Код Хэмминга
Код Хэ́мминга — самоконтролирующийся и самокорректирующийся код. Построен применительно к двоичной системе счисления.
| Двоичный код Хэмминга | |
|---|---|
.svg.png.webp) Код Хэмминга с | |
| Назван в честь | Ричард Хэмминг |
| Тип | линейный блочный код |
| Длина блока | |
| Длина сообщения | |
| Доля | |
| Расстояние | 3 |
| Размер алфавита | 2 |
| Обозначение | |






Позволяет исправлять одиночную ошибку (ошибка в одном бите слова) и находить двойную[1].
Назван в честь американского математика Ричарда Хэмминга, предложившего код.
История
В середине 1940-х годов в лаборатории фирмы Белл (Bell Labs) была создана счётная машина Bell Model V. Это была электромеханическая машина, использующая релейные блоки, скорость которых была очень низка: одна операция за несколько секунд. Данные вводились в машину с помощью перфокарт с ненадёжными устройствами чтения, поэтому в процессе чтения часто происходили ошибки. В рабочие дни использовались специальные коды, чтобы обнаруживать и исправлять найденные ошибки, при этом оператор узнавал об ошибке по свечению лампочек, исправлял и снова запускал машину. В выходные дни, когда не было операторов, при возникновении ошибки машина автоматически выходила из программы и запускала другую.
Хэмминг часто работал в выходные дни, и все больше и больше раздражался, потому что часто должен был перезагружать свою программу из-за ненадежности считывателя перфокарт. На протяжении нескольких лет он искал эффективный алгоритм исправления ошибок. В 1950 году он опубликовал способ кодирования, который известен как код Хэмминга.
Систематические коды
Систематические коды образуют большую группу из блочных, разделимых кодов (в которых все символы слова можно разделить на проверочные и информационные). Особенностью систематических кодов является то, что проверочные символы образуются в результате линейных логических операций над информационными символами. Кроме того, любая разрешенная кодовая комбинация может быть получена в результате линейных операций над набором линейно независимых кодовых комбинаций.
Самоконтролирующиеся коды
Коды Хэмминга являются самоконтролирующимися кодами, то есть кодами, позволяющими автоматически обнаруживать ошибки при передаче данных. Для их построения достаточно приписать к каждому слову один добавочный (контрольный) двоичный разряд и выбрать цифру этого разряда так, чтобы общее количество единиц в изображении любого числа было, например, нечётным. Одиночная ошибка в каком-либо разряде передаваемого слова (в том числе, может быть, и в контрольном разряде) изменит чётность общего количества единиц. Счётчики по модулю 2, подсчитывающие количество единиц, которые содержатся среди двоичных цифр числа, дают сигнал о наличии ошибок. При этом невозможно узнать, в какой именно позиции слова произошла ошибка, и, следовательно, нет возможности исправить её. Остаются незамеченными также ошибки, возникающие одновременно в двух, четырёх, и т. д. — в чётном количестве разрядов. Предполагается, что двойные, а тем более многократные ошибки маловероятны.
Самокорректирующиеся коды
Коды, в которых возможно автоматическое исправление ошибок, называются самокорректирующимися. Для построения самокорректирующегося кода, рассчитанного на исправление одиночных ошибок, одного контрольного разряда недостаточно. Как видно из дальнейшего, количество контрольных разрядов должно быть выбрано так, чтобы удовлетворялось неравенство или , где — количество информационных двоичных разрядов кодового слова. Минимальные значения k при заданных значениях m, найденные в соответствии с этим неравенством, приведены в таблице.




| Диапазон m | kmin |
|---|---|
| 1 | 2 |
| 2-4 | 3 |
| 5-11 | 4 |
| 12-26 | 5 |
| 27-57 | 6 |
Наибольший интерес представляют двоичные блочные корректирующие коды. При использовании таких кодов информация передаётся в виде блоков одинаковой длины и каждый блок кодируется и декодируется независимо друг от друга. Почти во всех блочных кодах символы можно разделить на информационные и проверочные или контрольные. Таким образом, все слова разделяются на разрешенные (для которых соотношение информационных и проверочных символов возможно) и запрещенные.
Основными характеристиками самокорректирующихся кодов являются:
- Число разрешенных и запрещенных комбинаций. Если — число символов в блоке, — число проверочных символов в блоке, — число информационных символов, то — число возможных кодовых комбинаций, — число разрешенных кодовых комбинаций, — число запрещенных комбинаций.
- Избыточность кода. Величину называют избыточностью корректирующего кода.
- Минимальное кодовое расстояние. Минимальным кодовым расстоянием называется минимальное число искаженных символов, необходимое для перехода одной разрешенной комбинации в другую.
- Число обнаруживаемых и исправляемых ошибок. Если — количество ошибок, которое код способен исправить, то необходимо и достаточно, чтобы
- Корректирующие возможности кодов.









Граница Плоткина даёт верхнюю границу кодового расстояния:

или:
- при


Граница Хэмминга устанавливает максимально возможное число разрешенных кодовых комбинаций:

- где — число сочетаний из элементов по элементам. Отсюда можно получить выражение для оценки числа проверочных символов:



Для значений разница между границей Хэмминга и границей Плоткина невелика.

Граница Варшамова — Гилберта для больших n определяет нижнюю границу числа проверочных символов:

Все вышеперечисленные оценки дают представление о верхней границе при фиксированных и или оценку снизу числа проверочных символов.
Код Хэмминга
Построение кодов Хэмминга основано на принципе проверки на чётность числа единичных символов: к последовательности добавляется такой элемент, чтобы число единичных символов в получившейся последовательности было чётным:

Знак здесь означает сложение по модулю 2:


Если — то ошибки нет, если - то однократная ошибка.


Такой код называется или . Первое число — количество элементов последовательности, второе — количество информационных символов.


Для каждого числа проверочных символов существует классический код Хэмминга с маркировкой:

- то есть — .


При иных значениях получается так называемый усеченный код, например международный телеграфный код МТК-2, у которого . Для него необходим код Хэмминга который является усеченным от классического



Для примера рассмотрим классический код Хемминга . Сгруппируем проверочные символы следующим образом:




Получение кодового слова выглядит следующим образом:
- = .



На вход декодера поступает кодовое слово где штрихом помечены символы, которые могут исказиться в результате действия помехи. В декодере в режиме исправления ошибок строится последовательность синдромов:




называется синдромом последовательности.

Получение синдрома выглядит следующим образом:
- = .


| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |







Кодовые слова кода Хэмминга приведены в таблице.
Синдром указывает на то, что в последовательности нет искажений. Каждому ненулевому синдрому соответствует определённая конфигурация ошибок, которая исправляется на этапе декодирования.

| Синдром | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| Конфигурация ошибок | 0000001 | 0000010 | 0001000 | 0000100 | 1000000 | 0010000 | 0100000 |
| Ошибка в символе |
Для кода в таблице справа указаны ненулевые синдромы и соответствующие им конфигурации ошибок (для вида: ).
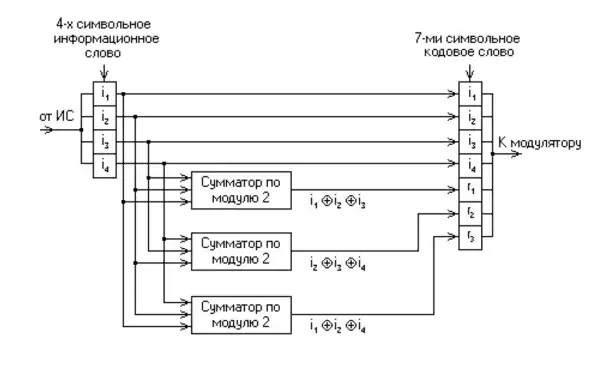
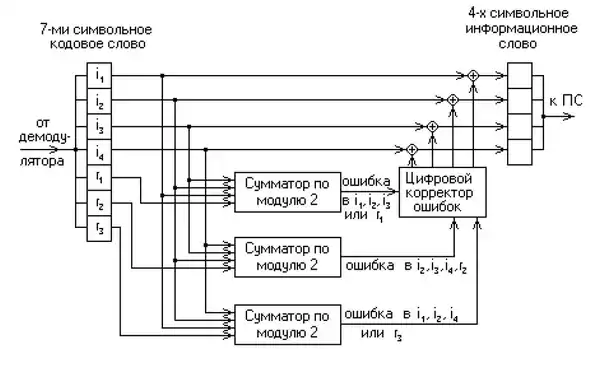
Алгоритм кодирования
Предположим, что нужно сгенерировать код Хэмминга для некоторого информационного кодового слова. В качестве примера возьмём 15-битовое кодовое слово хотя алгоритм пригоден для кодовых слов любой длины. В приведённой ниже таблице в первой строке даны номера позиций в кодовом слове, во второй — условное обозначение битов, в третьей — значения битов.

| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | x12 | x13 | x14 | x15 |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
Вставим в информационное слово контрольные биты таким образом, чтобы номера их позиций представляли собой целые степени двойки: 1, 2, 4, 8, 16… Получим 20-разрядное слово с 15 информационными и 5 контрольными битами. Первоначально контрольные биты устанавливаем равными нулю. На рисунке контрольные биты выделены розовым цветом.

| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 |
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
В общем случае количество контрольных бит в кодовом слове равно двоичному логарифму числа, на единицу большего, чем количество бит кодового слова (включая контрольные биты); логарифм округляется в большую сторону. Например, информационное слово длиной 1 бит требует двух контрольных разрядов, 2-, 3- или 4-битовое информационное слово — трёх, 5…11-битовое — четырёх, 12…26-битовое — пяти и т. д.
Добавим к таблице 5 строк (по количеству контрольных битов), в которые поместим матрицу преобразования. Каждая строка будет соответствовать одному контрольному биту (нулевой контрольный бит — верхняя строка, четвёртый — нижняя), каждый столбец — одному биту кодируемого слова. В каждом столбце матрицы преобразования поместим двоичный номер этого столбца, причём порядок следования битов будет обратный — младший бит расположим в верхней строке, старший — в нижней. Например, в третьем столбце матрицы будут стоять числа 11000, что соответствует двоичной записи числа три: 00011.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 | ||
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | r0 | |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | r1 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | r2 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | r3 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | r4 |
В правой части таблицы оставили пустым один столбец, в который поместим результаты вычислений контрольных битов. Вычисление контрольных битов производим следующим образом. Берём одну из строк матрицы преобразования (например, ) и находим её скалярное произведение с кодовым словом, то есть перемножаем соответствующие биты обеих строк и находим сумму произведений. Если сумма получилась больше единицы, находим остаток от его деления на 2. Иными словами, мы подсчитываем сколько раз в кодовом слове и соответствующей строке матрицы в одинаковых позициях стоят единицы и берём это число по модулю 2.

Если описывать этот процесс в терминах матричной алгебры, то операция представляет собой перемножение матрицы преобразования на матрицу-столбец кодового слова, в результате чего получается матрица-столбец контрольных разрядов, которые нужно взять по модулю 2.
Например, для строки :
- = (1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·1+0·1+1·1+0·0+1·0+0·0+1·0+0·1) mod 2 = 5 mod 2 = 1.
Полученные контрольные биты вставляем в кодовое слово вместо стоявших там ранее нулей. По аналогии находим проверочные биты в остальных строках. Кодирование по Хэммингу завершено. Полученное кодовое слово — 11110010001011110001.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 | ||
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | r0 | 1 |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | r1 | 1 |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | r2 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | r3 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | r4 | 1 |
Алгоритм декодирования
Алгоритм декодирования по Хэммингу абсолютно идентичен алгоритму кодирования. Матрица преобразования соответствующей размерности умножается на матрицу-столбец кодового слова, и каждый элемент полученной матрицы-столбца берётся по модулю 2. Полученная матрица-столбец получила название «матрица синдромов». Легко проверить, что кодовое слово, сформированное в соответствии с алгоритмом, описанным в предыдущем разделе, всегда даёт нулевую матрицу синдромов.
Матрица синдромов становится ненулевой, если в результате ошибки (например, при передаче слова по линии связи с шумами) один из битов исходного слова изменил своё значение. Предположим для примера, что в кодовом слове, полученном в предыдущем разделе, шестой бит изменил своё значение с нуля на единицу (на рисунке обозначено красным цветом). Тогда получим следующую матрицу синдромов.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 | ||
| 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | s0 | 0 |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | s1 | 1 |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | s2 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | s3 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | s4 | 0 |
Заметим, что при однократной ошибке матрица синдромов всегда представляет собой двоичную запись (младший разряд в верхней строке) номера позиции, в которой произошла ошибка. В приведённом примере матрица синдромов (01100) соответствует двоичному числу 00110 или десятичному 6, откуда следует, что ошибка произошла в шестом бите.
Применение
Код Хэмминга используется в некоторых прикладных программах в области хранения данных, особенно в RAID 2; кроме того, метод Хэмминга давно применяется в памяти типа ECC и позволяет «на лету» исправлять однократные и обнаруживать двукратные ошибки.
Примечания
- Коды Хемминга — "Все о Hi-Tech". all-ht.ru. Дата обращения: 20 января 2016.
Литература
- Питерсон У., Уэлдон Э. Коды, исправляющие ошибки: Пер. с англ. М.: Мир, 1976, 594 c.
- Пенин П. Е., Филиппов Л. Н. Радиотехнические системы передачи информации. М.: Радио и Связь, 1984, 256 с.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. Пер. с англ. М.: Мир, 1986, 576 с.