выпускавшая компьютеры MPP-архитектуры для систем поддержки принятия решений и хранилищ данных.
- Леонид Черняк. Большие данные возрождают DAS. «Computerworld Россия» , № 14, 2011. Открытые системы (5 мая 2011). Дата обращения: 12 ноября 2011. Архивировано 3 сентября 2012 года.
{kind=link}
Литература
- Min Chen, Shiwen Mao, Yin Zhang, Victor C.M. Leung. Big Data. Related Technologies, Challenges, and Future Prospects. — Spinger, 2014. — 100 p. — ISBN 978-3-319-06244-0. — doi:10.1007/978-3-319-06245-7.
- Виктор Майер-Шенбергер, Кеннет Кукьер. Большие данные. Революция, которая изменит то, как мы живём, работаем и мыслим = Big Data. A Revolution That Will Transform How We Live, Work, and Think / пер. с англ. Инны Гайдюк. — М.: Манн, Иванов, Фербер, 2014. — 240 с. — ISBN 987-5-91657-936-9.
- Preimesberger, Chris Hadoop, Yahoo, 'Big Data' Brighten BI Future (англ.). EWeek (15 августа 2011). Дата обращения: 12 ноября 2011. Архивировано 17 мая 2012 года.
- Леонид Черняк. Большие Данные — новая теория и практика // Открытые системы. СУБД. — 2011. — № 10. — ISSN 1028-7493.
- Алан Моррисон и др. Большие Данные: как извлечь из них информацию. Технологический прогноз. Ежеквартальный журнал, российское издание, 2010 выпуск 3. PricewaterhouseCoopers (17 декабря 2010). Дата обращения: 12 ноября 2011. Архивировано 11 марта 2012 года.
- Gartner Says Solving 'Big Data' Challenge Involves More Than Just Managing Volumes of Data (англ.). Gartner (27 июня 2011). Дата обращения: 12 ноября 2011. Архивировано 17 мая 2012 года.
- James Manyika et al. Big data: The next frontier for innovation, competition, and productivity (англ.) (PDF). McKinsey Global Institute, June, 2011. McKinsey (9 августа 2011). Дата обращения: 12 ноября 2011. Архивировано 11 декабря 2012 года.