Алгоритм слепого индексирования
Алгоритм слепого индексирования - подраздел методов шифрования, позволяющих с помощью слепого индекса выполнять поиск по зашифрованным данным (файлам, документам и т.д.), не расшифровывая их.
Слепой индекс (англ. Blind index) - это структура данных, которая хранится вместе с набором документов и поддерживает эффективный поиск по ключевым словам. Т. е. при наличии ключевого слова индекс возвращает указатель на документы, которые содержат это ключевое слово.[1]
Происхождение
Идея индексного "ослепления" пришла Ян-Ченг Чангу и Михаэлю Митценмахеру при исследовании модели Ind-cka. Модель описывает интуитивное предположение, что злоумышленник не может получить никакой информации из индексов, кроме как результаты предыдущих запросов. Суть модели заключается в том, что если есть документ , содержащий слов, из которых штук уже знает злоумышленник, а множество оставшихся слов задается [2]. То в этом случае противник не сможет взломать оставшуюся часть документа, хоть и знает все пары индекс-документ и может получить значение односторонней функции с потайным входом всех известных ему слов. Для обеспечения такой безопасности, два зашифрованных документа одинакового размера должны иметь индексы, содержащие одинаковое количество ключевых слов. Чанг и Митценмахер расширили методы модели Ind-cka, создав собственную Ind2-ckamodel. Теперь она более безопасна, может обрабатывать слова переменной длины, но имеет ряд недостатков:





- Она вычислительно менее эффективна. Когда алгоритм построения индекса z-ind требует времени, их схема строится , где - размер словаря. (Для многих шифров )
- Неспособность обрабатывать произвольные обновления: их схемы используют предварительно построенные словари, где размер и содержание словаря фиксируются, когда словарь и индексы создаются для набора документов. Поскольку трудно предвидеть все возможные слова, которые должны быть проиндексированы, справедливо сказать, что их схемы не могут эффективно обрабатывать произвольные обновления.
- Относительно большие индексы фиксированного размера: независимо от размера документа, их индексы должны быть длиной бит. Для небольших документов их индекс может быть во много раз больше, чем документ.[3]




Общая модель применения
Изначально есть база данных , состоящая из файлов, некоторые данные . Из них извлекаются ключевые слова и шифруются под действием ключа клиента с помощью алгоритма . Часто требуется зашифровать и документ, но уже под действием ключа . В данном описании алгоритм шифровки документа обозначается . Тогда база данных примет вид:








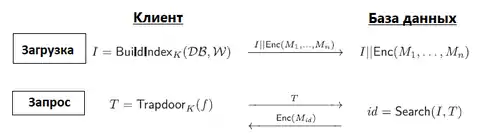
Для самого поиска клиент создает функцию одностороннюю функцию с потайным входом , где - предикат для . Используя сервер может выполнить поиск по индексу алгоритмом и вернуть клиенту те документы, в которых содержится зашифрованное слово[3].




Безопасность
Любая схема шифрования с возможностью поиска имеет утечку информации, которая делится на 3 группы: метаданных слепого индекса, шаблона поиска и шаблона доступа. Где метаданными слепого индекса называется информация о ключевых словах, содержащихся в слепом индексе. Утечка происходит из сохраненного шифротекста или слепого индекса. Эта информация может включать в себя количество ключевых слов, содержащихся в каждом документе, длину и количество документов[4]. Чтобы уменьшить вероятность утечки и увеличить криптостойкость системы, часто используется подход усеченного слепого индекса. В таком случае индекс урезается до заданного числа битов, и может быть рассмотрен в качестве фильтра Блума. Тогда вместо точного ответа на запрос, содержится ли какое-то слово в файле, клиент будет получать вероятность вхождения слова в файл. Важной особенностью этого фильтра является отсутствие ложноотрицательных срабатываний. Фильтр Блума может утверждать, что элемент является частью набора, когда он не был вставлен, но никогда не сообщит о том, что вставленный элемент отсутствует в наборе.
Но даже в таком случае возможна утечка данных. Поэтому важно знать точную формулу определения безопасной верхней границы объема информации, которая может безопасно утечь, не раскрывая повторяющиеся открытые тексты: ,

где - число слепых индексов, - длина слепого индекса (в битах), - длина ключа (в битах), - ряд зашифрованных файлов, которые используют эти слепые индексы.




Параметры должны быть подобраны так, чтобы . Если , то злоумышленник сможет сделать выводы, что некоторые тексты идентичны, что нарушает стандартное понятие безопасной схемы. В противном случае, если , то будет случаться слишком много коллизий, что сильно повлияет на производительность алгоритма.[5]



Пример (Acra Searchable Encryption)
В современном мире большинство эффективных схем SE имеют одну общую проблему. У них есть утечка шаблона поиска, который показывает, были ли выполнены 2 поисковых запроса для одного и того же ключевого слова. Подвергая себя дополнительному риску быть вскрытыми статистическим анализом (т.е. злоумышленник узнает о ключевых словах открытого текста). Acra Database Security Suite решает эту проблему, используя метод слепого индексирования. Так же для увеличения безопасности алгоритма Acra использует усечение слепого индекса, что приводит ложным срабатываниям и к коллизиям. Тогда вводится AcraServer (расположенный между клиентом и базой данных), фильтрующий нерелеватные записи из ответа, и приложение получает только соответствующие расшифрованные данные.[5]
Примечания
- Reza Curtmola, Juan Garay, Seny Kamara, Rafail Ostrovsky. Searchable symmetric encryption: Improved definitions and efficient constructions (англ.) // Journal of Computer Security. — 2011-01-01. — Vol. 19, iss. 5. — P. 895–934. — ISSN 0926-227X. — doi:10.3233/jcs-2011-0426.
- Eu-Jin Goh. Secure Indexes. — 2003. — № 216.
- Christoph Bösch, Pieter Hartel, Willem Jonker, Andreas Peter. A Survey of Provably Secure Searchable Encryption // ACM Computing Surveys. — 2014/08. — Т. 47, вып. 2. — P. 1-51. — ISSN 0360-0300. — doi:10.1145/2636328.
- Атака на блочный шифр // Википедия. — 2019-10-19.
- Eugene Pilyankevich, Dmytro Kornieiev, Artem Storozhuk. Proxy-Mediated Searchable Encryption in SQL Databases Using Blind Indexes. — 2019. — № 806.