Item Response Theory
Современная теория тестирования (англ. Item Response Theory) — (иногда по-русски - Современная теория тестов, Теория ответов на задания, Теория моделирования и параметризации педагогических тестов) набор методов, позволяющий оценить вероятность правильного ответа испытуемых на задания различной трудности. Она используется для того чтобы избавиться от плохих (неинформативных) вопросов в опроснике, оценки взаимосвязи латентных конструктов между собой и с наблюдаемыми переменными, оптимизации предъявления заданий респондентам, и т.д. В русском языке название Item Response Theory переводится различным образом. Ю.Нейман и В.Хлебников предлагают называть её «Теория моделирования и параметризации педагогических тестов» (ТМППТ)[1]. В.Аванесов — «Математико-статистическая теория оценки латентных параметров заданий теста и уровня подготовленности испытуемых»[2]. Однако одним из наиболее удачных способов перевода является "современная теория тестирования", поскольку её модели описывают не тестовые задания и не тест сам по себе, а результат (а многие современные модели - и процесс) взаимодействия респондентов и заданий.
В психометрике современная теория тестирования (IRT) является парадигмой для проектирования, анализа и оценки тестов, опросников и подобных измерительных инструментов. Эта теория тестирования предполагает, что существует взаимосвязь между модельной предсказуемостью ответов на задание и общим качеством знания. Для того, чтобы оценить целевые параметры заданий и респондентов используются различные статистические модели[3]. В отличие от более простых альтернатив для создания шкал и оценки ответов на опросники, современная теория тестирования не предполагает, что каждый вопрос одинаково трудный. Это отличает IRT от, например, предположения Ликерта в шкалировании о том, что «все задания считаются репликациями друг друга или другими словами: задания считаются взаимозаменяемыми»[4]. Напротив, современная теория тестирования рассматривает параметры каждого задания (задающие ICC (Item Characteristic Curve) - характеристическую кривую задания) как информацию, которая должна быть включена в калибровку модели.
Таким образом, IRT моделирует вероятность ответа каждого респондента на каждое задание теста. Фундаментальной характеристикой современной теории тестирования и ключевым её определением является идея разделения параметров респондентов и заданий. То есть, вероятность правильного ответа на задание является результатом взаимодействия латентных параметров респондента и задания. Конкретный способ их взаимодействия определяется допущениями исследователя и транслируется в уравнение конкретной математической функции - модели современной теории тестирования.
Модели современной теории тестирования тесно связаны с конфирматорным факторным анализом, обобщенными линейными моделями смешанных эффектов, сетевыми моделями из статистической физики (полями Маркова и моделью Изинга), и отдельными методами наук о данных (модельными методами коллаборативной фильтрации и ограниченными машинами Больцмана). Современные модели IRT позволяют моделировать новые источники информации (например, время ответов, попытки решения заданий); комплексные нелинейные (например, потолочные) зависимости между различными латентными переменными; моделировать эффекты рейтеров, которые начисляют баллы за открытые ответы (и позволяют достигать инвариантности итоговых оценок способности относительно рейтера); моделировать композитные и многомерные конструкты; моделировать изменения в уровне латентной переменной во времени; использовать дискретные оценки способности, превращающие модель ранжирвоания в классификатор, и т.д. На сегодняшний день, IRT - одна из самых передовых и теоретически обоснованных областей вычислительных наук о поведении.
История
Общим источником для создания IRT послужила так называемая логистическая функция вида , известная в биологической науке с 1844 года. С тех пор она широко применялась в биологии для моделирования прироста растительной массы или роста организмов. Как модель психологического и педагогического измерения она начала применяться, начиная с 50-х годов XX столетия. У истоков развития моделей IRT лежали стремление визуализировать формальные характеристики тестовых заданий, попытки преодолеть многочисленные недостатки классической теории тестов, повысить точность измерения и, наконец, стремление оптимизировать процедуру контроля за счёт адаптации теста к уровню подготовленности студента с помощью компьютера[2].

Первоначальная работа IRT как теории возникла в 1950-х и 1960-х годах. Это были участники организации Educational Testing Service: Фредерик Лорд, датский математик Георг Раш и австрийский социолог Полом Лазарсфельдом. Ключевыми фигурами, продвигавшими прогресс IRT, являются Бенджамин Дрейк и Дэвид Андрич.
В числе первых предпосылок к созданию IRT стали те результаты исследовательской работы Альфред Бине и Теодор Симон[5], в которых было отражено стремление авторов выявить — как, образно говоря, «работают» те задания, которые они давали детям разного возраста. Расположив затем на координатной плоскости точки, где по оси абсцисс откладывался возраст (в годах), а по оси ординат — доля правильных ответов в каждой возрастной группе испытуемых, авторы увидели, что полученные точки, после усреднения по каждой группе, напоминают кривую, позже названной характеристической.
В 1936 году M.W.Richardson провела обширное эмпирическое исследование, опросив 1200 студентов по 803 заданиям, в процессе которого студенты, в зависимости от полученного ими тестового балла, были разделены на 12 групп, по сто человек в каждой. Она первой обратила внимание на различающуюся крутизну кривых тестовых заданий и предложила рассматривать меру крутизны как примерную оценку дифференцирующей способности задания[6]. M.W.Richardson была, по-видимому, первой, осознавшей плодотворность использования усреднённых точек для графической презентации формальных характеристик заданий проектируемых тестов[7].
В частности, целью IRT является создание основы для анализа того, насколько хорошо работают оценки, и насколько хорошо работают отдельные элементы оценки. Наиболее распространённая область применения современной теории тестирования — образование, где психометрики используют её для разработки и дизайна экзаменов, поддержания банков вопросов для экзаменов и сравнения трудностей вопросов для последующих версий экзаменов[8]. В этой области, в силу высоких ставок решений, принимаемых по результатам тестирования, аргументация качества измерительного инструментария является крайне важным элементом ответственности разработчика и конкурентным преимуществом его инструмента, и модели современной теории тестирования занимают в этой аргументации одно из ключевых мест.
Функция ответа на тестовое задание (Item Response Function IRF)
IRF даёт вероятность того, что человек с заданным уровнем способности ответит на задание правильно.
Трехпараметрическая логистическая модель
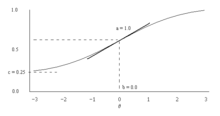
Трёхпараметрическая логистическая модель (3PL) современной теории тестирования, задает вероятность правильного ответа на дихотомическое задание i (как правило, вопрос с выбором одного ответа из ряда предложенных) как:

Где обычно следует нормальному распределению (в маргинализированных моделях). После калибровки модели, способность каждого респондента оценивается для сообщения результатов пользователям. , и — это параметры заданий. Параметры заданий определяют форму функции ответа на задание. На рисунке 1 изображена модельная характеристическая кривая задания из модели 3PL.




Параметры задания можно интерпретировать как изменение формы стандартной логистической функции:

Параметры, описывающие задания теста:
- b — трудность. Это значение указывает, насколько лёгок или сложен вопрос. - вероятность решения задания в точке перегиба функции.
- a — дискриминативность. Это значение говорит, насколько эффективно этот вопрос может различать студентов по уровню их способности (как правило, желаемой является высокая дискриминативность заданий - она показывает, что слабые респонденты задание не решают, а сильные - решают).
- c — вероятность псевдо-случайного угадывания. Это значение указывает, насколько вероятно, что испытуемые могут получить правильный ответ, случайно выбирая его из предложенных опций. — ассимптотический минимум. Однако 3PL модель является неидентифицированной при классической фриквентистской оценке параметров 3PL модели или отсутствии ограничений других параметров заданий.


Модели IRT
Модели IRT можно разделить на два семейства: одномерные и многомерные. Одномерные модели требуют единственного значения (способности) измерения . Предполагается, что ответы на задания в многомерных моделях IRT зависят от нескольких латентных переменных, характеризующих респондентов.
Модели IRT также можно классифицировать по количеству баллов в задании. Чаще всего задания бывают дихотомическими (возможные баллы - 0 (все неправильно) или 1 (все правильно)). Другой класс моделей применим к политомическим заданиям, где каждый ответ отражает частичную правильность выполнения задания[9]. Общим примером этого являются задания с ответной шкалой Ликерта, например «от 0 до 4».
Число параметров, входящих в аналитическое задание функций, является основанием для подразделения семейств логических функций на классы.
Среди логистических функций различают[10]:
1) Однопараметрическая модель Г. Раша (Georg Rasch)— , где и — параметры респондентов и задания i соответственно;


Иногда под знак экспоненты заносится множитель 1.702, который используется для совместимости модели Раша с моделью A.Fergusson, где вероятность правильного ответа на задание выражена интегралом нормального распределения (формулой кумулятивной плотности вероятности нормального распределения), что позволяет использовать вместо логистических кривых хорошо изученную интегральную функцию стандартного нормального распределения.
Модель Раша носит название «1 Parametric Logistic Latent Trait Model» (1PL), а модель A.Fergusson — «1 Parametric Normal Ogive Model» (1PNO). Поскольку модель Раша описывает вероятность решения задания респондентом как функцию одного параметра задания (разности ; в некоторых интерпретациях - из-за того, что у задания только один параметр ), её называют однопараметрической моделью современной теории тестирования.

Взаимодействие двух множеств и образует данные, обладающие свойством «совместной аддитивности» (conjoint additivity). Правильное использование модели Раша позволяет достичь полной независимости параметров респондентов от того, на какие задания они отвечают, и параметров заданий от того, какие респонденты на них отвечают. Это свойство измерений с помощью модели Раша носит название специфической объективности (specific objectivity).


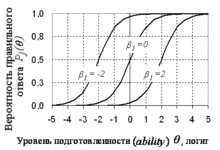
На рис. 2 показаны три характеристические кривые с трудностями заданий -2, 0 и +2 логита (первое самое лёгкое, второе — среднее, третье самое трудное). Из приведённых зависимостей видно, что чем выше уровень подготовленности θ испытуемого, тем выше вероятность успеха в том или ином задании. Например, для испытуемого с вероятность правильно ответить на первое задание близка к единице, на второе равна 0.5 и на третье почти равна нулю. Отметим, что в точках, где вероятность правильного ответа равна 0.5. То есть, если трудность задания равна уровню подготовленности испытуемого, то он с равной вероятностью может справиться или не справиться с этим заданием.


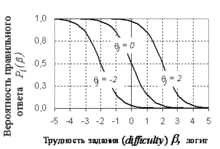
На рис. 3 показаны три характеристические кривые испытуемых — «Person Characteristic Curve» (PCC). Показаны графики для трёх испытуемых с уровнем подготовленности -2 логита (самый слабый), 0 логитов (средний) и +2 логита (сильный испытуемый).
Из приведённых зависимостей видно, что чем выше уровень подготовленности, тем выше вероятность правильного ответа на задание. Например, задание с трудностью b = 0 первый испытуемый ( q=-2) практически не сможет выполнить, второй (q = 0) имеет вероятность выполнения задания равную 0.5, третий (q=+2) легко справится с заданием, так как для него вероятность успеха почти равна единице.
2) двухпараметрическая модель А. Бирнбаума:

Если тест содержит задания с различной дифференцирующей способностью (), то однопараметрическая модель 1PL не может описать такие данные. Для преодоления этой трудности А.Бирнбаум ввёл ещё один параметр — (item discrimination parameter), параметр дискриминативности.
Параметр определяет наклон (крутизну) характеристической кривой i-го задания. Примеры характеристических кривых показаны на рис. 4. Видно, что чем больше тем круче кривая, и тем выше дифференцирующая способность задания.
3) трехпараметрическяа модель А. Бирнбаума:

где является третьим параметром задания, характеризующим вероятность правильного ответа на i-е задание.
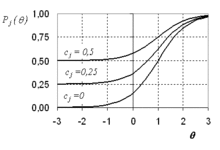
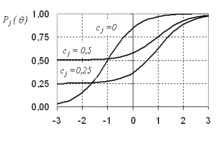
Для ещё лучшего соответствия эмпирическим данным А.Бирнбаум ввёл третий параметр — параметр угадывания. На рис. 5 приведены примеры характеристических кривых для трёх заданий с трудностью = 1, дискриминационным параметром = 1 и различными параметрами угадывания = 0, = 0.25, = 0.5. Из приведённых графиков видно, что наличие параметр угадывания приводит к пропорциональному сжатию ICC от до 1.
4) четырехпараметрическая модель А. Бирнбаума:

где является четвертым параметром задания, характеризующим вероятность ошибки при ответе на i-е задание. В этой модели характеристическая кривая сжимается подобно 3PL модели, но не от до 1, а от от до .

Таким образом, модель 2PL является обобщением модели 1PL на случай с заданиями с разными параметрами дискриминативности, а модель 3PL - обобщением модели 2PL на случай с заданиями с разными параметрами угадывания, и при этом, она в свою очередь является частным случаем 4PL модели.
Также существуют "5PL" модели, описывающие задания с немонотонной характеристической кривой - той, которая отражает возрастание вероятности решения задания до определенного уровня способности, а затем её снижение.
Модель Раша
Характерной чертой моделей семейства моделей Раша (включая политомические модели) является параллельность характеристических кривых заданий (они не пересекаются), см. рис. 3. Это подразумевает, что вероятность решения более легкого задания всегда ниже, чем более трудного - это выстраивает иерархию заданий на всем континууме способности и позволяет её качественно интерпретировать.
Совершенно иная картина наблюдается для двух- и трёхпараметрической моделей. На рис.4 это хорошо видно. Задание с = 0.5 в области положительных значений θ является самым трудным из представленных трёх заданий, то есть вероятность правильного ответа на это задание самая низкая. В области же отрицательных значений q это же задание теперь уже самое лёгкое — вероятность правильного ответа на него наибольшая. Получается, что для слабых учащихся это самое лёгкое задание, а для сильных учащихся — самое трудное. Таким образом, в отличие от моделей Раша, иерархия заданий в 2PL выстраивается не на всем континууме способности, а от одного пересечения характеристических кривых (любых) до другого, после чего начинается новая иерархия заданий, что лишает анализ этих иерархий всяческих практических соображений.
Аналогичная картина наблюдается и для трёхпараметрической модели. На рис.5 показан редкий случай непересекающихся характеристических кривых, так как для них выбраны одинаковые параметры =1 и =1, то есть все три задания имеют одинаковую трудность и одинаковый параметр дискриминативности.
На рис.6 приведён другой пример. Здесь у задания с параметром =0 изменена трудность = -1, что немедленно вызвало пересечение характеристических кривых. Задание с =0 в области θ < -2 является самым трудным. В области -1.5 < θ < -1 это задание легче задания с =0.25 и труднее задания с =0.5. В области θ > -1 задание с =0 является самым лёгким. Подобное пересечение ICCв практике всегда происходит в 2PL и 3PL моделях.
Однако только параллельность характеристических кривых способна привести к свойству специфической объективности, т.е., только модели Раша способны обеспечить достижение независимости параметров респондентов и заданий друг от друга. Тем не менее, это не означает, что специфические проблемы психометрики нельзя решать в 2PL и более старших моделях.
Основные допущения современной теории тестирования[11]
1) Существуют латентные/скрытые параметры респондентов и заданий (которые недоступны для непосредственного наблюдения). Например, в интеллектуальном тестировании — это уровень интеллекта испытуемого и уровень трудности задания (в моделях Раша).
2) Существуют индикаторы, вероятность проявления которых определяется латентными параметрами. Однако, в отличие от параметров, индикаторы доступны для наблюдения. По значениям индикаторов можно судить о значениях латентных параметров.
3) Устаревшая формулировка: Оцениваемый латентный параметр должен быть одномерным (шкала должна измерять одну и только одну переменную). Если условие одномерности не выполняется, то необходимо перерабатывать тест. Все задания, которые нарушают одномерность, должны быть исключены из шкалы или изменены так, чтобы вызывать, потому что это вызывает как нарушение допущений модели, так и загрязняет интерпретацию оценок параметров.
Современная формулировка: Задания должны быть локально независимы на параметрах респондентов. Это означает, что при контроле параметров респондентов, ковариаций между ответами на задания нет. Другими словами - если отобрать всех респондентов с определенным уровнем способности (например, равно 1 логит, и сделать это для каждого возможного значения способности), то их ответы на задания абсолютно случайны. В этом случае, вся информация, связывающая задания - это уровень способности респондентов, который извлекается моделью, и ковариации между остатками (зависимости заданий локально на параметрах респондентов) нет. Эта формулировка обеспечивает большую общность методов преодоления локальной зависимости заданий (неодномерности теста), поскольку позволяет включать в модель дополнительные параметры респондентов (превращая модель в бифакторную или тестлет-модль), отражающие взаимодействие респондентов и тестлетов (групп заданий, демонстрирующих локальную зависимость). В этом случае, дополнительные параметры респондентов выступают как специфические факторы из бифакторных моделей и "впитывают" в себя локальную зависимость. При их контроле, возможно достижение локальной независимости на параметрах респондентов, за счет увеличения количества этих параметров. При этом, это допущение позволяет встроить современную теорию тестирования в т.н. теорию условной ковариации (conditional covariance theory), для всех классов моделей которой характерно это допущение: для любых , где - ответы на задания. К теории условной ковариации относятся анализ латентных классов, модели когнитивной диагностики, конфирматорный факторный анализ, байесовские сети, и иные методы моделирования латентных переменных.



Сравнение современной и классической теорий тестов[12]
| Классическая теория тестирования (КТТ) | IRT (модели Раша) | |
|---|---|---|
| 1 | Оценки трудности тестовых заданий зависят от уровня подготовленности конкретной выборки испытуемых | Оценки трудности тестовых заданий инвариантны относительно контингента испытуемых, по результатам тестирования которых они получены |
| 2 | Оценки уровня подготовленности испытуемых (первичные баллы) зависят от уровня трудности конкретного теста | Оценки уровня подготовленности испытуемых инварианты относительно тестовых заданий, по результатам выполнения которых они получены |
| 3 | Ошибка измерения является величиной постоянной для всех испытуемых. Ошибка измерения заданий не оценивается | Ошибка измерения оценивается индивидуально для каждого испытуемого и каждого задания. Причём ошибка подсчитывается непосредственно, а не косвенно |
| 4 | Методы оценивания надёжности требуют существенных ограничений и дают искажённые результаты | Возможно оценить отдельно надёжность измерения испытуемых и надёжность оценивания заданий теста |
| 5 | Шкала первичных баллов является порядковой. Никакое преобразование первичных баллов в КТТ не повышает уровня шкалы | Шкала логитов является интервальной, что даёт возможность перейти от ранжирования испытуемых и заданий к измерению соответственно уровня подготовленности и уровня трудности |
| 6 | Нормальное распределение баллов испытуемых и трудностей заданий теста играет существенную роль | Нормальность распределения параметров не требуется |
| 7 | Способы установления соответствия между баллами испытуемых, выполнявших различные варианты, требуют трудновыполнимых предположений | Возможно выполнить процедуру выравнивания показателей различных вариантов и осуществить шкалирование на единой метрической шкале. Возможно создание банков заданий |
| 8 | Не подходит для компьютерного адаптивного тестирования | Вся теория компьютерного адаптивного тестирования базируется на IRT |
| 9 | Анализ концентрируется только на оценивании трудности заданий и мер испытуемых | Возможен анализ влияния дополнительных факторов на оценки параметров заданий и мер испытуемых |
| 10 | Искусственное назначение весов заданиям может привести к искажению информации об уровне подготовленности испытуемых | Вес (информационный вклад) тестового задания может быть вычислен отдельно вне зависимости от характеристик других заданий |
См. также
- Надёжность психологического теста
- Психологическое тестирование
- Concept inventory
- Differential item functioning
- Person-fit analysis
- Психометрия
- Scale (social sciences)
- Стандартизованный тест
Примечания
- Нейман Ю.М., Хлебников В.А. Введение в теорию моделирования и параметризации педагогических тестов. -М.: Прометей, -169 с. Архивированная копия (недоступная ссылка). Дата обращения: 3 июня 2017. Архивировано 4 июня 2017 года.
- Аванесов В.С. Применение тестовых форм в Rasch Measurement // Педагогические измерения, 2005, №4. -С.3-20. Архивированная копия (недоступная ссылка). Дата обращения: 3 июня 2017. Архивировано 4 июня 2017 года.
- National Council on Measurement in Education http://www.ncme.org/ncme/NCME/Resource_Center/Glossary/NCME/Resource_Center/Glossary1.aspx?hkey=4bb87415-44dc-4088-9ed9-e8515326a061#anchorI Архивная копия от 22 июля 2017 на Wayback Machine
- A. van Alphen, R. Halfens, A. Hasman and T. Imbos. (1994). Likert or Rasch? Nothing is more applicable than good theory. Journal of Advanced Nursing. 20, 196-201
- Binet A., Simon T.H. The Development of Intelligence in Young Children. Vineland, NJ: The Training School, 1916.
- Richardson Marion W. The Relation Between the Difficulty and the Difference Validity of a Test / Psychometrika, 1936, 1: 2, 33-49.
- Richardson M.W. Notes on the Rationale of Item Analysis./Psychometrika, 1936,1: 169-76.
- Hambleton, R. K., Swaminathan, H., & Rogers, H. J. (1991). Fundamentals of Item Response Theory. Newbury Park, CA: Sage Press.
- Ostini, Remo; Nering, Michael L. (2005). Polytomous Item Response Theory Models. Quantitative Applications in the Social Sciences. 144. SAGE. ISBN 978-0-7619-3068-6.
- http://koi.tspu.ru/koi_books/samolyuk/lek13.htm
- М.К. Рыбникова. Теория тестов: классическая, современная и "интеллектуальная" http://www.ht.ru/cms/component/content/article/1-aricles/109862-13022014
- Карданова Е.Ю. Преимущества современной теории тестирования по сравнению с классической теорией тестирования. Вопросы тестирования в образовании. 2004, № 10
Литература
- Lord, F.M. (1980). Applications of item response theory to practical testing problems. Mahwah, NJ: Erlbaum.
- Embretson, Susan E.; Reise, Steven P. Item Response Theory for Psychologists (неопр.). — Psychology Press, 2000. — ISBN 978-0-8058-2819-1.
- Baker, Frank (2001). The Basics of Item Response Theory. ERIC Clearinghouse on Assessment and Evaluation, University of Maryland, College Park, MD.
- Baker, Frank B.; Kim, Seock-Ho. Item Response Theory: Parameter Estimation Techniques (англ.). — 2nd. — Marcel Dekker, 2004. — ISBN 978-0-8247-5825-7.
- Handbook of Modern Item Response Theory (неопр.) / van der Linden, Wim J.; Hambleton, Ronald K.. — Springer, 1996. — ISBN 978-0-387-94661-0.
- de Boeck, Paul; Wilson, Mark. Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach (англ.). — Springer, 2004. — ISBN 978-0-387-40275-8.
- Fox, Jean-Paul. Bayesian Item Response Modeling: Theory and Applications (англ.). — Springer, 2010. — ISBN 978-1-4419-0741-7.
- Крокер, Линда; Джеймс, Алгина. Введение в классическую и современную теорию тестов. — ВЫСШЕЕ ОБРАЗОВАНИЕ СЕГОДНЯ, 2010. — ISBN 978-5-98704-437-5.
Ссылки
- "HISTORY OF ITEM RESPONSE THEORY (up to 1982)", en:University of Illinois at Chicago
- A Simple Guide to the Item Response Theory(PDF)
- Psychometric Software Downloads
- flexMIRT IRT Software Архивная копия от 5 марта 2016 на Wayback Machine
- IRT Tutorial
- IRT Tutorial FAQ
- An introduction to IRT
- The Standards for Educational and Psychological Testing
- IRT Command Language (ICL) computer program
- IRT Programs from SSI, Inc.
- IRT Programs from en:Assessment Systems Corporation
- Latent Trait Analysis and IRT Models
- Rasch analysis
- Rasch Analysis Programs from Winsteps
- Free IRT software
- Пакеты для применения IRT в R
- IRT / EIRT support in Lertap 5 Архивная копия от 4 марта 2016 на Wayback Machine
- ShinyItemAnalysis (2017) приложение для работы с IRT онлайн
- Задачи оценивания параметров модели IRT
- Применение IRT в тестировании учебных достижений
