Слияние данных
Слияние данных является процессом объединения источников данных для получения более согласующейся, точной и полезной информации, чем информация от одного отдельного источника[1].
Процессы слияния данных часто группируются как низкое, среднее или высокое слияние, в зависимости от стадии обработки, на котором слияние производится[2]. Низкоуровневое слияние данных комбинирует некоторые источники сырых данных для получения других сырых данных. Требуется, чтобы слитые данные были более информативны и синтетические, чем исходные данные.
Например, сбор и обобщение данных от датчиков известно как (мультисенсорное) слияние данных и является подмножеством объединения информации.
Люди как пример слияния данных
Люди являются прямым примером слияния данных. Как люди, мы опираемся широко на наши чувства, такие как Зрение, Запах, Вкус, Звук и Физическое движение. Комбинация всех этих чувств комбинируется постоянно, чтобы помочь нам в выполнении большинства, если не всех, задач в нашей повседневной жизни. То есть это является прямым примером слияния данных. Мы опираемся на слияние запаха, вкуса и осязание пищи, чтобы убедиться, что она съедобна. Аналогично, мы опираемся на наше зрение и нашу возможность слышать и контролировать движение нашего тела для прогулок или вождения автомобиля и осуществляем большинство задач в нашей жизни. Во всех этих случаях мозг осуществляет слияние и контролирует, что мы должны сделать в следующий момент. Наш мозг опирается на слияние данных, собранных из вышеперечисленных органов чувств[3].
Геопространственные приложения
В геопространственной области исследования (GIS) слияние данных является часто синонимом интеграции данных. В этих приложениях имеется часто необходимость комбинировать различные наборы данных в объединённые (слитые) наборы данных, которые включает все точки данных. Слитые наборы данных отличаются от простого объединения в том, что точки в слитом наборе данных содержат атрибуты и метаданные, которые могут не содержаться у точек в оригинальном наборе данных.
Упрощённый пример этого процесса показан ниже, где набор данных α сливается с набором данных β, образуя слитый набор данных δ. Точки данных в множестве α имеют пространственные координаты X и Y и атрибуты A1 и A2. Точки данных в множестве β имеют пространственные координаты X и Y и атрибуты B1 и B2. Слитый набор данных содержит все точки и атрибуты.
| Входной набор данных α | Входной набор данных β | Слитый набор данных δ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
В простом случае, когда все атрибуты однородны по всей области, атрибуты могут быть назначены просто: M?, N?, Q?, R? в M, N, Q, R. В действительных приложениях атрибуты не однородны и нужны обычно некоторые виды интерполяции для правильного назначения атрибутов точкам данных в слитом наборе.
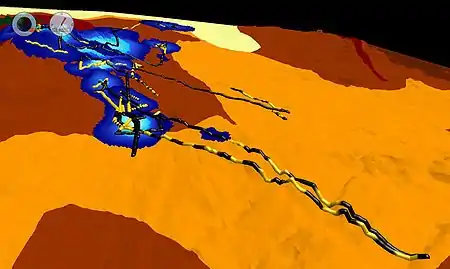
В существенно более сложном приложении исследователи морских животных использовали слияние данных о движении животных с батиметрическими и метеорологическими данными, с температурой поверхности моря и местообитанием животных для рассмотрения и понимания поведения животных как реакция на внешние воздействия, такие как погода и температура воды. Каждый из этих наборов данных представляет различные пространственные решётки и частоту отбора данных, так что простая комбинация данных, скорее всего, дала бы необоснованные предположения и испортила бы результаты анализа. Однако путём слияния данных все данные и атрибуты собираются вместе в одно целое, в котором создаётся более полная картина окружения. Это даёт возможность учёным определить ключевые места и время и образует новое представление о взаимодействии окружающей среды и поведения животного.
На изображении справа изучаются лобстеры на берегу Тасманского моря. Хью Педерсон из Университета Тасмани использовал программы слияния данных для слияния данных слежения передвижения южного каменного лобстера (на изображении кодирован жёлтым цветом и чёрным для дневного и ночного времени соответственно) с батиметрическими и данными местообитания в одну 4-мерную картину поведения лобстера.
Интеграция данных
В приложениях вне геопространственных областей использование терминов интеграция данных и слияние данных различается. В таких областях, как бизнес-аналитика, например, термин «интеграция данных» используется для описания комбинирования данных, в то время как термин «слияние данных» является интеграцией с последующим уплотнением и заменой данных. Интеграцию данных можно рассматривать как комбинацию множеств, при которой большее множество сохраняется, в то время как слияние является техникой сокращения множества с улучшением надёжности.
Модель JDL/DFIG
В середине 1980-х содиректора Лабораторий (англ. Joint Directors of Laboratories, JDL) образовали Подкомиссию Слияния Данных (которая позднее стала известна как Группа Слияния Данных, англ. Data Fusion Group, DFG). С появлением «Всемирной паутины» (World Wide Web) слияние данных стало включать слияние датчиков и слияние информации. Группа JDL/DFIG представила модель слияния данных, которая разделяется на различные процессы. В настоящее время есть шесть уровней модели Группы Слияния Данных (англ. Data Fusion Information Group, DFIG):
Level 0: Предварительная обработка исходных данных/Оценка содержания (англ. Source Preprocessing/subject Assessment)
Level 1: Оценка объекта (англ. Object Assessment)
Level 2: Оценка ситуации (англ. Situation Assessment)
Level 3: Оценка влияния (англ. Impact Assessment) (или Отыскание угроз, англ. Threat Refinement)
Level 4: Усовершенствование процесса (англ. Process Refinement)
Level 5: Пользовательское улучшение (англ. User Refinement или Когнитивное улучшение, англ. Cognitive Refinement)
Хотя модель JDL (уровни 1–4) используется по сей день, она часто критикуется за требование, чтобы уровни обязательно реализовывались в указанном порядке, а также отсутствия адекватного представления участия человека. Модель DFIG (уровни 0–5) учитывает влияние осведомлённости об окружающей обстановке, пользовательские улучшения и управление работами[4]. Несмотря на недостатки, модели JDL/DFIG полезны для визуализации процесса слияния данных, что способствует обсуждению и общему пониманию[5], также имеет важное значение для разработки слияния информации на системном уровне[4].
От различных датчиков трафика на дороге
Данные от различных сенсорных технологий могут быть скомбинированы разумным образом для определения точного состояния трафика. Подход, основанный на слиянии данных, который использует полученные от дороги акустические данные, изображения и данные датчиков, показывает преимущество комбинирования различных индивидуальных методов[6].
Объединение решений
Во многих случаях географически разбросанные датчики строго ограничены по потреблению энергии и пропускной способности. Поэтому сырые данные, касающиеся определённого явления, часто приводятся к нескольким битам для каждого датчика. Когда делаем вывод о бинарном событии (т.е. или ), в крайнем случае только бинарное решение посылается от датчика в центр объединения решений и комбинируется для получения улучшенной классификации[7][8][9].


Для улучшения контекстуальной осведомлённости
С большим числом встроенных датчиков, включая датчики движения, датчиков окружающей среды, датчиков положения, современные мобильные устройства обычно дают мобильным приложениям получить доступ к большому числу данных от датчиков, которые могут быть использованы для улучшения контекстуальной осведомлённости. Используя техники обработки сигналов и слияния данных, таких как генерация признаков, оценка целесообразности и метод главных компонент для анализа таких данных от датчиков, существенно улучшают классификацию движения и контекстуальное состояния устройства[10].
Примечания
- Haghighat, Abdel-Mottaleb, Alhalabi, 2016, с. 1984-1996.
- Klein, 2004, с. 51.
- Penn State WebAccess Secure Login: (англ.). ieeexplore-ieee-org.ezaccess.libraries.psu.edu. Дата обращения: 27 июня 2018.
- Blasch, Bossé, Lambert, 2012.
- Liggins, Hall, Llinas, 2008.
- Joshi, Rajamani, Takayuki, Prathapaneni, Subramaniam, 2013.
- Ciuonzo, Papa, Romano, Salvo Rossi, Willett, 2013, с. 861–864.
- Ciuonzo, Salvo Rossi, 2014, с. 208–212.
- Ciuonzo, De Maio, Salvo Rossi, 2015, с. 1249–1253.
- Guiry, van de Ven, Nelson, 2014, с. 5687–5701.
Литература
Цитаты
- Haghighat M., Abdel-Mottaleb M., Alhalabi W. Discriminant Correlation Analysis: Real-Time Feature Level Fusion for Multimodal Biometric Recognition // IEEE Transactions on Information Forensics and Security. — 2016. — Т. 11, вып. 9.
- Lawrence A. Klein. Sensor and data fusion: A tool for information assessment and decision making. — SPIE Press, 2004. — ISBN 0-8194-5435-4.
- Erik P. Blasch, Éloi Bossé, Dale A. Lambert. High-Level Information Fusion Management and System Design. — Norwood, MA: Artech House Publishers, 2012.
- Martin E. Liggins, David L. Hall, James Llinas. Multisensor Data Fusion, Second Edition: Theory and Practice (Multisensor Data Fusion). — CRC, 2008.
- Joshi V., Rajamani N., Takayuki K., Prathapaneni N., Subramaniam L. V. Information Fusion Based Learning for Frugal Traffic State Sensing // Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence. — 2013.
- Ciuonzo D., Papa G., Romano G., Salvo Rossi P., Willett P. One-Bit Decentralized Detection With a Rao Test for Multisensor Fusion // IEEE Signal Processing Letters. — 2013. — Т. 20, вып. 9. — ISSN 1070-9908. — doi:10.1109/LSP.2013.2271847. — . — arXiv:1306.6141.
- Ciuonzo D., Salvo Rossi P. Decision Fusion With Unknown Sensor Detection Probability // IEEE Signal Processing Letters. — 2014. — Т. 21, вып. 2. — ISSN 1070-9908. — doi:10.1109/LSP.2013.2295054. — . — arXiv:1312.2227.
- Ciuonzo D., De Maio A., Salvo Rossi P. A Systematic Framework for Composite Hypothesis Testing of Independent Bernoulli Trials // IEEE Signal Processing Letters. — 2015. — Т. 22, вып. 9. — ISSN 1070-9908. — doi:10.1109/LSP.2015.2395811. — .
- John J. Guiry, Pepijn van de Ven, John Nelson. Multi-Sensor Fusion for Enhanced Contextual Awareness of Everyday Activities with Ubiquitous Devices // Sensors. — 2014. — Т. 14, вып. 3. — С. 5687–5701. — doi:10.3390/s140305687. — PMID 24662406.
Источники
- Dave L. Hall, James Llinas. Introduction to Multisensor Data Fusion // Proceedings of the IEEE. — 1997. — Т. 85, № 1. — С. 6–23.
- Erik Blasch, Ivan Kadar, John Salerno, Mieczyslaw M. Kokar, Subrata Das, Gerald M. Powell, Daniel D. Corkill, Enrique H. Ruspini. Issues and Challenges in Situation Assessment (Level 2 Fusion) // Journal of Advances in Information Fusion. — 2006. — Т. 1. Архивировано 27 мая 2015 года.
- David L. Hall, Sonya A. H. McMullen. Mathematical Techniques in Multisensor Data Fusion, Second Edition. — Norwood, MA: Artech House, Inc., 2004. — ISBN 1-5805-3335-3.
- Mitchell H. B. Multi-sensor Data Fusion – An Introduction. — Berlin: Springer-Verlag, 2007.
- Das S. High-Level Data Fusion. — Norwood, MA: Artech House Publishers, 2008.
Ссылки
- Discriminant Correlation Analysis (DCA) [1]
- Sensordata Fusion, An Introduction
- International Society of Information Fusion
- Sensor Fusion for Nanopositioning
- Haghighat, Abdel-Mottaleb, Alhalabi, 2016, с. 1984-1996.