Slope One
Slope One — семейство алгоритмов для коллаборативной фильтрации (используемой в рекомендательных системах) для анализа различных мнений и пожеланий пользователей и выработки персональных рекомендаций.
Существует как минимум 2 класса коллаборативной фильтрации:
- фильтрация по схожести пользователей (англ. user-based filtration), базирующаяся на измерении подобия пользователей;
- фильтрация по схожести предметов (англ. item-based filtration), сравнивающая оценки, данные различными пользователями.
Slope One был представлен в статье Slope One Predictors for Online Rating-Based Collaborative Filtering Даниелем Лемайром (англ. Daniel Lemire) и Анной Маклахлан (англ. Anna Maclachlan). Утверждается, что это один из самых простых способов коллаборативной фильтрации по схожести предметов на основании оценок пользователей. Эта простота значительно облегчает внедрение данных алгоритмов, а их точность сравнима с точностью более сложных и ресурсоёмких алгоритмов[1]. Slope One также часто дополняет другие алгоритмы.[2][3].
Фильтрация по схожести предметов и переобучение
Если доступны оценки предмета - к примеру, пользователям дана возможность проголосовать за предмет (например, выставить оценку от 1 до 5), - то коллаборативная фильтрация пытается предсказать оценку, которую даст пользователь новому предмету на основании его предыдущих оценок и базы данных оценок других пользователей.
Пример: Можем ли мы предсказать оценку конкретного пользователя на новый альбом Селин Дион, если мы знаем, что он оценил The Beatles на 5 баллов?
В этом случае коллаборативная фильтрация по схожести предметов[4][5] предсказывает оценку предмета на основе оценок другого предмета, используя чаще всего регрессионный анализ (). Следовательно, если имеется 1000 предметов, то может быть до 1000000 линейных регрессий для изучения и до 2000000 регрессоров. Такой подход может быть неэффективным из-за переобучения[1], поэтому необходимо выбирать пары предметов, для которых известны оценки нескольких пользователей.

Лучшей альтернативой может быть использование упрощённого предиктора (например, ): экспериментально показано, что использование такого простого предиктора (называемого Slope One) иногда превосходит[1] регрессионный анализ, при этом имея в два раза меньше регрессоров. К тому же у этого способа низкие требования к памяти и большая скорость.

Коллаборативная фильтрация по схожести предметов — это только один вид коллаборативной фильтрации. В случае использования коллаборативной фильтрации по схожести пользователей, анализируются отношения между пользователями, выясняется подобие их интересов. Но фильтрация по схожести предметов менее ресурсоёмка и имеет бо́льшую эффективность при наличии большого числа пользователей.
Коллаборативная фильтрация по предметам на основании статистики покупок
Далеко не всегда у пользователей есть возможность выставлять оценки предметам. То есть для коллаборативной фильтрации могут быть доступны всего лишь двоичные данные (покупал пользователь предмет или нет). В таких случаях Slope One и другие алгоритмы, зависящие от оценок предметов, неэффективны.
Примером алгоритма коллаборативной фильтрации по предметам, работающего с двоичными данными, является запатентованный[6] алгоритм Item-to-Item использующийся в онлайн-магазине Amazon[7]. Этот алгоритм рассчитывает подобие предметов как косинус между векторами покупок в матрице пользователей и предметов[8]:

Этот алгоритм, возможно, даже проще чем Slope One. Рассмотрим его работу на примере:
| Покупатель | Предмет 1 | Предмет 2 | Предмет 3 |
|---|---|---|---|
| Джон | Купил | Не покупал | Купил |
| Марк | Не покупал | Купил | Купил |
| Люси | Не покупала | Купила | Не покупала |
В этом случае косинус между «Предмет 1» и «Предмет 2» рассчитывается так:
,

между «Предмет 1» и «Предмет 3»:
,

и между «Предмет 2» и «Предмет 3»:
.

Таким образом, пользователь, находящийся на странице описания «Предмета 1», получит «Предмет 3» в качестве рекомендации; на странице «Предмета 2» — «Предмет 3» и на странице «Предмета 3» — «Предмет 1» (и затем «Предмет 2»). В данном алгоритме используется один коэффициент на каждую пару предметов (косинус), на основании которого и создаются рекомендации. То есть для n предметов потребуется рассчитать и сохранить n(n-1)/2 косинусов.
Коллаборативная фильтрация Slope One для предметов с оценками
Для существенного уменьшения эффекта переобучения, увеличения производительности и облегчения внедрения было предложено семейство алгоритмов Slope One. Основное отличие от регрессионного анализа отношения рейтингов двух предметов () состоит в использовании упрощённой формы регрессии всего с одним предиктором (). Таким образом, предиктор - это просто средняя разница между оценками обоих предметов. Авторы продемонстрировали, что такой подход в некоторых случаях более точный, чем линейная регрессия[1] и требует в 2 раза меньше памяти.
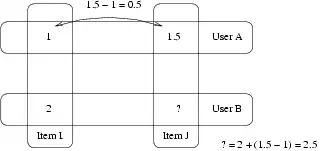
Пример:
- Джо выставил оценку 1 для Селин Дион и 1.5 для Линдси Лохан.
- Джил оценила Селин Дион на 2 балла.
- Какую оценку выставит Джил для Линдсм Лохан?
- Ответ алгоритма Slope One: 2.5 (1.5-1+2=2.5).
Рассмотрим более сложный пример:
| Посетитель | Предмет 1 | Предмет 2 | Предмет 3 |
|---|---|---|---|
| Джон | 5 | 3 | 2 |
| Марк | 3 | 4 | - |
| Люси | - | 2 | 5 |
Согласно этой таблице, средняя разница в оценках предмета 1 и 2 равна (2+(-1))/2=0.5. Таким образом, в среднем предмет 1 оценивается на 0.5 балла выше, чем предмет 2. Аналогично и для предметов 3 и 1: средняя разница в оценках 3.
Если сейчас мы попробуем предсказать оценку Люси для предмета 1, используя её оценку для предмета 2, мы получим 2+0.5 = 2.5. Аналогично предсказываем её оценку для предмета 1, используя оценку, данную предмету 3: 5+3=8. Поскольку у нас есть несколько предполагаемых оценок (Люси голосовала 2 раза), итоговую оценку мы получим как взвешенное среднее. Для весовых коэффициентов будем использовать количество пользователей, давших оценку предмету:

Чтобы применить алгоритм Slope One для заданных n предметов, надо рассчитать и сохранить среднюю разницу и количество голосов для каждой из n² пар предметов.
Оценка сложности алгоритма
Рекомендательные системы, использующие Slope One
- hitflip - система рекомендаций DVD.
- Value Investing News - новостной сайт фондовых бирж.
Программное обеспечение с открытым исходным кодом, использующее Slope One
- Пошаговая инструкция по реализации Slope One на Python.
Java:
- Taste: a java-based collaborative library with support for Enterprise Java Beans (code sample)
- класс Java, реализующий Slope One.
- The Cofi: A Java-Based Collaborative Filtering Library supports Slope One algorithms (documentation is so-so)
PHP:
- Библиотека Vogoo поддерживает алгоритмы Slope One
- Aspedia ECM API поддерживает алгоритмы Slope One
- Исходный код на PHP к отчёту об использовании алгоритмов Slope One[9]
- Модуль для Drupal CMS реализующий Slope One.
- OpenSlopeOne реализует алгоритмы Slope One на чистом PHP и MySQL.
- Philip Robinson реализовал Slope One на Erlang.
- Bryan O’Sullivan реализовал Slope One на Haskell.
- Таблица (недоступная ссылка) Microsoft Excel реализующая Slope One при помощи VBA (требуется включить макросы).
C#:
- Kuber реализовал Weighted Slope One с C#.
- Charlie Zhu реализовал Weighted Slope One на T-SQL.
Примечания
- Daniel Lemire, Anna Maclachlan, Slope One Predictors for Online Rating-Based Collaborative Filtering, In SIAM Data Mining (SDM’05), Newport Beach, California, April 21-23, 2005. (англ.)
- Pu Wang, HongWu Ye, A Personalized Recommendation Algorithm Combining Slope One Scheme and User Based Collaborative Filtering, IIS '09, 2009. (англ.)
- DeJia Zhang, An Item-based Collaborative Filtering Recommendation Algorithm Using Slope One Scheme Smoothing, ISECS '09, 2009. (англ.)
- Slobodan Vucetic, Zoran Obradovic: Collaborative Filtering Using a Regression-Based Approach. Knowl. Inf. Syst. 7(1): 1-22 (2005) (англ.)
- Badrul M. Sarwar, George Karypis, Joseph A. Konstan, John Riedl: Item-based collaborative filtering recommendation algorithms. WWW 2001: 285—295 (англ.)
- U.S. Patent 6,266,649 (недоступная ссылка с 16-01-2015 [2594 дня])
- Greg Linden, Brent Smith, Jeremy York, "Amazon.com Recommendations: Item-to-Item Collaborative Filtering, " IEEE Internet Computing, vol. 07, no. 1, pp. 76-80, Jan/Feb, 2003 (англ.)
- B.M. Sarwarm et al., "Analysis of Recommendation Algorithms for E-Commerce, " ACM Conf. Electronic Commerce, ACM Press, 2000, pp.158-167. (англ.)
- Daniel Lemire, Sean McGrath, Implementing a Rating-Based Item-to-Item Recommender System in PHP/SQL Архивировано 11 февраля 2010 года., Technical Report D-01, January 2005.