Викисловарь
Викислова́рь (англ. Wiktionary) — свободно пополняемый многофункциональный многоязычный словарь и тезаурус, основанный на вики-движке. Один из проектов фонда «Викимедиа». Изначально появился на английском языке 12 декабря 2002 года.
| Викисловарь | |
|---|---|
| англ. Wiktionary | |
| | |
 | |
| URL | wiktionary.org |
| Коммерческий | Нет |
| Тип сайта | Сетевой словарь |
| Регистрация | Необязательная |
| Язык(-и) | 170 |
| Расположение сервера | Майами |
| Владелец | Фонд Викимедиа |
| Автор | Джимми Уэйлс |
| Начало работы | 12 декабря 2002 |
| Рейтинг Alexa | |
В словаре содержатся грамматические описания, толкования и переводы слов. Кроме того, в статьях может отражаться информация об этимологии, фонетических свойствах и семантических связях слов. Таким образом, Викисловарь — попытка объединить в одном продукте грамматический, толковый, этимологический и многоязычный словари, а также тезаурус.
Данные Викисловаря активно используются при решении различных задач, связанных с машинной обработкой текста и речи.
Лексикографическая концепция
Благодаря взаимосвязи между разными языковыми разделами Wiktionary, а также между участниками словарного и других проектов «Фонда Викимедиа», участники каждого из них могут использовать концепции, инструменты и лексикографические материалы, созданные их коллегами — носителями других языков. В ходе работы над различными языковыми разделами словаря сложилась комплексная концепция универсального лексикографического ресурса, ставшая впервые возможной благодаря электронным технологиям. Концепция предполагает в конечном итоге полное, всестороннее описание всех лексических единиц всех естественных (и основных искусственных) языков, имеющих письменность. Полнота описания означает наличие сведений о фонетике, морфологии, синтаксических и семантических свойствах лексической единицы, её этимологии, сочетаемости и фразеологии. Полнота и степень последовательности реализации этой концепции может варьироваться в разных языковых разделах проекта.
В каждом языковом разделе «титульный» язык является центральным — все статьи пишутся исключительно на нём, кроме того, ставится цель дать переводы слов и других единиц этого языка на максимально возможное число других языков. Слова других языков переводятся, как правило, только на этот «титульный» язык. Так, в русском Викисловаре для русских слов даются толкования и переводы на иностранные языки, для иностранных слов вместо толкований даются переводы на русский язык.
При описании морфологии делается попытка дать максимально полную картину словоизменения, включая указание класса словоизменения. В частности, морфологические сведения по русским лексемам даются в соответствии с классификацией, предложенной А. А. Зализняком.
Для пополнения Викисловаря создан обширный список литературы, в Английском Викисловаре выработаны правила по включению термина в словарь (см. Criteria for inclusion). В отличие от русской Википедии, где приоритет при подборе материала отдаётся авторитетным источникам[Прим 1], в русском Викисловаре превалирует проведённый редактором статьи анализ словоупотребления[Прим 2].
Википедия и Викисловарь
Викисловарь не включает подробного описания фактов и энциклопедической информации. Тем не менее Викисловарь предоставляет уникальную информацию, отсутствующую в Википедии: словосочетания, поговорки, аббревиатуры, акронимы, описание ошибок правописания, упрощённые/искажённые варианты написания / произнесения слов, спорные случаи употребления, протологизмы, ономатопею, разные стили (напр., разговорный) и предметные области[2]. Таким образом, Википедия и Викисловарь дополняют друг друга.
Викисловарь сходен с Википедией в том, что (1) есть внутренние ссылки на статьи о словах внутри Викисловаря, (2) есть категории, (3) есть интервики, ссылающиеся на статьи о том же слове в иноязычном словаре[2].
Русскоязычный раздел
Динамика развития русского Викисловаря
Русский раздел Wiktionary был создан весной 2004 года. На протяжении полутора лет он практически не развивался, пополняясь бессистемно, преимущественно недоброкачественным материалом. Ситуация начала меняться в конце 2005 — начале 2006 годов.
В 2006 году был назначен первый администратор Schwallex, объём статей увеличился почти в четыре раза по сравнению с предыдущим годом, создан мощный инструментарий для описания морфологии, начала формироваться развитая система семантических категорий.
К осени 2006 года число статей в русском Викисловаре достигло 10 000; затем, благодаря созданию бота, использующего словники других разделов Wiktionary для генерации статей-болванок в русском разделе, за полтора месяца было добавлено ещё около 70 000 статей. 7 ноября 2006 года Викисловарь преодолел отметку 80 000, а 10 декабря 2006 года был взят рубеж в 100 000 статей. 17 декабря 2018 года количество статей превысило 1 000 000. Число активных участников составило порядка 230.
В отличие от ситуации с традиционными словарями полнота Викисловаря не может быть адекватно оценена по формальному показателю количества статей. Автоматический счётчик не делает различий между полупустыми болванками и по-настоящему информативными статьями, кроме того, он не учитывает внутриязыковую и межъязыковую омонимию. К примеру, словарный вход бор числится как одна статья, между тем в этой статье описано несколько омонимичных лексем русского языка, а также одноименные лексемы других языков (болгарского, татарского), — в традиционных словарях этот материал был бы оформлен и учтён в виде нескольких статей.
Сравнение с другими Викисловарями
Начиная с августа 2008 года русский Викисловарь вышел на первое место по размеру базы данных среди всех викисловарей[4]. В то же время, количество статей в русском Викисловаре не самое большое[5]. Это отчасти объясняется тем, что у проектов, в которых статей больше, чем в русском Викисловаре, статьи могут иметь в среднем меньший размер, в чём можно убедиться на сайте статистики[6].
Кроме того, русский Викисловарь по сравнению с другими разделами Wiktionary содержит большее количество вспомогательной информации, включая справочные таблицы, списки частотных слов и т. п. (в отличие от словарных статей, составляющих так называемое основное пространство имён, такая информация размещается в разделах «Приложения», «Индексы» и т. п.). Значительное количество статей в русском Викисловаре всё ещё являются болванками, сгенерированными ботами. Хотя иногда и можно встретить критику большого количества статей-болванок, такая предварительная разметка даёт много преимуществ. Во-первых, она помогает быстрее создавать статьи за счёт предварительного включения некоторой информации, типа части речи описываемого слова. Во-вторых, структура статей стандартизируется. За счёт повсеместного применения шаблонов (которые обычно сразу проставляются ботами при автоматическом создании статей) возникает возможность централизованно менять внешний вид сразу многих статей. Наличие большого количества шаблонов также помогает проводить дальнейшее автоматизированное редактирование уже созданных статей — например, автоматически проставлять перевод по заранее подготовленным словарям (так как ботам легче ориентироваться в структуре статьи, уже размеченной специализированными конструкциями, а не человеческим языком). Отличительной особенностью русского Викисловаря является проработанная концепция развития (которую можно найти на главной странице). Из-за проработанной концепции и широкого применения шаблонов, статьи в русском Викисловаре выглядят более однотипно, чем во многих других проектах (в основном одинаковы количество разделов, порядок их следования, оформление каждого раздела).
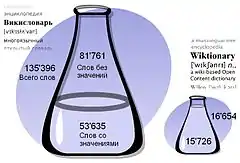
Авторами было подсчитано число словарных статей о русских словах, число статей с толкованиями и без них — в двух Викисловарях (на иллюстрации). Политика редакторов Английского Викисловаря (не создавать статей-заготовок) подтвердилась: словарных статей о русских словах без толкований всего 5,57 %. В Русском Викисловаре таких статей — 60,39 %. Однако в Русском Викисловаре (по данным на 2011 год) почти в 3.4 раза больше словарных статей с толкованиями для русских слов, чем в Английском Викисловаре: 53.6 тысячи против 15.7 тысяч[3].
Применение в NLP задачах
Для использования лексикографических данных викисловарей при решении задач автоматической обработки текста и речи — необходимо преобразовать тексты словарных статей (слабоструктурированные данные[7]) в машиночитаемый формат[8][9][10].
Извлечение данных из викисловарей является непростой задачей. Можно выделить следующие трудности[11]: (1) регулярное и частое изменение как данных, так и самой структуры статей, (2) разные викисловари имеют различную структуру и формат статей[Прим 3], (3) технология вики изначально ориентирована на удобство работы человека, а не на машинную обработку.
Существует несколько парсеров для разных викисловарей[12]:
- DBpedia Wiktionary — одно из расширений проекта DBpedia, данные извлекаются из Английского, Французского, Немецкого и Русского Викисловарей. Извлекаются: язык, часть речи, толкование, семантические отношения, переводы. Для извлечения данных используются: декларативное описание структуры словарной статьи[13], регулярные выражения[14] и FST-разновидность конечного автомата[15].
- JWKTL (Java Wiktionary Library) — API к данным Английского и Немецкого Викисловарей[16]. Извлекаются: язык, часть речи, толкование, цитаты, семантические отношения, этимология и переводы. Программа доступна для некоммерческого использования.
- wikokit — парсер Английского и Русского Викисловарей[17]. Извлекаются: язык, часть речи, толкование, цитаты[18] (только для Русского Викисловаря), семантические отношения[19] и переводы. Исходный код программы доступен на условиях открытой мультилицензии.
С помощью викисловарей решаются разнообразные задачи, связанные с обработкой текста и речи[20]:
- машинный перевод на основе правил между нидерландским и языком африкаанс; используются данные Английского и Нидерландского Викисловарей и двух википедий в рамках системы Apertium[21];
- создание машиночитаемого словаря парсером NULEX, интегрирующего открытые лингвистические ресурсы: Английский Викисловарь, WordNet и VerbNet[22]. Для существительного из Английского Викисловаря извлекались часть речи и форма множественного числа, для глаголов — время. Для извлечения данных из Викисловаря использовалась методика Screen scraping;
- распознавание и синтез речи, где Викисловарь выступает в роли источника данных для автоматического построения словаря произношений[23]. Извлекаются пары слово-произношение (транскрипция в системе МФА) из Чешского, Английского, Французского, Немецкого, Польского и Испанского Викисловарей[Прим 4]. При проверке самое большое число ошибок оказалось в транскрипциях, извлечённых из Английского Викисловаря[24];
- построение онтологий[25] и баз знаний[26];
- отображение онтологий[27];
- упрощение текста. В работе [28] выполняется оценка сложности слов на основе данных Викисловаря. Для слова из Английского Викисловаря извлекаются: размер словарной статьи, число частей речи, число значений и число переводов. Авторы[28] предположили, что более простыми, базовыми, употребимыми будут те слова, у которых больше значений (то есть размер статьи будет больше), больше частей речи и больше переводов. Далее найденные в тексте «сложные» слова необходимо перефразировать, найти более «простые» эквиваленты, что приведёт к упрощению (адаптации) текста;
- частеречная разметка. В работе (Ли и др., 2012)[29] на основе данных Английского Викисловаря построены POS-tagger’ы для восьми языков, имеющих «бедные лингвистические ресурсы», с использованием скрытых марковских моделей.[Прим 5]
- анализ тональности текста[30].
См. также
Примечания
- Комментарии
- Википедия:Авторитетные источники
Статьи в Википедии должны основываться на опубликованных авторитетных источниках.
- Викисловарь: Лексикографическая концепция
При наличии разногласий относительно каких-либо описываемых свойств какой-либо языковой единицы приоритет (с точки зрения доказательности) отдаётся корпусным источникам.
- Сравните, например, структуру и правила оформления статей в Английском Викисловаре и Русском Викисловаре.
- Если в словарной статье несколько транскрипций, то берётся первая.
- Исходный код программы и результаты частеречной разметки доступны онлайн: https://code.google.com/p/wikily-supervised-pos-tagger
- Источники
- wiktionary.org Competitive Analysis, Marketing Mix and Traffic - Alexa (англ.). Alexa Internet. — Глобальный рейтинг сайта Викисловарь. Дата обращения: 9 сентября 2017.
- Zesch et al, 2008, p. 2.
- Смирнов и др., 2012.
- Статистика викисловарей: Размер базы данных
- Статистика викисловарей
- Статистика викисловарей: Байтов на статью
- Meyer and Gurevych, 2012, p. 140.
- Zesch et al, 2008, Figure 1, p. 4.
- Meyer and Gurevych, 2010, p. 40.
- Крижановский, Преобразование, 2010, с. 1.
- Hellmann and Auer, 2013, стр. 16 в PDF, p. 302.
- Hellmann et al, 2012, Table 1, p. 3.
- Hellmann et al, 2012, pp. 8—9.
- Hellmann et al, 2012, p. 10.
- Hellmann et al, 2012, p. 11.
- Zesch et al, 2008.
- Крижановский, Преобразование, 2010.
- Крижановский, 2011.
- Крижановский, Сравнение, 2010.
- Смирнов и др., 2012, pp. 233—234.
- Otte and Tyers, 2011.
- McFate and Forbus, 2011.
- Schlippe et al., 2012.
- Schlippe et al., 2012, p. 4804.
- Meyer and Gurevych, 2012.
- ConceptNet 5. Дата обращения: 17 апреля 2013. Архивировано 19 апреля 2013 года.
- Lin and Krizhanovsky, 2011.
- Medero and Ostendorf, 2009.
- Li et al, 2012.
- Chesley et al, 2006.
Литература
- Крижановский А. Преобразование структуры словарной статьи Викисловаря в таблицы и отношения реляционной базы данных : препринт. — 2010.
- Крижановский А. Сравнение тезаурусов Русского и Английского Викисловарей, преобразованных в машиночитаемый формат : препринт. — 2010.
- Крижановский А. Оценка использования корпусов и электронных библиотек в Русском Викисловаре // Труды международной конференции «Корпусная лингвистика–2011». — СПб.: С.-Петербургский гос. университет, Филологический факультет, 2011. — С. 217—222. — 348 с. — ISBN 978-5-8465-0005-5.
- Смирнов А. В., Круглов В. М., Крижановский А. А., Луговая Н. Б., Карпов А. А., Кипяткова И. С. Количественный анализ лексики русского WordNet и викисловарей // Труды СПИИРАН. — СПб., 2012. — Т. 23. — С. 231–253.
- Chesley P., Vincent B., Li Xu, Srihari R. K. Using verbs and adjectives to automatically classify blog sentiment // Training. — 2006. — Т. 580. — С. 233—235.
- Hellmann S., Brekle J., Auer S. Leveraging the Crowdsourcing of Lexical Resources for Bootstrapping a Linguistic Data Cloud : Proc. Joint Int. Semantic Technology Conference (JIST), Dec 2-4. — Nara, Japan, 2012.
- Hellmann S., Auer S. Towards Web-Scale Collaborative Knowledge Extraction // The People’s Web Meets NLP / Gurevych, Iryna; Kim, Jungi. — Springer, 2013. — С. 287—313. — 378 с. — (Theory and Applications of Natural Language Processing). — ISBN 978-3-642-35084-9.
- Li S., Graça J. V., Taskar B. Wiki-ly supervised part-of-speech tagging : Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. — Jeju Island, Korea: Association for Computational Linguistics, 2012. — С. 1389—1398. Архивировано 22 мая 2013 года.
- Lin F., Krizhanovsky A. Multilingual ontology matching based on Wiktionary data accessible via SPARQL endpoint // Proc. of the 13th Russian Conference on Digital Libraries RCDL’2011. October 19-22, Voronezh, Russia. — 2011. — С. 19—26.
- McFate C., Forbus K. NULEX: An Open-License Broad Coverage Lexicon // The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference, 19-24 June, 2011, Portland, Oregon, USA - Short Papers. — The Association for Computer Linguistics, 2011. — С. 363—367. — ISBN 978-1-932432-88-6.
- Medero J. and Ostendorf M. Analysis of vocabulary difficulty using wiktionary // Proc. SLaTE Workshop. — 2009.
- Meyer C. M. and Gurevych I. Worth its Weight in Gold or Yet Another Resource - A Comparative Study of Wiktionary, OpenThesaurus and GermaNet : Proc. 11th International Conference on Intelligent Text Processing and Computational Linguistics,. — Iasi, Romania, 2010. — С. 38—49. Архивировано 1 декабря 2017 года.
- Meyer C. M. and Gurevych I. OntoWiktionary – Constructing an Ontology from the Collaborative Online Dictionary Wiktionary // Semi-Automatic Ontology Development: Processes and Resources / M. T. Pazienza and A. Stellato. — IGI Global, 2012. — С. 131—161. — ISBN 978-1-4666-0188-8.
- Otte P., Tyers F. M. Rapid rule-based machine translation between Dutch and Afrikaans // EAMT 2011: proc. of the 15th conference of the European Association for Machine Translation / Mikel L. Forcada, Heidi Depraetere, Vincent Vandeghinste. — Leuven, Belgium, 2011. — С. 153—160.
- Schlippe T., Ochs S., Schultz T. Grapheme-to-phoneme model generation for Indo-European languages // In Proceedings of The 37th International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2012), Kyoto, Japan, 25-30 March. — 2012. — С. 4801—4804.
- Zesch T., Müller C., Gurevych I. Extracting Lexical Semantic Knowledge from Wikipedia and Wiktionary. : Proc. of the 6th International Conference on Language Resources and Evaluation. — Marrakech, Morocco, 2008.
Ссылки
| Люди |
| |||||
|---|---|---|---|---|---|---|
| Проекты |
| |||||
| Другое |
| |||||
| Связанное |
| |||||