Алгоритм Хопкрофта — Карпа
Алгоритм Хопкрофта — Карпа — алгоритм, принимающий на вход двудольный граф и возвращающий максимальное по мощности паросочетание, то есть наибольшее множество рёбер, таких что никакие два не имеют общую вершину. Асимптотика времени работы алгоритма составляет в худшем случае (здесь — множество рёбер графа, а — множество его вершин). В случае плотных графов время работы ограничивается , а для случайного графа алгоритм работает почти за линейное время.




| Алгоритм Хопкрофта — Карпа | |
|---|---|
| Назван в честь | Джон Хопкрофт и Ричард Мэннинг Карп |
| Автор | Джон Хопкрофт, Ричард Мэннинг Карп и Alexander V. Karzanov[d] |
| Предназначение | Поиск максимального паросочетания |
| Структура данных | Граф |
| Худшее время | |
| Затраты памяти | |


Алгоритм был создан Джоном Хопкрофтом и Ричардом Карпом в 1973 году[1]. Как и ранее созданные алгоритмы (такие как венгерский алгоритм и алгоритм из работы Эдмондса[2], алгоритм Хопкрофта — Карпа в цикле увеличивает паросочетание, находя увеличивающие пути (цепи, рёбра которых попеременно принадлежат паросочетанию и не принадлежат ему, причём первая и последняя вершина не принадлежат паросочетанию; выполнив чередование паросочетания вдоль цепи, то есть убрав из паросочетания рёбра, бывшие в цепи, и добавив те, которых в нём не было, можно получить большее паросочетание). Вместо того чтобы находить один увеличивающий путь, алгоритм находит максимальное множество кратчайших увеличивающих путей. В результате требуется лишь итераций. Та же идея используется в более сложных алгоритмах для поиска паросочетаний в недвудольных графах с тем же асимптотическим временем работы, как у алгоритма Хопкрофта — Карпа.

Описание задачи
Задачу поиска наибольшего паросочетания в двудольном графе неформально можно описать следующим образом. Имеется группа мальчиков и девочек. Некоторые мальчики знакомы с некоторыми девочками. Требуется составить как можно больше пар для танца, состоящих из мальчика и девочки, знакомых друг с другом[3].
Увеличивающие пути
Вершина, которая не является концом какого-либо ребра паросочетания , называется свободной вершиной (для этого паросочетания). Алгоритм основан на понятии увеличивающего пути — пути, который начинается и заканчивается в свободной вершине, а внутри пути ребра, принадлежащие и не принадлежащие паросочетанию , чередуются. Из определения следует, что все вершины такого пути, кроме первой и последней, обязаны быть несвободными. Увеличивающий путь может состоять из двух свободных вершин и одного ребра между ними (которое не лежит в паросочетании).

Если — паросочетание и — увеличивающий путь в , то симметрическая разность двух множеств рёбер является паросочетанием размера . Таким образом, найдя увеличивающие пути, можно увеличить размер паросочетания.



Наоборот, пусть не оптимально и пусть есть симметрическая разность , где — оптимальное паросочетание. Поскольку и — паросочетания, каждая вершина в имеет степень не более двух. Значит, должно образовывать множество непересекающихся увеличивающих путей и циклов или путей, в которых рёбер из паросочетания столько же, сколько и не из него. Разность размеров и и есть число увеличивающих путей в . Итак, если существует паросочетание , большее текущего паросочетания , также должен существовать увеличивающий путь. Если увеличивающего пути не существует, можно успешно прервать алгоритм, так как должно быть оптимальным[4].


Увеличивающие пути в задачах о паросочетаниях тесно связаны с увеличивающими путями, возникающими в задачах о максимальном потоке, путями, вдоль которых можно увеличить поток между истоком и стоком. Можно свести задачу о поиске наибольшего паросочетания к задаче поиска максимального потока[5]. Технику, используемую в алгоритме Хопкрофта — Карпа, можно обобщить для произвольной транспортной сети, что приведёт к алгоритму Диница[6].
Алгоритм
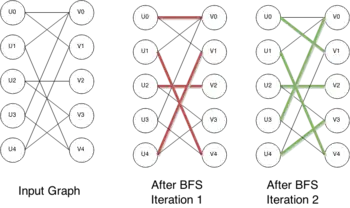
Ниже представлена структура алгоритма:
- Вход: Двудольный граф
- Выход: Паросочетание
- цикл
- максимальное множество непересекающихся по вершинам кратчайших увеличивающих путей
- пока






Более подробно, пусть даны и — множества вершин двудольного графа , а — множество его рёбер, соединяющих вершины из и . Алгоритм, начиная с пустого паросочетания , последовательно его увеличивает. На каждой фазе алгоритм делает следующее:


- Поиск в ширину (BFS) разбивает вершины графа на слои. BFS начинает с множества свободных вершин , которые тем самым образуют первый слой разбиения (таким образом, первый слой содержит только не покрытые паросочетанием рёбра). На последующих уровнях поиска алгоритм добавляет вершины на новый уровень, чередуя рёбра: будет попеременно добавлять вершины, связанные ребром то в паросочетании, то вне его, поэтому в процессе поиска из вершины из мы всегда будем проходить по рёбрам не из паросочетания, а если вершина из — то наоборот. Поиск прерывается на уровне , как только впервые будет достигнута хотя бы одна свободная вершина из .
- Все свободные вершины из на этом слое обозначим как . Получается, вершина принадлежит тогда и только тогда, когда в ней кончается кратчайший удлиняющий путь.
- Алгоритм находит максимальное множество непересекающихся по вершинам путей длины . Это множество может быть найдено поиском в глубину (DFS), который использует найденное ранее разбиение на слои. Поиск может проходить лишь по рёбрам, которые ведут в неиспользованные вершины предыдущего слоя, и путь в дереве поиска в глубину должен чередоваться относительно паросочетания . Как только увеличивающий путь войдёт в одну из вершин , следует начать DFS от следующей вершины.
- Каждый из путей, который будет найден, используется для увеличения .



Алгоритм прерывается, когда на какой-либо фазе BFS не находит ни одного увеличивающего пути (то есть пусто).
Анализ
Каждая фаза состоит из одного BFS и одного DFS, поэтому одна фаза выполняется за . Следовательно, первые фаз в графе с вершинами и рёбрами имеют стоимость . Можно показать, что каждая фаза увеличивает длину кратчайшего удлиняющего пути, по крайней мере, на 1: фаза находит максимальный набор дополняющих путей данной длины, так что любой оставшийся путь должен быть длиннее. Следовательно, после того как первые фаз алгоритма завершились, кратчайший оставшийся увеличивающий путь имеет длину, по крайней мере, . Однако симметрическая разность оптимального паросочетания и текущего паросочетания , найденного в предыдущих фазах, образует множество вершинно непересекающихся увеличивающих путей и чередующихся циклов. Если каждый путь имеет длину, по крайней мере, , может быть не более чем путей, и размер оптимального паросочетания может отличаться от размера не более чем на . Так как каждая фаза алгоритма увеличивает размер паросочетания, по крайней мере, на 1, ещё может произойти не более фаз.




Так как в худшем случае алгоритм имеет фаз, общее время работы составляет в худшем случае[1].

Однако во многих случаях алгоритм может быть гораздо быстрее, чем говорит оценка в худшем случае. Например, в случае разреженного двудольного случайного графа в 2006 году было показано[7] (улучшая предыдущий результат[8]), что с большой вероятностью все неоптимальные паросочетания имеют увеличивающие пути логарифмической длины. Как следствие, для таких графов количество итераций , а время работы алгоритма составляет .


Сравнение с другими алгоритмами поиска максимального паросочетания
Для разреженных графов алгоритм Хопкрофта — Карпа имеет наилучшую асимптотику в худшем случае из всех известных алгоритмов, но для плотных графов более новый алгоритм[9] имеет слегка лучшую границу . Этот алгоритм базируется на алгоритме проталкивания предпотока, а, когда паросочетание становится близко к оптимальному, переключается на метод Хопкрофта — Карпа.

Несколько авторов провели экспериментальное сравнение алгоритмов поиска максимального паросочетания. Их результаты показали, что в общем случае алгоритм Хопкрофта — Карпа на практике не так хорош, как в теории: его превосходят по производительности как простые BFS и DFS-стратегии по поиску увеличивающего пути, так и алгоритмы, основанные на методе проталкивания предпотока[10].
Недвудольные графы
Та же идея поиска максимального множества кратчайших увеличивающих путей также работает для нахождения паросочетаний максимальной мощности в недвудольных графах, и по тем же причинам алгоритм будет иметь не более фаз. Однако для недвудольных графов поиск удлиняющих путей в каждой фазе более сложен. Базируясь на более ранних работах, Micali & Vazirani (1980) показали, как выполнять фазу за линейное время, что привело к созданию алгоритма с той же верхней оценкой, что и у алгоритма Хопкрофта — Карпа для двудольных графов. Метод Micali — Vazirani сложен, и авторы не предоставили полных доказательств своих результатов; впоследствии Peterson & Loui (1988) опубликовали полное обоснование алгоритма Micali — Vazirani, а также были опубликованы другие алгоритмы: Gabow & Tarjan (1991) и Blum (2001). В 2012 году Vazirani предложил новое, упрощённое доказательство алгоритма Micali — Vazirani[11].
Псевдокод
Ниже приведён псевдокод алгоритма, близкий к реализации на Java[12].
/*
G = U ∪ V ∪ {NIL}
where U and V are partition of graph and NIL is a special null vertex
*/
function BFS ()
for u in U
if Pair_U[u] == NIL
Dist[u] = 0
Enqueue(Q,u)
else
Dist[u] = ∞
Dist[NIL] = ∞
while Empty(Q) == false
u = Dequeue(Q)
if Dist[u] < Dist[NIL]
for each v in Adj[u]
if Dist[ Pair_V[v] ] == ∞
Dist[ Pair_V[v] ] = Dist[u] + 1
Enqueue(Q,Pair_V[v])
return Dist[NIL] != ∞
function DFS (u)
if u != NIL
for each v in Adj[u]
if Dist[ Pair_V[v] ] == Dist[u] + 1
if DFS(Pair_V[v]) == true
Pair_V[v] = u
Pair_U[u] = v
return true
Dist[u] = ∞
return false
return true
function Hopcroft-Karp
for each u in U
Pair_U[u] = NIL
for each v in V
Pair_V[v] = NIL
matching = 0
while BFS() == true
for each u in U
if Pair_U[u] == NIL
if DFS(u) == true
matching = matching + 1
return matching
Пояснения
Пусть граф состоит из долей U и V. Ключевая идея состоит в добавлении двух фиктивных вершин с каждой стороны графа: uDummy, соединённую со всеми непокрытыми вершинами из U, и vDummy, соединённую со всеми непокрытыми вершинами из V. Теперь, если мы запустим BFS из uDummy в vDummy, мы получим кратчайший путь между непокрытой вершиной из U и непокрытой вершиной из V. Из-за двудольности графа путь будет чередоваться между U и V. Однако нужно удостовериться, что, идя из V в U, мы всегда выбираем ребро из паросочетания. Если не осталось вершин из паросочетания, то мы заканчиваем в vDummy. Руководствуясь этим критерием в процессе BFS, в конце получим кратчайший увеличивающий путь.
После того, как кратчайший увеличивающий путь будет найден, надо игнорировать все пути, которые длиннее его. BFS помечает вершины, расстояние от которых до истока 0. После выполнения BFS мы можем, стартуя из каждой вершины из U, не лежащей в паросочетании, идя по пути, в котором расстояние до следующей вершины больше расстояния до предыдущей на 1. Если мы в конце приходим в vDummy, расстояние до которой на 1 больше, чем расстояние до одной из вершин из V, по которой можно дойти по одному из кратчайших путей. В таком случае мы можем пойти дальше и обновить паросочетание для вершин на пути. Заметим, что каждая вершина V на пути, кроме самой последней, уже в паросочетании. Поэтому обновление паросочетания эквивалентно симметрической разности (то есть удалению тех рёбер пути, которые были в паросочетании, и добавлению тех, которых не было.
Как удостовериться, что увеличивающие пути не пересекаются по вершинам? Это уже обеспечено. После выполнения симметрической разности никакая из вершин пути не будет рассмотрена ещё раз, потому что Dist[ Pair_V[v] ] не будет равна Dist[u] + 1 (а будет в точности Dist[u]).
Зачем нужны следующие строчки?
Dist[u] = ∞ return false
Когда мы не можем найти никакой кратчайший увеличивающий путь из вершины u, DFS возвращает False. В этом случае, будет хорошо пометить эти вершины, чтобы не посещать их ещё раз. Чтобы отметить их, мы просто выставляем Dist[u] бесконечным.
Нам не нужен uDummy, потому что он лишь для того, чтобы складывать все вершины не из паросочетания в очередь BFS. Это можно сделать просто инициализацией. vDummy можно добавить в U для удобства во многих реализациях, и инициализировать паросочетание для всех вершин из V указателем на vDummy. Поэтому если в конце концов последняя вершина из U не находится в паросочетании ни с одной вершиной из V, то последней вершиной нашего удлиняющего пути будет vDummy. В псевдокоде выше vDummy обозначается Nil.
Примечания
- Hopcroft & Karp (1973)
- Edmonds (1965)
- Алгоритмы поиска максимального паросочетания в двудольном графе.
- Edmonds, 1965, p. 453.
- Ahuja, Magnanti & Orlin (1993), section 12.3, bipartite cardinality matching problem, pp. 469—470.
- Yefim Dinitz. Dinitz' Algorithm: The Original Version and Even's Version // Theoretical Computer Science: Essays in Memory of Shimon Even (англ.) / ed. Oded Goldreich, Arnold L. Rosenberg, and Alan L. Selman. — Springer, 2006. — P. 218—240. — ISBN 978-3540328803.
- Bast et al. (2006)
- Motwani (1994)
- Alt et al. (1991)
- Chang & McCormick (1990); Darby-Dowman (1980); Setubal (1993); Setubal (1996).
- Vazirani (2012)
- Java Program to Implement Hopcroft Algorithm - Sanfoundry (англ.), Sanfoundry (20 November 2013). Дата обращения 6 апреля 2017.
Литература
- Ahuja, Ravindra K.; Magnanti, Thomas L. & Orlin, James B. (1993), Network Flows: Theory, Algorithms and Applications, Prentice-Hall.
- Alt, H.; Blum, N.; Mehlhorn, K. & Paul, M. (1991), Computing a maximum cardinality matching in a bipartite graph in time , Information Processing Letters Т. 37 (4): 237–240, DOI 10.1016/0020-0190(91)90195-N.
- Bast, Holger; Mehlhorn, Kurt; Schafer, Guido & Tamaki, Hisao (2006), Matching algorithms are fast in sparse random graphs, Theory of Computing Systems Т. 39 (1): 3–14, DOI 10.1007/s00224-005-1254-y.
- Blum, Norbert (2001), A Simplified Realization of the Hopcroft-Karp Approach to Maximum Matching in General Graphs, Tech. Rep. 85232-CS, Computer Science Department, Univ. of Bonn, <http://theory.cs.uni-bonn.de/ftp/reports/cs-reports/2001/85232-CS.ps.gz>.
- Chang, S. Frank & McCormick, S. Thomas (1990), A faster implementation of a bipartite cardinality matching algorithm, Tech. Rep. 90-MSC-005, Faculty of Commerce and Business Administration, Univ. of British Columbia. As cited by Setubal (1996).
- Darby-Dowman, Kenneth (1980), The exploitation of sparsity in large scale linear programming problems – Data structures and restructuring algorithms, Ph.D. thesis, Brunel University. As cited by Setubal (1996).
- Edmonds, Jack (1965), Paths, Trees and Flowers, Canadian J. Math Т. 17: 449–467, DOI 10.4153/CJM-1965-045-4.
- Gabow, Harold N. & Tarjan, Robert E. (1991), Faster scaling algorithms for general graph matching problems, Journal of the ACM Т. 38 (4): 815–853, DOI 10.1145/115234.115366.
- Hopcroft, John E. & Karp, Richard M. (1973), An n5/2 algorithm for maximum matchings in bipartite graphs, SIAM Journal on Computing Т. 2 (4): 225–231, DOI 10.1137/0202019.
- Micali, S. & Vazirani, V. V. (1980), An algorithm for finding maximum matching in general graphs, Proc. 21st IEEE Symp. Foundations of Computer Science, с. 17–27, DOI 10.1109/SFCS.1980.12.
- Peterson, Paul A. & Loui, Michael C. (1988), The general maximum matching algorithm of Micali and Vazirani, Algorithmica Т. 3 (1-4): 511–533, DOI 10.1007/BF01762129.
- Motwani, Rajeev (1994), Average-case analysis of algorithms for matchings and related problems, Journal of the ACM Т. 41 (6): 1329–1356, DOI 10.1145/195613.195663.
- Setubal, João C. (1993), New experimental results for bipartite matching, Proc. Netflow93, Dept. of Informatics, Univ. of Pisa, с. 211–216. As cited by Setubal (1996).
- Setubal, João C. (1996), Sequential and parallel experimental results with bipartite matching algorithms, Tech. Rep. IC-96-09, Inst. of Computing, Univ. of Campinas, <http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.48.3539>.
- Vazirani, Vijay (2012), An Improved Definition of Blossoms and a Simpler Proof of the MV Matching Algorithm, CoRR abs/1210.4594.

